







集成学习(ensemble learning)构建并结合多个学习器来完成机器学习任务。按照个体学习器之间是否存在依赖关系可以分为两类,两类各以Boosting系列和Bagging系列为典型代表。梯度提升树(Gradient Boosting Decision Tree)是Boosting系列中很重要的算法。
1.集成学习
集成学习的核心思想是:基于训练集,训若干弱学习器,经过特定策略结合在一起,形成一个强学学习器。
2.GBDT概述
决策树
决策树是啥?
举个例子,有一堆人,我让你分出男女,你依靠头发长短将人群分为两拨,长发的为“女”,短发为“男”,你是不是依靠一个指标“头发长短”将人群进行了划分,你就形成了一个简单的决策树。
划分的依据是啥?
这个时候,你肯定问,为什么用“头发长短”划分啊,我可不可以用“穿的鞋子是否是高跟鞋”,“有没有喉结”等等这些来划分啊,Of course!那么肯定就需要判断了,那就是哪一种分类效果好,我就选哪一种啊。
分类效果如何评价量化呢?
怎么判断“头发长短”或者“是否有喉结”…是最好的划分方式,效果怎么量化。直观来说,如果根据某个标准分裂人群后,纯度越高效果越好,比如说你分为两群,“女”那一群都是女的,“男”那一群全是男的,这个效果是最好的,但事实不可能那么巧合,所以越接近这种情况,我们认为效果越好。于是量化的方式有很多,信息增益(ID3)、信息增益率(C4.5)、基尼系数(CART)等等,来用来量化纯度。
依靠某种指标进行树的分裂达到分类/回归的目的(上面的例子是分类),总是希望纯度越高越好。
回归树
事实上,分类与回归是一个型号的东西,只不过分类的结果是离散值,回归是连续的,本质是一样的,都是特征(feature)到结果/标签(label)之间的映射。
分类树的样本输出(即响应值)是类的形式,如判断蘑菇是有毒还是无毒,周末去看电影还是不去。而回归树的样本输出是数值的形式,比如给某人发放房屋贷款的数额就是具体的数值,可以是0到120万元之间的任意值。
那么,这时候你就没法用上述的信息增益、信息增益率、基尼系数来判定树的节点分裂了,你就会采用新的方式,预测误差,常用的有均方误差、对数误差等。而且节点不再是类别,是数值(预测值),那么怎么确定呢,有的是节点内样本均值,有的是最优化算出来的比如Xgboost。
一个回归树形成的关键点:(1)分裂点依据什么来划分(如前面说的均方误差最小,loss);(2)分类后的节点预测值是多少(如前面说,有一种是将叶子节点下各样本实际值得均值作为叶子节点预测误差,或者计算所得)
3.GBDT树
GBDT树的构建,是用回归树去拟合损失函数的负梯度,下一颗树是用上棵树的结果,继续用回归树去拟合负梯度,如此循环。
在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是H_m-1(x), 损失函数是L_m-1(x), 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器F_m(x),让本轮的损失函数最小。也就是说,本轮迭代找到的决策树,要让样本的损失变得更小。
需要强调的是,负梯度并不是上一轮迭代残差的估计值,虽然负梯度也被称为伪残差,但实际上与真正的残差没有关系。
现在我们已经对GBDT有了直观理解,那么GBDT树与其拟合方法具体是怎样的呢?
回归树模型
GBDT中的DT是回归树,不是分类树,只有回归树才有梯度提升。
决策树的主要思想是将输入空间划分为不同的子区域,然后给每个子区域确定一个值,如果是分类树,这个值就是类别,如果是回归树,就是一个实值。其通用模型如下式:
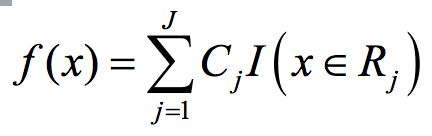
其中I为指示函数。(例如二分类树中,若X属于R_j,I(x)=1,否则I(x)=0)
确定一棵回归需要确定两部分,第一部分就是树的结构,这个结构负责将一个样本映射到一个确定的叶子节点上,其本质上就是一个函数。第二部分就是各个叶子节点上的分数。回归树的叶子节点对应的值是一个实际的分数,而非一个确定的类别。
分析了GBDT树的结构之后,让我们依次推导加法模型、前向分布算法以及梯度提升,从而探寻GBDT的拟合方法。
4.加法模型
加法模型是指一种模型集H,它的一般形式如下:
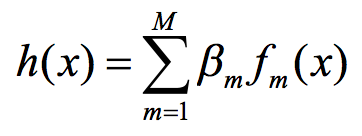
f_m(x)称为基函数,基函数可以有各种形式,自然也会有自己的参数,对于GBDT而言,它就是回归树。β_m是基函数的系数,一般假设大于0。
有了模型,还需要定义该模型的经验损失函数,如下式:
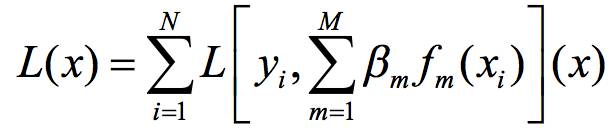
现在,我们的问题转变成了通过极小化经验损失函数来确定各个系数β_m和各个基函数f_m(x)。
5.前向分布算法
前向分步算法提供了一种学习加法模型的普遍性方法,不同形式的基函数、不同形式的损失函数都可以用这种普遍性方法去求出加法模型的最优化参数,它是一种元算法。
它的学习思路是:加法模型中一共有M个基函数以及与之相应的M个系数,可以从前往后,每次学习一个基函数及其系数。如先学习f_m和β_m,其学习公式如下:
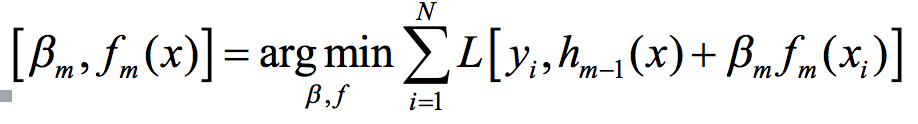
前向分步算法中最核心的问题就是如何求出使损失函数最小化的f_m和β_m。
6.梯度提升求解
梯度提升方法就是为了解决上面的问题。其运算步骤是先求f_m,再求β_m。
我们要最小化的上述损失函数由N部分相加而成,如果能够最小化每一部分,自然也就最小化了整个函数。考察其中任一部分,并将其在 X_0=H_m-1(x_i)处进行泰勒一阶展开,得到下式:
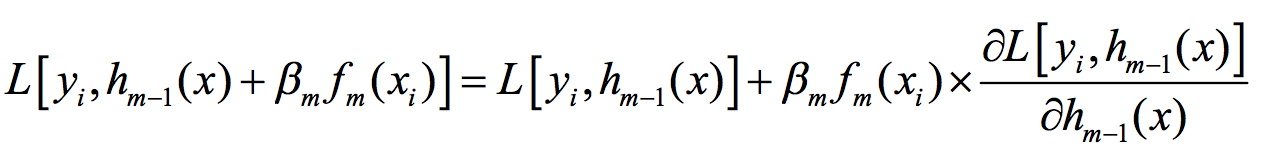
由于前面的假设系数β大于0,那么有,若:
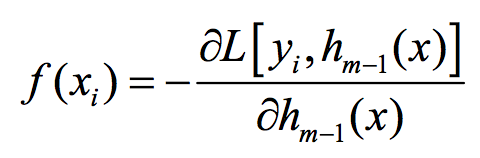
则尾项小于零,从而:
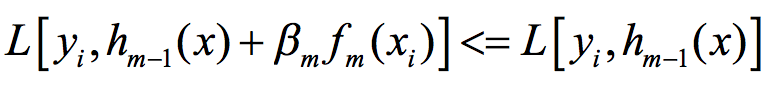
即降低了在第i个样本点上的预测损失。同理,我们可以降低在每一个样本点上的预测损失。
这个条件其实告诉了我们如何去寻找f_m,即能够使得在每一个样本点上上式尽可能成立的f_m就是我们要找的。
我们已经有了f_m,下面优化求解β_m,很显然,这是一个一维搜索问题,如下:
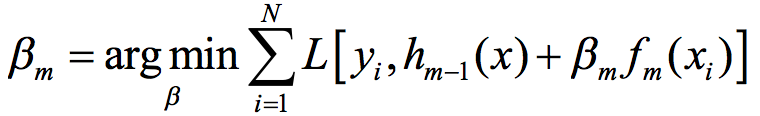
由于泰勒一阶展开在局部取值有效,所以要求β_m*F_m(x_i)足够小,显然,执行一维搜索后得到的β_m会满足这个条件。
至此,我们已经找到了GBDT的拟合方法。
7.GBDT用于分类
GBDT用于分类从思想上和GBDT回归算法没有区别,但是由于样本输出不再是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。
为了解决这一问题,主要有两个方法。一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法是用类似于逻辑回归的对数似然损失函数的方法,如下式:

也就是说,我们用的是类别的预测概率值和真实概率值的差来拟合。















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









