







决策树
构造决策树的关键在于如何设置决策树的贪心策略,通过最大化贪心指标,寻找最优解,让叶节点尽早的变得更纯。构建决策树主要有两个步骤:决策树的建立和剪枝。对于决策树的建立,根据节点分裂方法不同,有三种贪心策略,分别是使用 Gini 指数、香农熵、均方误差进行分裂。不同策略就构成了不同的决策树算法,常用的有 ID3 算法、C4.5 算法、CART 算法。ID3 算法使用的是信息增益方式进行特征分裂、C4.5 算法使用信息增益比的方式,而 CART 算法是基于 Gini 指数进行特征选择。

直观例子
从众多候选者中筛选出自己有意愿见面的对象。从网站里随机挑选了100个人,主要观察4个特征,并给出标记(这个男生在自己心里的打分)。然后训练了一个决策树模型,通过模型对征婚网站上的人进行筛选。
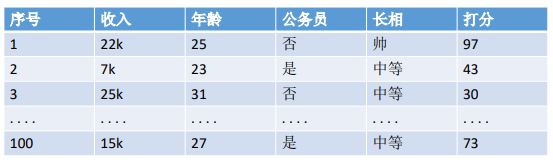
构造的决策树:

构建方式
- 确定评价决策树好坏的指标
- 列举所有可能的决策树,然后计算各自的指标,选出最优的一棵树
贪心策略
- 思想:确定贪心指标,在候选方案集合中执行一个让贪心指标最大的方案。不会从全局最优的角度思考问题,近似求解,这个解可能是次优解(sub-optimal)。
- 目的:让叶子节点尽早变得更纯
决策树的贪心指标

- 基尼指数:用于分类决策树,如果结点中实例是纯的,那么基尼指数=0
- 香农熵:用于分类决策树,刻画不确定程度,如果结点中实例是纯的,那么香农熵=0
- 均方误差:用于回归决策树,结点内的均方误差
- 信息增益:信息增益 = 原来结点的不纯度 – 子结点不纯度的和。
I G ( D , s ) = Impurity ( D ) − N left N Impurity ( D left ) − N right N Impurity ( D right ) I G(D, s)=\operatorname{Impurity}(D)-\frac{N_{\text {left }}}{N} \text { Impurity }\left(D_{\text {left }}\right)-\frac{N_{\text {right }}}{N} \text { Impurity }\left(D_{\text {right }}\right) IG(D,s)=Impurity(D)−NNleft Impurity (Dleft )−NNright Impurity (Dright )
产生的算法
根据不同的衡量结点不纯的指标,给这些决策树的算法起了名字
- ID3算法:基于香农熵增益,缺点:会偏爱取值较多的特征。
香农熵增益 = 结点的香农熵 – 子结点香农熵的带权和 - C4.5算法:基于香农熵增益比,缺点:计算复杂度高
香农熵增益比 = 参数*香农熵增益(某特征的特征值种类越多,那么参数越小) - CART分类算法:基于基尼指数增益
基尼指数增益 = 结点的基尼指数 – 子结点的基尼指数的带权和 - CART回归算法:基于方差增益
方差增益 = 结点的方差 – 子结点的方差的带权和
比较:
- ID3和C4.5算法均只适合在小规模数据集上使用
- ID3和C4.5算法都是单变量决策树
- 当属性值取值比较多的时候,最好考虑C4.5算法,ID3得出的效果会比较差
- 决策树分类一般情况只适合小数据量的情况(数据可以放内存)
- CART算法是三种算法中最常用的一种决策树构建算法。
- 三种算法的区别仅仅只是对于当前树的评价标准不同而已,ID3使用信息增益、C4.5使用信息增益率、CART使用基尼系数
- CART算法构建的一定是二叉树,ID3和C4.5构建的不一定是二叉树
贪心指标设计
- 设计衡量结点不纯度的指标
- 设计衡量变纯程度的指标(信息增益)
- 遍历全体划分点候选集,使用能让信息增益最大的划分点构建决策树。递归构建树,直到达到停止条件,完成整棵决策树的构建
候选集的划分例子
现有:连续特征F1有10种取值:1、2、3、4、5、6、7、8、9、10。离散特征F2有 4 种取值:A、B、C、D。
- 对于连续特征的候选集划分:二叉树分法,splits={ F1<2, F1<3, F1<4, F1<5, F1<6, F1<7, F1<8, F1<9, F1<10 }
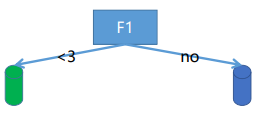
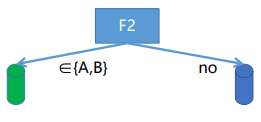
- 对于离散特征的候选集划分:二叉树分法,splits={ A|… ,AB|… ,AC|… ,AD|… ,ABC|… ,ABD|… ,ACD|… }。
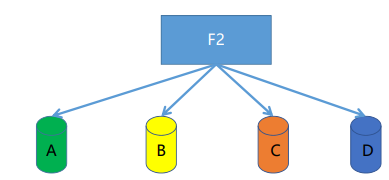
多叉树分法,splits={A|B|C|D}
决策树构建
用ID3算法训练一个决策树模型,对未来的西瓜的优劣做预
测。

步骤:
-
在决策树开始学习时,根结点包含D中所有样例,|Y|=2,其中正例占p1=8/17,反例占p2=9/17。于是根结点的香农熵为:
E n t ( D ) = − ∑ k = 1 2 p k l o g 2 p k = 0.998 Ent(D)=-\sum_{k=1}^{2} p_{k}log_{2}p_{k}=0.998 Ent(D)=−k=1∑2pklog2pk=0.998 -
全体划分点候选集:色泽、根蒂、。。。、触感
-
计算全体候选集的长度
-
依次计算候选集的信息增益(以色泽为例)
根据色泽:spilt={青绿|乌黑|浅白},那么
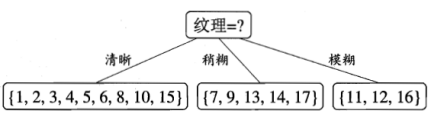
D 青绿 : { 1 , 4 , 6 , 10 , 13 , 17 } , 正例p1=3/6,反例占p2=3/6 , E n t ( D 青绿 ) = 1. D 乌黑 : { 2 , 3 , 7 , 8 , 9 , 15 } , 正例p1=4/6,反例占p2=2/6 , E n t ( D 乌黑 ) = 0.918. D 浅白 : { 5 , 11 , 12 , 14 , 16 } , 正例p1=1/5,反例占p2=4/5 , E n t ( D 浅白 ) = 0.722. D_\text{青绿}:{\{1,4,6,10,13,17\}},\text{正例p1=3/6,反例占p2=3/6},Ent(D_\text{青绿})=1. \\ D_\text{乌黑}:{\{2,3,7,8,9,15\}} ,\text{正例p1=4/6,反例占p2=2/6},Ent(D_\text{乌黑})=0.918. \\ D_\text{浅白}:{\{5,11,12,14,16\}},\text{正例p1=1/5,反例占p2=4/5},Ent(D_\text{浅白})=0.722. D青绿:{1,4,6,10,13,17},正例p1=3/6,反例占p2=3/6,Ent(D青绿)=1.D乌黑:{2,3,7,8,9,15},正例p1=4/6,反例占p2=2/6,Ent(D乌黑)=0.918.D浅白:{5,11,12,14,16},正例p1=1/5,反例占p2=4/5,Ent(D浅白)=0.722.
“色泽”划分数据集后的信息增益:
Gain ( D , 色泽 ) = Ent ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Ent ( D v ) = 0.998 − ( 6 17 × 1 + 6 17 × 0.918 + 5 17 × 0.722 ) = 0.109 \operatorname{Gain}(D, \text { 色泽 })=\operatorname{Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Ent}\left(D^{v}\right)=0.998-(\frac{6}{17}×1+\frac{6}{17}×0.918+\frac{5}{17}×0.722)=0.109 Gain(D, 色泽 )=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)=0.998−(176×1+176×0.918+175×0.722)=0.109
同理:
Gain ( D , 根蒂 ) = 0.143 Gain ( D , 敲声 ) = 0.141 Gain ( D , 触感 ) = 0.006 Gain ( D , 纹理 ) = 0.381 Gain ( D , 脐部 ) = 0.289 \begin{array}{lll} \operatorname{Gain}(D, \text { 根蒂 })=0.143 & \operatorname{Gain}(D, \text { 敲声 })=0.141 & \operatorname{Gain}(D, \text { 触感 })=0.006 \\ \operatorname{Gain}(D, \text { 纹理 })=0.381 & \operatorname{Gain}(D, \text { 脐部 })=0.289 & \end{array} Gain(D, 根蒂 )=0.143Gain(D, 纹理 )=0.381Gain(D, 敲声 )=0.141Gain(D, 脐部 )=0.289Gain(D, 触感 )=0.006
结论:“纹理”划分后信息增益最大,于是,通过“纹理”划分数据集
- 每次建树后,按照特征值将样本分配,重复建树,得到完整的决策树

剪枝处理
- 宽泛来讲:机器学习模型都会有过拟合风险,在训练集上表现的
过于优秀,而泛化能力差,因此机器学习模型都有对应的防止过
拟合的策略,决策树的策略就是剪枝 - 具体来讲:决策树生成算法会递归地建造决策树的分支,直到结
点都很纯为止。这样产生的决策树往往对训练数据的分类很准确,但失去泛化能力,即发生过拟合了,因此,可通过主动去掉一些分支来降低过拟合的风险,提高模型泛化能力
判断是否过拟合:可以看训练误差和测试误差的关系,测试误差越小,说明模型泛化能力越强。
剪枝方法
- 预剪枝:在决策树生成过程中,考察该轮划分是否会提高泛化性能,如果不能提高泛化性能就不划分
• 优点:性能开销小、速度快
• 缺点:可能会欠拟合,错过最优解 - 后剪枝:先训练一棵完整的树,然后自底向上地进行考察,如果删除该划分能提高泛化性能就删除
• 优点:欠拟合风险小
• 缺点:性能开销大、速度慢
决策树优缺点
- 优点:
• 易于解释
• 处理类别特征,其他的技术往往要求数据属性的单一
• 延展到多分类
• 不需要特征放缩
• 能捕获非线性关系和特征间的交互关系 - 缺点:
• 寻找最优的决策树是一个NP-hard的问题,只能通过启发式方法求次优解
• 决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变
• 如果某些离散特征的特征值种类多,生成决策树容易偏向于这些特征 ID3
• 有些比较复杂的关系,决策树很难学习,比如异或
决策树可视化
决策树可视化可以方便我们直观的观察所构建的树模型;决策树可视化依赖graphviz服务,所以我
们在进行可视化之前,安装对应的服务;操作如下:
- 安装graphviz服务
• 下载安装包(msi安装包): http://www.graphviz.org/;
• 执行下载好的安装包(双击msi安装包);
• 将graphviz的根目录下的bin文件夹路径添加到PATH环境变量中; - 安装python的graphviz插件: pip install graphviz
- 安装python的pydotplus插件: pip install pydotplus
决策树例子的python实现
决策树分类
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.pipeline import Pipeline
import warnings
from sklearn.metrics import classification_report
warnings.filterwarnings('ignore')
#也可直接使用python自带的数据集dataset
data = pd.read_csv(r'../datas/iris.txt', header=None, names=['x1', 'x2', 'x3', 'x4', 'lable'])
# 为了可以更好的进行可视化效果,只取前两个特征进行操作
x = data.iloc[:, :2]
y = data.iloc[:, -1:]
lable = LabelEncoder()
y = lable.fit_transform(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
#管道进行处理操作
model = Pipeline([
('ss', StandardScaler()),#决策时不同做特征缩放
#决策树使用ID3算法进行处理,深度为3
('DTC', DecisionTreeClassifier(criterion='entropy', max_depth=3))])
model = model.fit(x_train, y_train)
y_test_hat = model.predict(x_test)
#可视化
N, M = 100, 100 # 横纵各采样多少个值
plt.rcParams['font.sans-serif'] = ['SimHei']
x1_min, x1_max = x.iloc[:, 0].min(), x.iloc[:, 0].max() # 第0列的范围
x2_min, x2_max = x.iloc[:, 1].min(), x.iloc[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_show = np.stack((x1.flat, x2.flat), axis=1) # 测试点
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_show_hat = model.predict(x_show) # 预测值
y_show_hat = y_show_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_show_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x_test.iloc[:, 0], x_test.iloc[:, 1], c=y_test.ravel(), edgecolors='k', s=100, cmap=cm_dark, marker='o') # 测试数据
#edgecolors 边框颜色
plt.scatter(x.iloc[:, 0], x.iloc[:, 1], c=y.ravel(), edgecolors='k', s=40, cmap=cm_dark) # 全部数据
plt.xlabel('x1', fontsize=15)
plt.ylabel('x2', fontsize=15)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid(True)
plt.title(u'鸢尾花数据的决策树分类', fontsize=17)
plt.show()
print(model.score(x_test, y_test))
决策树回归
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split, GridSearchCV
data = pd.read_csv(r'../datas/Advertising.csv')
#划分x,y
x = data.iloc[:, :-1]
y = data.iloc[:, -1:]
#留出法,分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
#创建模型
model = DecisionTreeRegressor()
#网格搜索
param_grid={'max_depth':[3, 5, 7, 9, 11]}
tree = GridSearchCV(model, param_grid=param_grid, cv=3)
tree.fit(x_train, y_train)
tree_score = tree.score(x_test, y_test)#R^2
print(tree_score)
tree_predict = tree.predict(x_test)
model = Ridge()
param_grid = {'alpha': [1, 0.75, 0.5, 0.1, 0.05, 0.01]}
ridge = GridSearchCV(model, param_grid=param_grid, cv=3)
ridge.fit(x_train, y_train)
print(ridge.best_params_)
ridge_score = ridge.score(x_test, y_test)
print(ridge_score)
ridge_predict = ridge.predict(x_test)
plt.rcParams['font.sans-serif']=['SimHei']
m, n = y_test.shape
plt.plot(np.arange(m), y_test, 'r-', label='真实分布')
plt.plot(tree_predict, 'g-', label=u'决策树回归,$R^2$=%.4f' % tree_score)
plt.plot(ridge_predict, 'b-', label=u'岭回归, $R^2$=%.4f'% ridge_score)
plt.grid()
plt.legend()
plt.show()
















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











