







隐语义模型与推荐算法
标签:推荐算法
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型。
这种方法,先对所有的物品进行分类,再根据用户的兴趣分类给用户推荐该分类中的物品,LFM就是用来实现这种方法。
如果要实现这种方法,需要解决以下的问题:
(1)给物品分类
(2)确定用户兴趣属于哪些类及感兴趣程度
(3)对于用户感兴趣的类,如何推荐物品给用户
对分类,很容易想到人工对物品进行分类,但是人工分类是一种很主观的事情,比如一部电影用户可能因为这是喜剧片去看了,但也可能因为他是周星驰主演的看了,也有可能因为这是一部属于西游类型的电影,不同的人可以得到不同的分类。
而且对于物品分类的粒度很难控制,究竟需要把物品细分到个程度,比如一本线性代数,可以分类到数学中,也可以分类到高等数学,甚至根据线性代数主要适用的领域再一次细分,但对于非专业领域的人来说,想要对这样的物品进行小粒度细分无疑是一件费力不讨好的事情。
而且一个物品属于某个类,但是这个物品相比其他物品,是否更加符合这个类呢?这也是很难人工确定的事情。
对于上述需要解决的问题,我们的隐语义模型就派上用场了。隐语义模型,可以基于用户的行为自动进行聚类,并且这个类的数量,即粒度完全由可控。
对于某个物品是否属与一个类,完全由用户的行为确定,我们假设两个物品同时被许多用户喜欢,那么这两个物品就有很大的几率属于同一个类。
而某个物品在类所占的权重,也完全可以由计算得出。
以下公式便是隐语义模型计算用户u对物品i兴趣的公式(F为分类)
(这里参考一下大佬的作品,这里他解释的很好)
R矩阵是user-item矩阵,矩阵值Rij表示的是user i 对item j的兴趣度,这正是我们要求的值。对于一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。所以LFM根据如下公式来计算用户U对物品I的兴趣度
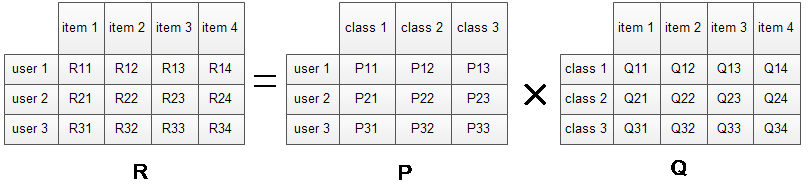
其中,p为用户u兴趣和第k个隐类的关系,q为第k个隐类和物品i的关系,F为隐类的数量,r便是用户对物品的兴趣度。
接下的问题便是如何计算这两个参数p和q了,对于这种线性模型的计算方法,这里使用的是梯度下降法,详细的推导过程可以看一下我的另一篇博客。大概的思路便是使用一个数据集,包括用户喜欢的物品和不喜欢的物品,根据这个数据集来计算p和q。
下面给出公式,对于正样本,我们规定r=1,负样本r=0:
其中 λ λ 是为了防止过拟合
下面我们来谈谈实现:
1. U-I,即用户和物品集的获取(也就是最后比较的 R(u,i) R ( u , i ) )
对负样本采样时应该遵循以下原则:
1.对每个用户,要保证正负样本的平衡(数目相似)。
2.对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
一般认为,很热门而用户却没有行为更加代表用户对这个物品不感兴趣。因为对于冷门的物品,用户可能是压根没在网站中发现这个物品,所以谈不上是否感兴趣。
def RandomSelectNegativeSample(self , items , items_pool):
#items是一个dict,它包含了用户已经有过行为的物品的集合
#items_pool维护了候选物品的列表
#在这个列表中,物品i出现的次数和物品i的流行度成正比
temp = dict()
for i in items.keys():
temp[i] = 1
n = 0
#将范围上限设为len(items) * 3,主要是为保证正、负样本数量接近。
for i in range(0, len(items) * 3):
item = items_pool[random.randint(0, len(items_pool) - 1)]
if item in temp:
continue
temp[item] = 0
n += 1
if n > len(items):
break
return temp2. pu,k p u , k 以及 qi,k q i , k 的获取
用梯度下降:
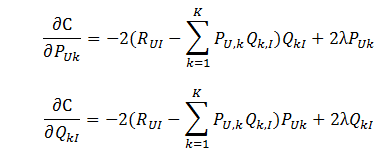
然后可以迭代计算:
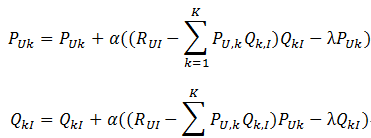
另外,p和q是随机初始化,但是他们的维度的确定方式,还待我看看论文。。。















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









