







我希望自己能像上面的段子一样把复杂的数学讲的接地气一点
都知道卷积过程中特征图边长的计算,各种资料都有:
int height_col= (height + 2 * pad_h - kernel_h) / stride_h + 1;
int width_col = (width + 2 * pad_w - kernel_w) / stride_w + 1;
注:height_col width_col分别是卷积后的高度和宽度,不做赘述。
那么卷积过程中通道数目是怎么变化的呢?同事说是作者自己设定的,怎么设定的呢?画一张图解释:
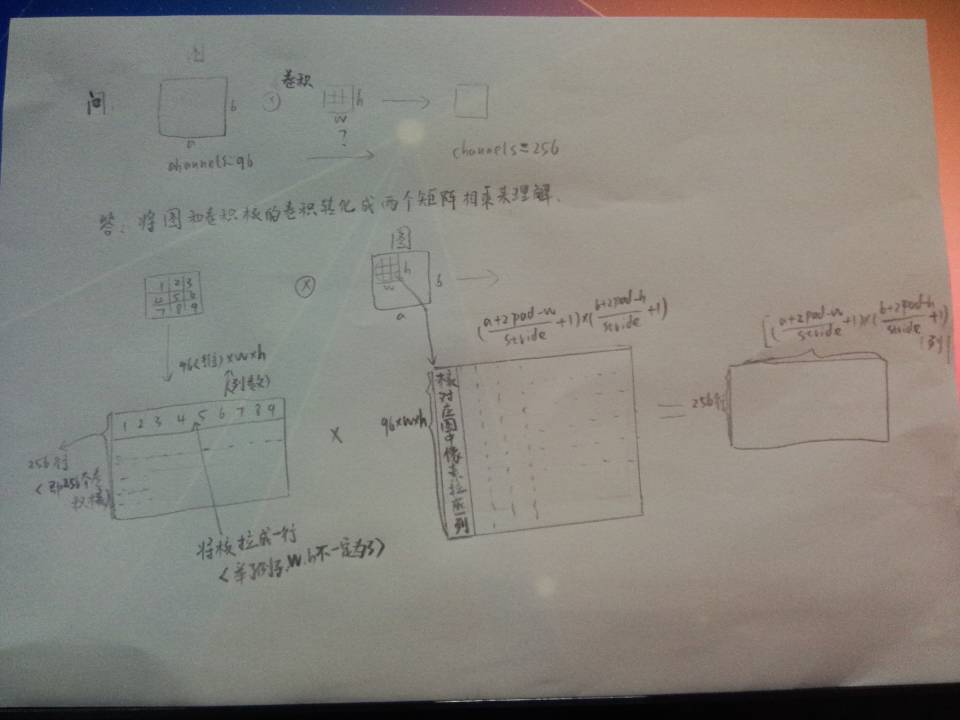
怎么样,想要得到多少维的特征图,就可以通过设定卷集核的个数来决定。图中是256。
注:我把卷积核拉成1-9为了直观,本质上是96*3*3对应原核应该是三维的
再举个例子(方便理解):
假设有两个卷积核为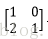
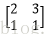
输入图像矩阵为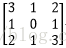
故height_col=[(3+2*0-2)/1+1]=2 width_col=[ (3+2*0-2)/1+1]=2
A矩阵(M*K)为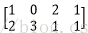
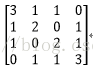
C=A*B=
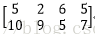
C中的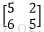
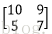
caffe作者贾扬清在github上提到卷积优化问题:
First of all, convolution is, in some sense, quite hard to optimize. While the conventional definition of convolution in computer vision is usually just a single channel image convolved with a single filter (which is, actually, what Intel IPP's convolution means), in deep networks we often perform convolution with multiple input channels (the word is usually interchangeable with "depth") and multiple output channels.
Loosely speaking, assume that we have a W*H image with depth D at each input location. For each location, we get a K*K patch, which could be considered as a K*K*D vector, and apply M filters to it. In pseudocode, this is (ignoring boundary conditions):
for w in 1..W
for h in 1..H
for x in 1..K
for y in 1..K
for m in 1..M
for d in 1..D
output(w, h, m) += input(w+x, h+y, d) * filter(m, x, y, d)
end
end
end
end
end
end
作者提到多输入通道即卷积的深,给了卷积的伪代码,表明优化不容易,下面作者给出快速卷积方法(重点):
But I still needed a fast convolution. Thus, I took a simpler approach: reduce the problem to a simpler one, where others have already optimized it really well.The trick is to justlay out all the local patches, and organize them to a (W*H, K*K*D) matrix. In Matlab, this is usually known as an im2col operation. After that, consider the filters being a (M, K*K*D) matrix too
我画的图就是根据此段来的,lay out展开,我解释为拉成,用函数im2col完成。
这里filters(卷集核)(M, K*K*D) 的M=256,D=96,w=h=k,
(M, K*K*D) matrix 乘以(W*H, K*K*D) matrix 的装置 =(M,W*H)matrix {这句话对应我开始画的那幅图}
作者给出了一个图文并茂的解释,来瞻仰下:





Caffe里用的是CHW的顺序,有些library也会用HWC的顺序(比如说CuDNN是两个都支持的),这个在数学上其实差别不是很大,还是一样的意思。
顺便广告一下我吐槽Caffe里面卷积算法的链接:Convolution in Caffe: a memo · Yangqing/caffe Wiki · GitHub
作者:贾扬清
链接:https://www.zhihu.com/question/28385679/answer/44297845
来源:知乎
思考中》》》》
参考:
https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo
https://www.zhihu.com/question/28385679
http://blog.csdn.net/thy_2014/article/details/51954513
http://blog.csdn.net/xiaoyezi_1834/article/details/50786363
http://blog.csdn.net/u010417185/article/details/52192126
http://zhangliliang.com/2015/02/11/about-caffe-code-convolutional-layer/
http://www.cnblogs.com/louyihang-loves-baiyan/p/5154337.html















 3566
3566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









