









 本文详细解析了Linux中不同架构下,如X86、RISC-V、MIPS和Xtensa,堆栈切换和页目录管理的逻辑,特别关注context_switch中的mm_struct处理,以及在初始化、系统BRINGUP和进程创建过程中的调度细节。
本文详细解析了Linux中不同架构下,如X86、RISC-V、MIPS和Xtensa,堆栈切换和页目录管理的逻辑,特别关注context_switch中的mm_struct处理,以及在初始化、系统BRINGUP和进程创建过程中的调度细节。
Linux页目录存放在 struct mm_struct字段中,通过current->mm->pgd访问。下面分析不同架构下堆栈切换逻辑。
X86
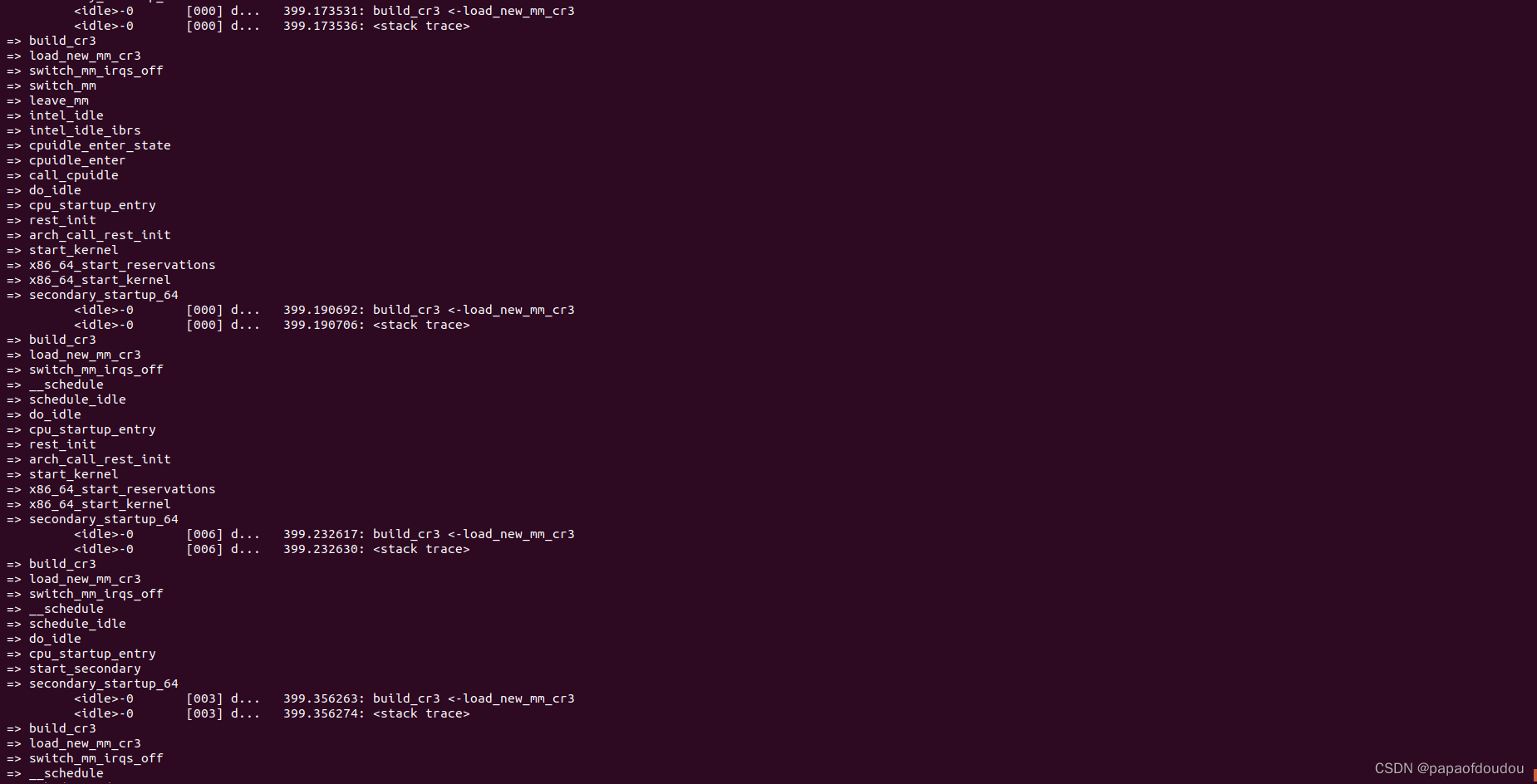
X86页表切换堆栈, 可以看到上下文主要有三个,第一个是普通调度的时候,调度目标是用户态任务时切换CR3,另一个是执行fork后执行execve系统调用过程中通过加载器创建的MM的切换,最后一个是在idle任务中执行leave_mm将映射切换回到init_mm内核空间中(lazy tlb)。


Paging初始化
paging初始化注意第六条:

paging enable 指令和后续的长跳转指令必须要保证在一个恒等映射的页面的,也就是这个页面的VA=PA,解决虚拟地址和物理地址鸡和蛋的循环依赖问题。

分析context_switch实现可以看到,切换页表的关键函数switch_mm_irqs_off只有在目标任务是用户态任务的时候才会执行到,如果切换的目标任务是内核任务,则不执行切换页表的操作,而是复用前一个进程的mm_struct(如果源是用户进程,所以要mmgrab(prev->mm),如果源任务为内核线程,则一定能够追溯到一个用户进程的MM).
系统BRINGUP时,大概的执行路径是这样的,在1号进程还没有转变为用户态进程之前(EXECVE执行INIT),它还是个内核线程,这个时候可能2号进程已经产生,它们之间进行的是 kernel->kernel之间的调度。当1号进程完成加在镜像,创建了新的MM对象,变成了用户态进程,这个时候第一次涉及用户态的调度是user->kernel,总之rq->prev_mm是不会指向init_mm的,否则 finish_task_switch中会对init_mm进行DROP,init_mm是静态分配的,不应该被mmdrop,否则会出错。
经过实际测试,即使将.mm_users从2修改为1,也不会造成问题。看起来mmdrop确实不会碰触init_mm.

RISCV:
RISCV架构比较直接,直接在switch_mm就把切换页目录的事情给干了。写到对应的寄存器SATP中。
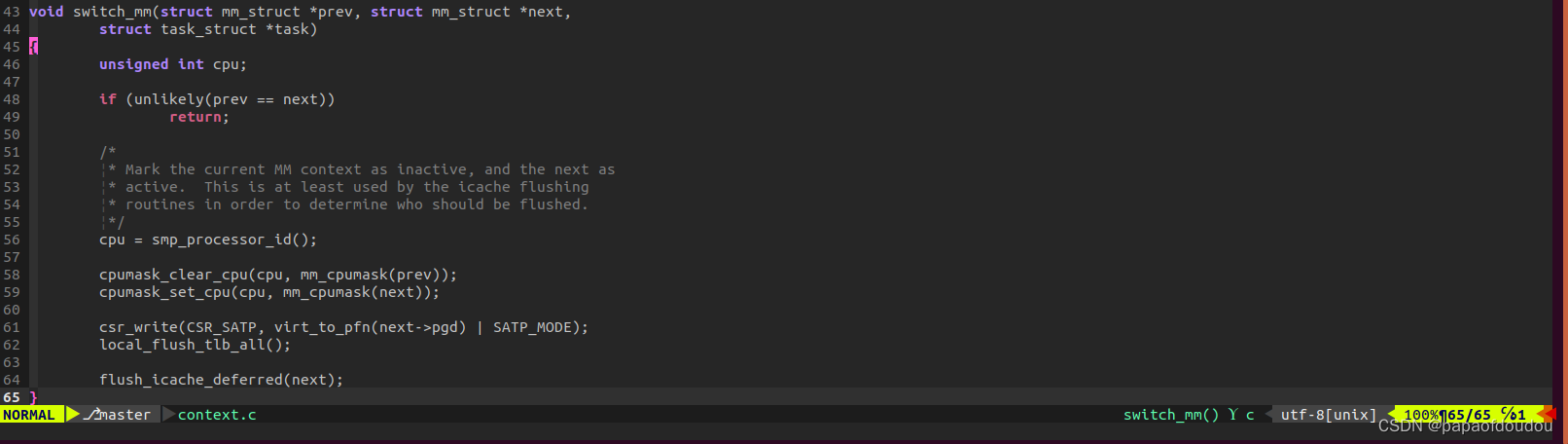
可以看到,mm->pgd是虚拟地址,需要经过virt_to_pfn(next->pgd)转换为物理地址。切换页表后,需要使TLB无效,通过调用local_flush_tlb_all函数实现, 底层实现调用“sfence.vma"指令,可以参考下篇博客的解释:
https://zhuanlan.zhihu.com/p/695045587

MIPS:
MIPS Linux内核编译构建环境的搭建_mips编译器_papaofdoudou的博客-CSDN博客
MIPS由于是软件重填TLB,PAGE WALK发生在TLB中,但是软件重填将查询页表的控制权交给了软件,所以硬件也就不需要知道PGD放在哪里,所以PGD的物理地址对其不必要,导致大部分早期MIPS架构没有对应寄存器保存PGD,但是最新的貌似支持了。
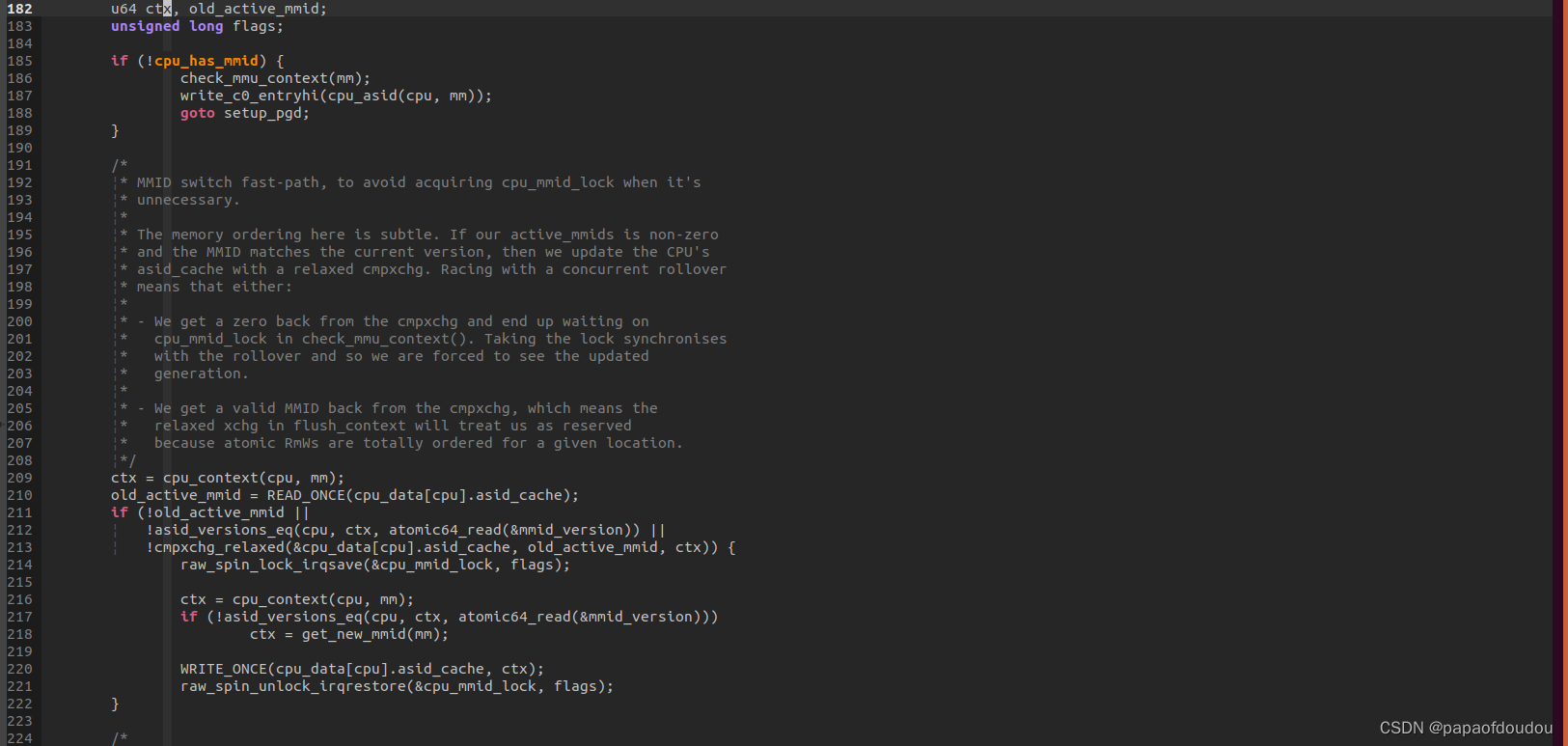
Xtensa
Xtensa架构没有专门的系统寄存器存储PGD,而是通过TLB 重填机制实现的LINUX分页支持。这一点有点类似早期的MIPS架构。
进程创建后分配PGD页的时候,仅仅是分配了一个0页面,没有对PGD的内核页部分作初始化,所有其它有用户态的进程都会对PGD的内核页目录映射部分做初始化的,比如NIOS2

64/32位Linux系统的差异(地址空间布局,系统调用)对比分析-CSDN博客
而XTENSA架构仅仅分配了一个PAGE,并初始化为0就结束了。

所以在xtensa架构的switch_mm实现中,没有访问PGD的操作,仅仅是更新的ASID。
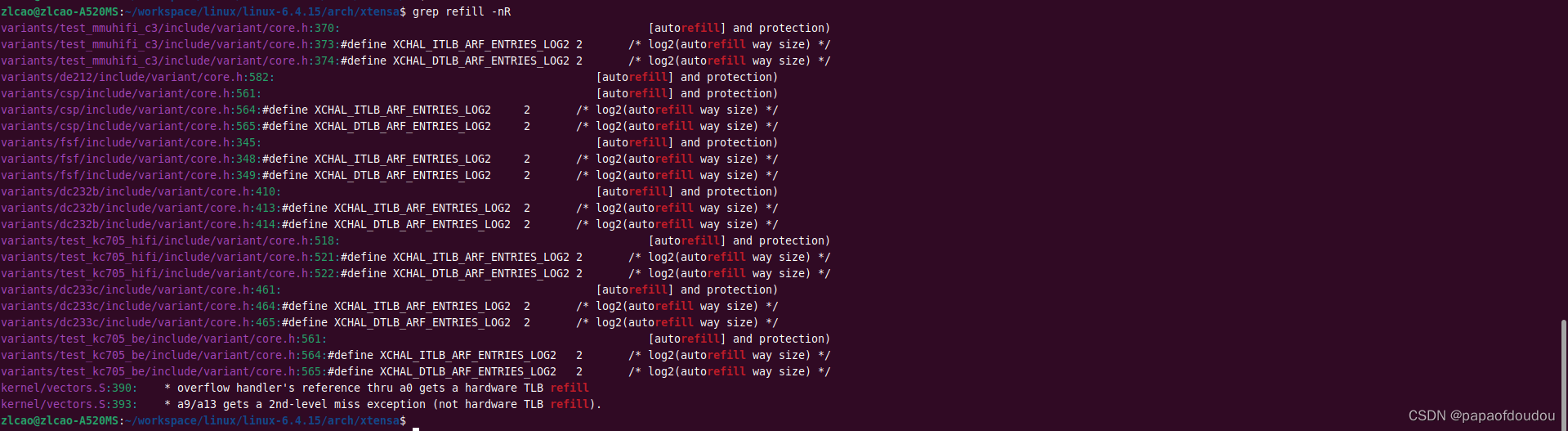
TLB REFILL异常注册在异常表中:

Linux进程调度的通用逻辑
调度的本质就是选择下一个进程,然后切换。用函数 pick_next_task 选择下一个进程,其本质就是调度算法的实现,用函数 context_switch 完成进程的切换,即进程上下文的切换。
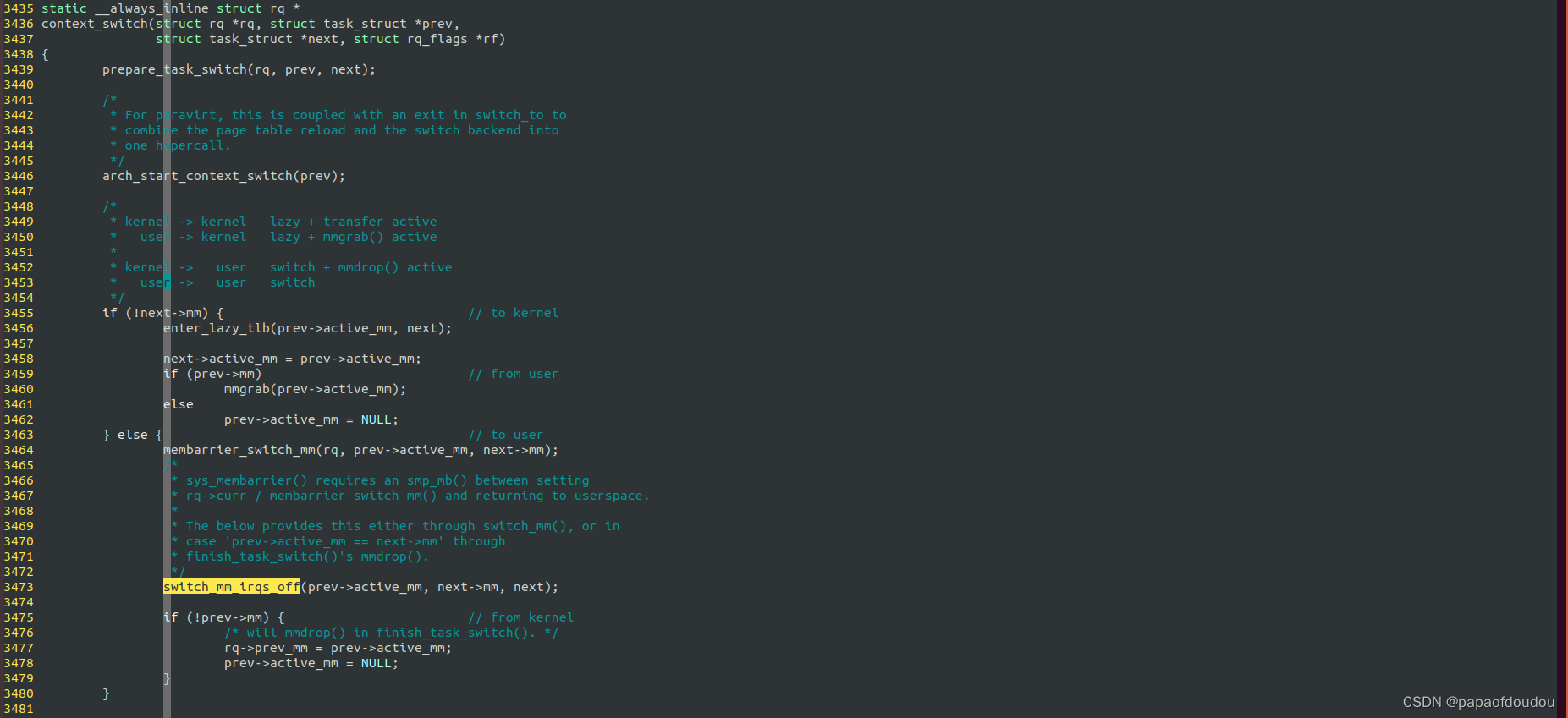
context_switch是进程上下文切换的主体,这个函数prev是当前进程的task_struct指针,而next是新进程的task_struct指针,它的工作就是存当前进程上下文,恢复新进程的上下文,同时要设置新进程的页目录,而进程的页目录地质保存在struct mm_struct结构中,如果新进程是一个内核态进程,它没有struct mm_struct结构(struct task_struct->mm/struct task_struct->active_mm都为空),这时就要借用前一个进程的mm_struct结构,使用它的页表作为新进程的页表,由于内核态进程只访问内核态地质空间,而内核态地质空间是所有进程共享的,因此能够保证一致。
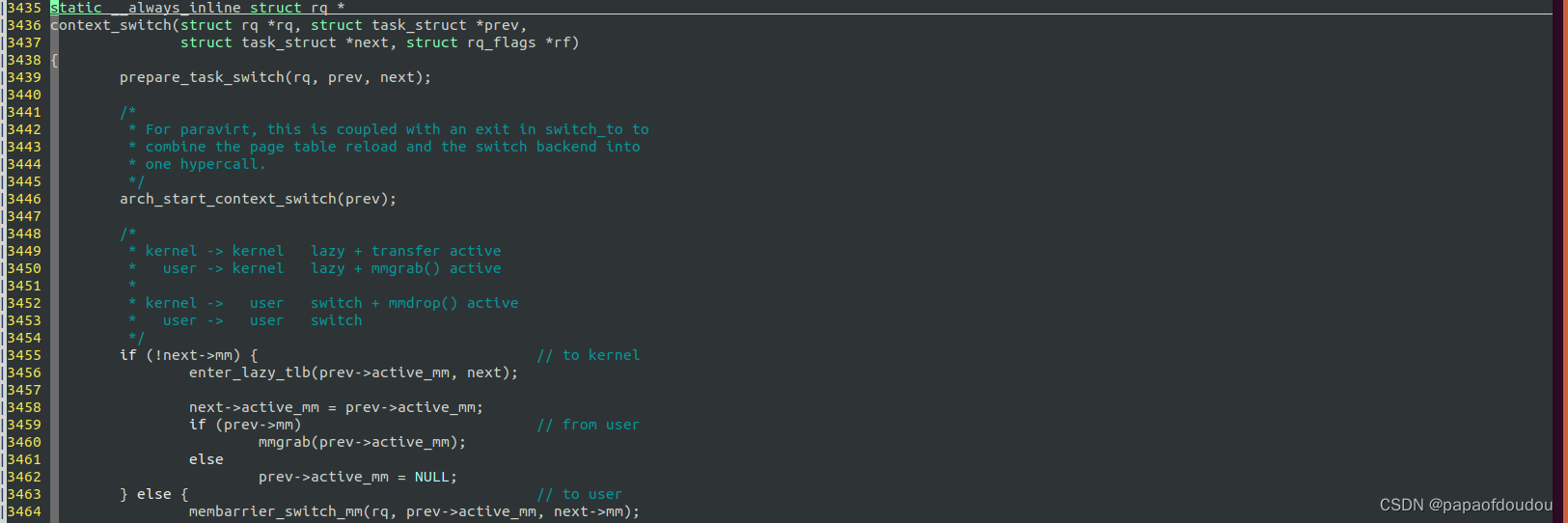
内核线程在调度过程中,可能会出现struct task_struct->mm/struct task_struct->active_mm全部为空的情况,就是当这个内核线程调度目标是下一个内核线程 的时候,前一个内核线程会将自己借用的active_mm传递给下一个active_mm,然后将前一个的active_mm置为NULL,这样,前一个内核线程的active_mm和mm全部为NULL。

具体实现进程上下文切换的工作由switch_to完成,但是在执行switch_to之前,在第3473行就调用switch_mm_irqs_off切换到了新进程的的地址空间.因为内核态地址空间是由所有进程共享的,所以这不会有问题。注意,这里还没有切换内核堆栈。RTOS下不需要切换MM,接下来的动作才可以参考RTOS的行为。
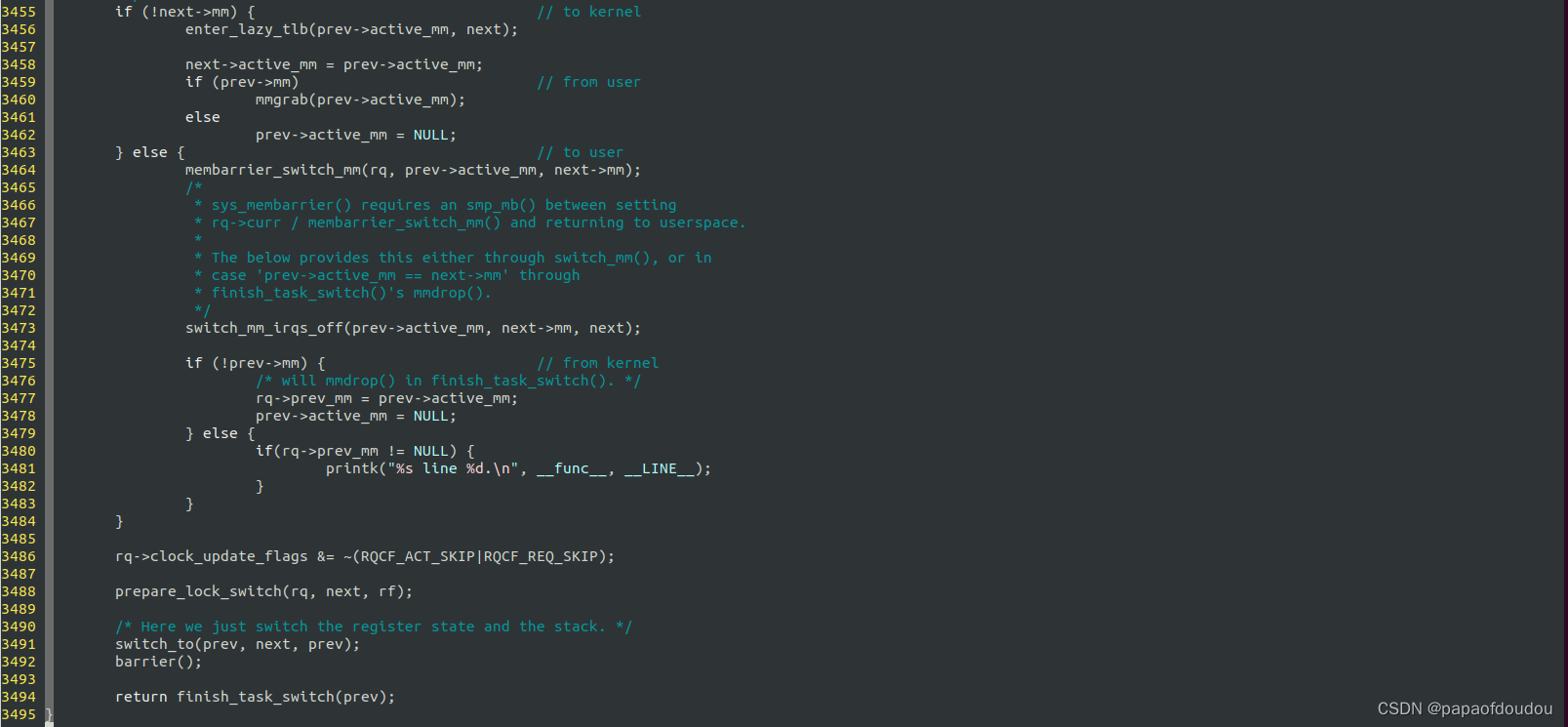
switch_to是一个宏,由汇编实现:

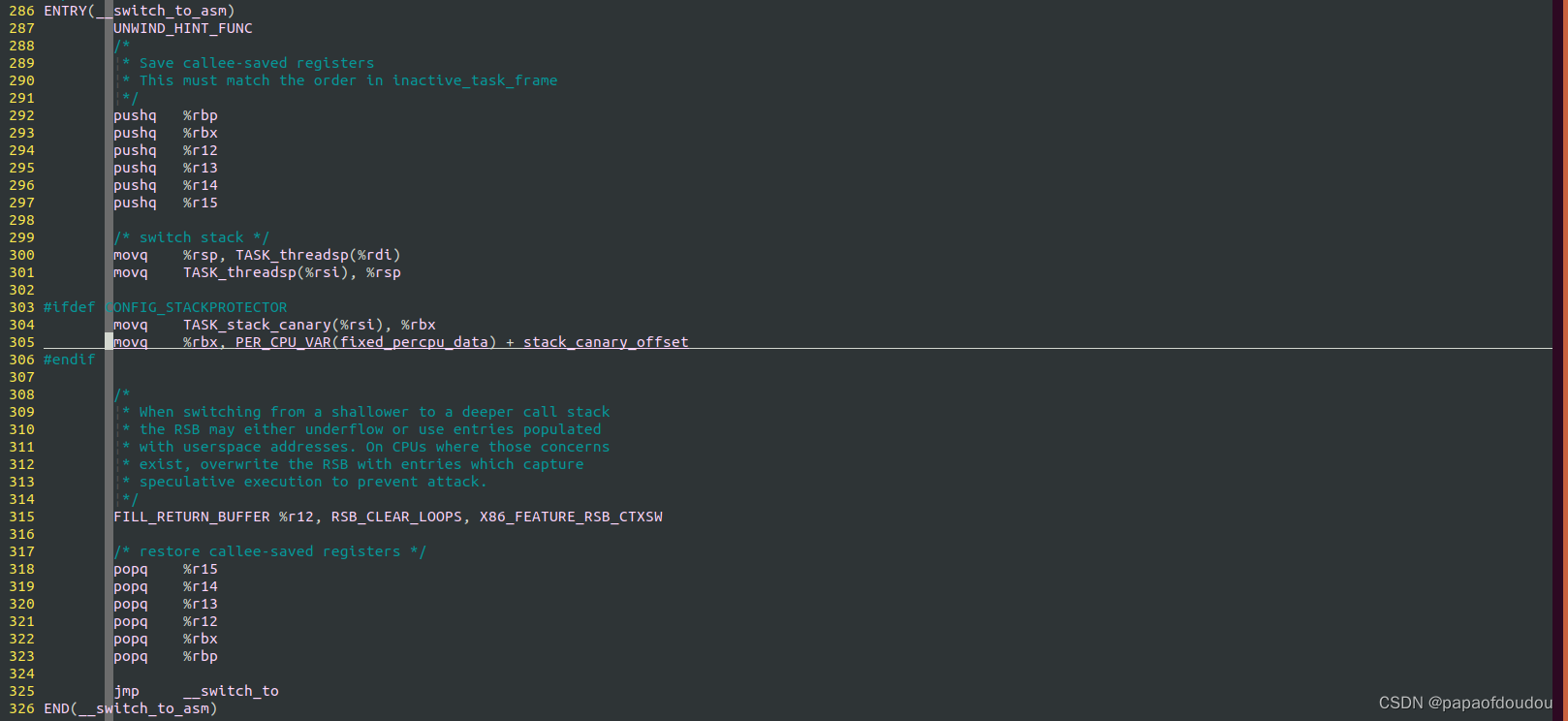
注意到switch_to有三个参数,这是为何?由于在contex_switch函数中,prev和next都是内核prev内核线程上的局部变量,现在假设从进程A切换到进程B,此时进程A的内核态堆栈中的prev指向进程A,而next指向进程B,B进程下一次切换的目标可能不是A,而是经过多轮切换后,切换到了C,由C切换回A,当切换回到A后,A从switch_to后面接着运行,保存在进程A的内核态堆栈上的prev原本仍然指向A的,但为了精简内存使用,代码中又拿prev作为LAST参数,传递最近一次调度的源C:
((last) = __switch_to_asm((prev), (next)));
C切换回到进程A的时候会将prev也就是C的指针通过寄存器EAC传递回到A,再次复制给了进程A堆栈中的PREV,所以对于个指定进程来说,switch_to执行前后,prev指向的任务可能会发生变化。经过如下代码确认后,发现确实switch_to前后,next不变,而prev会发生变化。再调用switch_to前,prev指向current,而当调用switch_to后,prev指向了来处。


总之,switch_to会将源传递给下一个进程,并且复制给下一个进程的prev,所以prev分成两个阶段,在switch_to前,保存的是current,而切换回来后,调度已经完成,调度前的prev/next已经失去了作用,所幸就让prev发挥预热,记录调度源的任务,后面finish_task_switch会用到源任务,还节省一个栈变量。
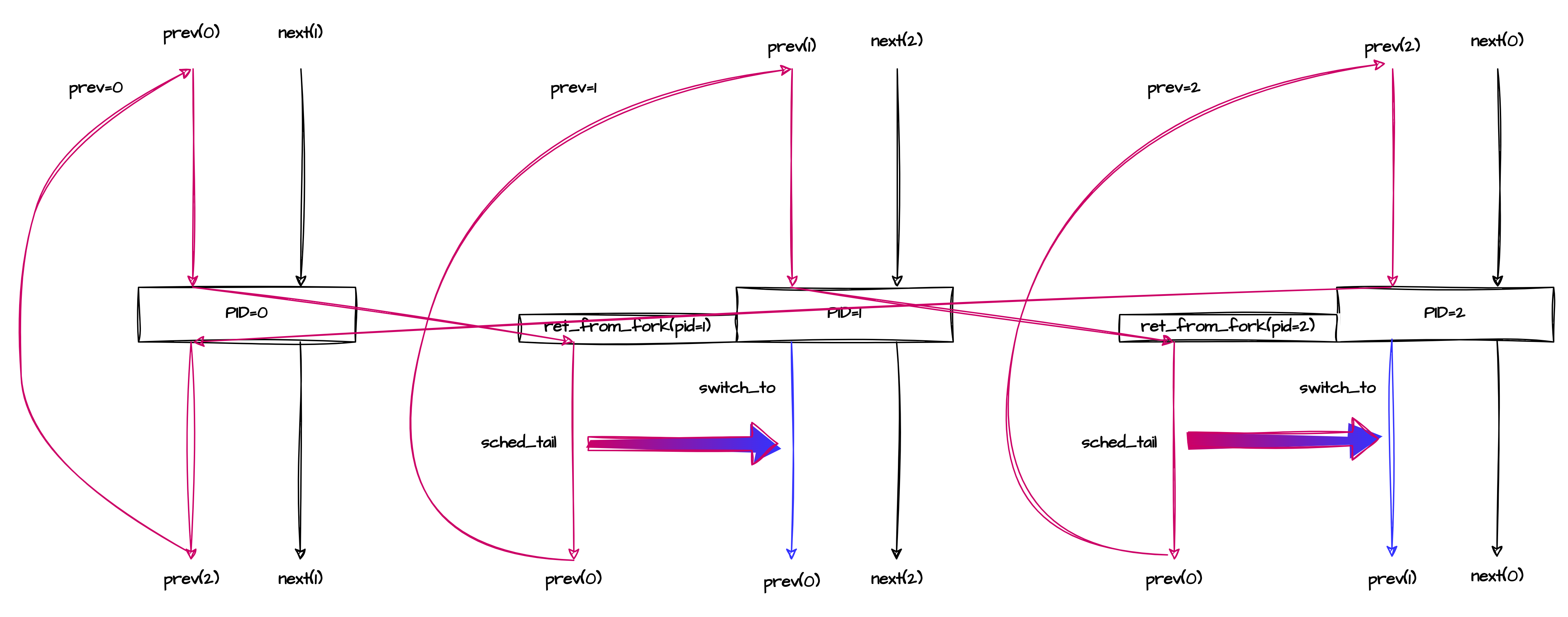
以LINUX系统刚启动时,INIT进程还没有用户态的时候,PID 0,1,2三个进程之间的调度举例,为了说明简单,这里把last当作独立的变量,而不和PREV共用。此时进行的是KERNEL到KERNEL之间的调度,还不存在用户态进程,所以应用的是初始struct mm_struct init_mm.

注意上面的调度图是三个线程完全运行起来后的调度情况,并不包括PID1和PID2的首次调度,首次调用有独立的入口点路径(ret_from_fork->schedule_tail->finish_task_switch).
当INIT成长为用户进程后(通过EXECVE操作,分配一个新的mm_struct),此时的struct mm_struct大家共用INIT进程的。
此时首次出现user->kernel的调度,之后才会出现kernel->user的调度。

此时,如果不执行leave_mm纠正IDLE进程的struct mm_struct 为内核的init_mm,则init_mm在用户态进程创建后,将永远都没机会用到。
经过测试,将leave_mm放空,并不会影响系统启动和正常运行,这也说明init_mm在用户态起来后,可以不用真正的设置到CR3寄存器中作为物理页表,而是借用用户态的页表,毕竟所与的用户态进程的内核部分页表都是共享的。
DEBUG context_switch
3485 if (jiffies % 10000 == 0 && 1 == smp_processor_id()) {
3486 pr_err("AAAAAA, -------------------------------------------");
3487 pr_err("AAAAAA, start");
3488 pr_err("AAAAAA, &prev:%p", &prev);
3489 pr_err("AAAAAA, &next:%p", &next);
3490 pr_err("AAAAAA, prev:%p, pid:%d, comm:%s", prev, prev->pid, prev->comm);
3491 pr_err("AAAAAA, next:%p, pid:%d, comm:%s", next, next->pid, next->comm);
3492 dump_stack();
3493 pr_err("AAAAAA, -------------------------------------------");
3494 }
3495
3496 /* Here we just switch the register state and the stack. */
3497 switch_to(prev, next, prev);
3498 barrier();
3499
3500 if (jiffies % 10000 == 0 && 1 == smp_processor_id()) {
3501 pr_err("AAAAAA, -------------------------------------------");
3502 pr_err("AAAAAA, &prev:%p", &prev);
3503 pr_err("AAAAAA, &next:%p", &next);
3504 pr_err("AAAAAA, prev:%p, pid:%d, comm:%s", prev, prev->pid, prev->comm);
3505 pr_err("AAAAAA, next:%p, pid:%d, comm:%s", next, next->pid, next->comm);
3506 dump_stack();
3507 pr_err("AAAAAA, end");
3508 pr_err("AAAAAA, -------------------------------------------");
3509 }
3510
3511 return finish_task_switch(prev);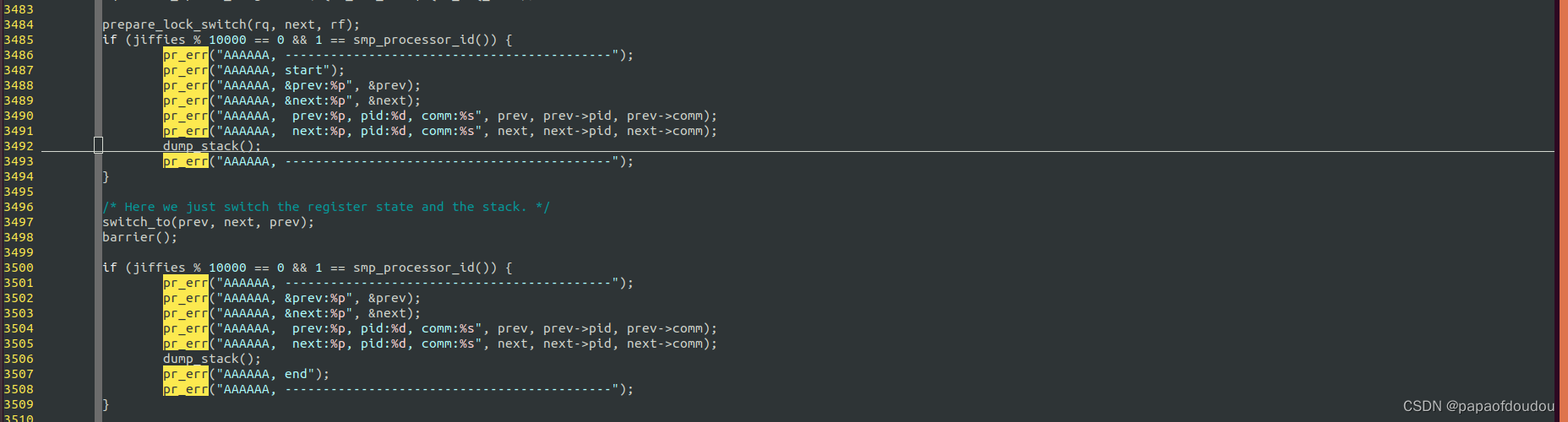
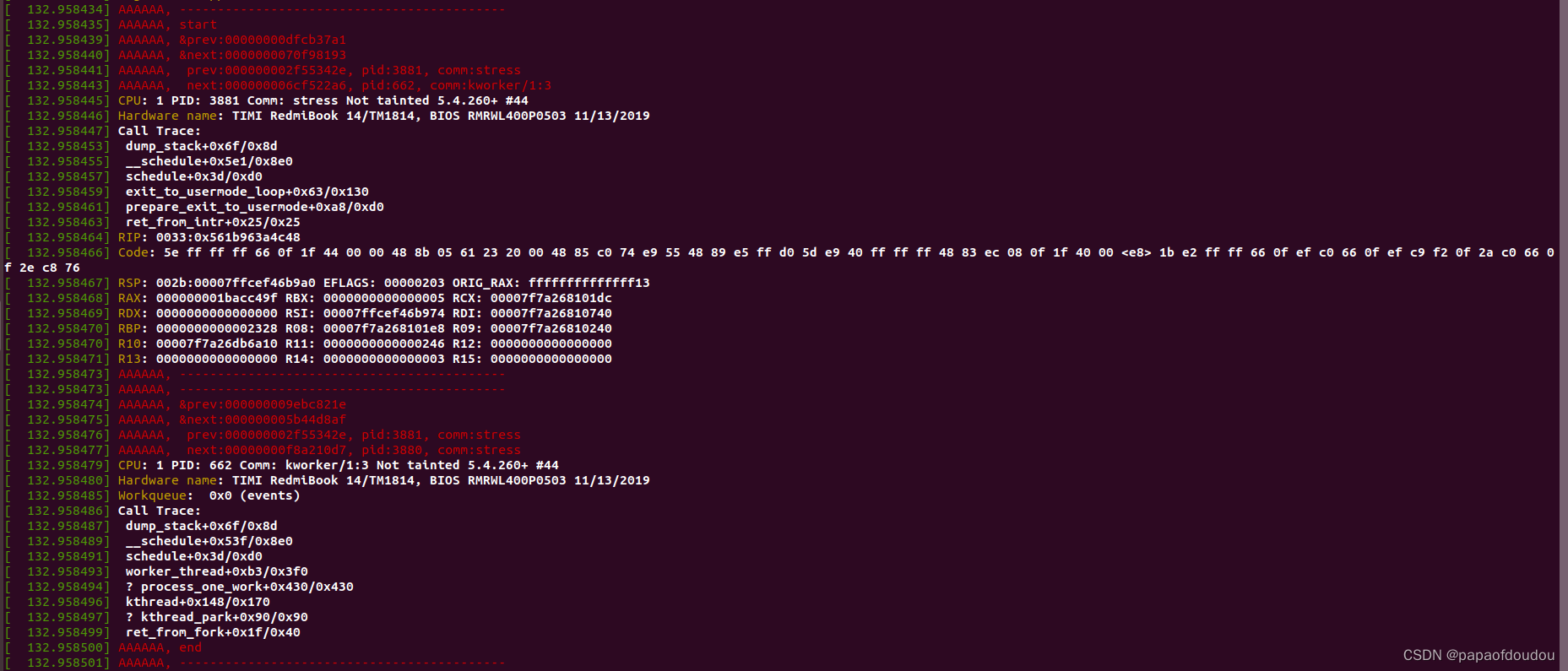
锁定一个核上的调度情况,为了避免打印太频繁,周期打印:
查看方法:
1.switch_to执行前后,&prev,&next地址发生变化,说明进行了任务堆栈的切换。
2.调度前的next和调度后的dump_stack PID相同,说明调度到了next线程。
3.调度后的prev等于调度前的current(prev),说明调度后新栈上的原prev被覆盖调,指向调度源线程。
4.任务本身在调度点的next并没有发生变化,在switch_to前指向本栈的调度目标,在switch_to后指向目标栈曾经的切换目标。
组合调度图为,NEXT作为调度器输出的临时变量,不具有链接性,prev是链接调度点的关键。
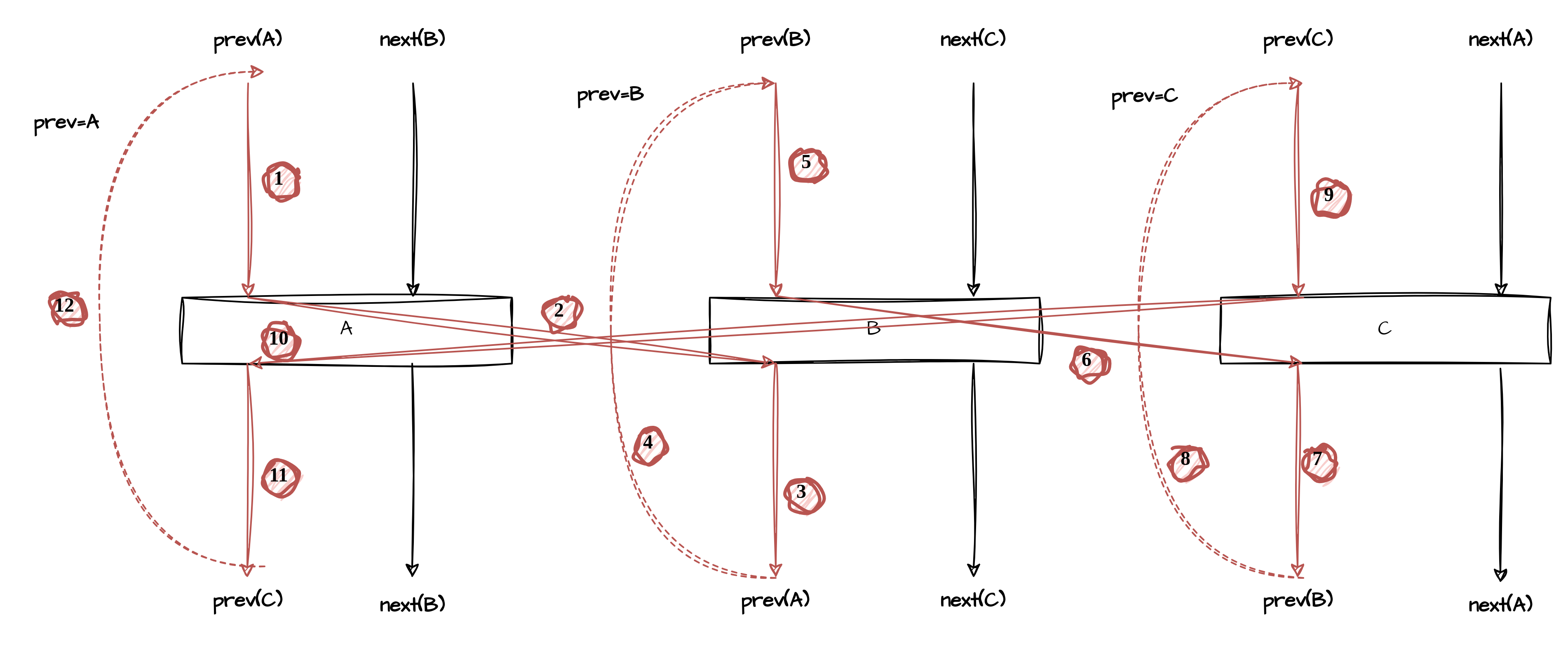
为了达到上图中的完美对陈的执行状态,系统BRINGUP阶段和新进程启动阶段需要一个dedicate 的执行流,新的进程不能从switch_to中调度回来,而是从汇编入口ret_from_fork->schedule_tail->finish_prev_task直接切入,之后的调度才会完美符合上图的调度流程。也就说说,调度的后半段需要进行一次从ret_from_fork/schedule_tail流到context_swith后半段的一个切换,切换后,就成为上图的样子了。



















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











