






导读
在机器学习中,线性模型是一种形式简单但包含机器学习主要建模思想的模型。
线性回归是线性模型的一种典型方法,比如“双十一”中某款产品的销量预测、某数据岗位的薪资水平预测、二手房房价的预测都可以用线性回归来拟合模型。
今天我们就以杭州的二手房的房屋单价为例,看看如何用线性回归进行预测。
2021年杭州二手房挂牌数量累计超过16万套,在新房数量少和排队摇号的限制下,购买二手房已成为杭州人买房更重要的方式。下图是某二手房网站公开的杭州部分地区的二手房房价。
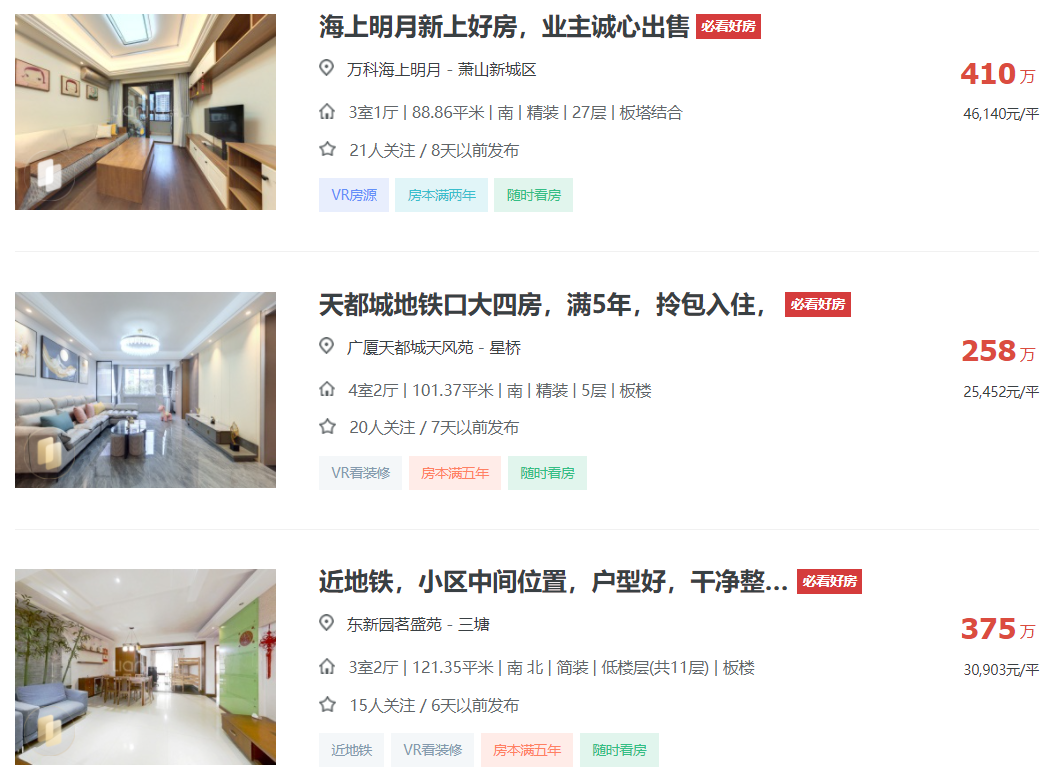
图 | 链家
二手房的市场价格是多种因素综合作用的结果,主要因素有:面积、户型、朝向、是否精装、楼层、建筑形态、所属地段、所属城区和附近是否有地铁等。
我们的目标是预测二手房的均价,输入自变量包括上述特征,因为二手房房屋单价是一个连续数值,所以可以直接建立起由自变量到因变量的线性回归模型。
线性回归的原理推导
给定一组由输入x和输出y构成的数据集D={(x₁,y₁),(x₂,y₂),…,(xₘ,yₘ)},其中xᵢ=(xᵢ1,xᵢ2,…,xᵢd),yᵢ∈R。
线性回归就是通过训练学习得到一个线性模型来最大限度地根据输入x拟合输出y。
线性回归试图用上文提到的对房价的影响因素作为输入xᵢ,以房屋单价yᵢ作为输出,学习得到y=wxᵢ+b。
线性回归学习的关键问题在于确定参数w和b,使得拟合输出y与真实输出yᵢ尽可能接近。
在回归任务中,我们通常使用均方误差来度量预测与标签之间的损失,所以回归任务的优化目标就是使得拟合输出和真实输出之间的均方误差最小化,所以有:
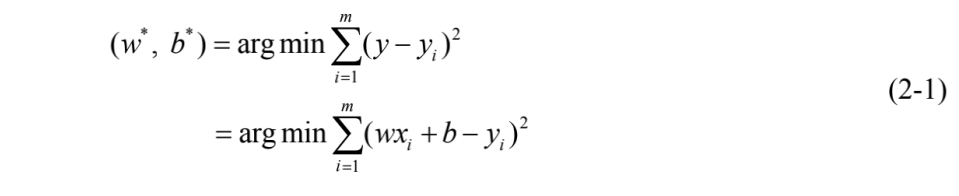
为求得w和b的最小化参数w*和b*,可基于式(2-1)分别对w和b求一阶导数并令其为0,对w求导的推导过程如式(2-2)所示:
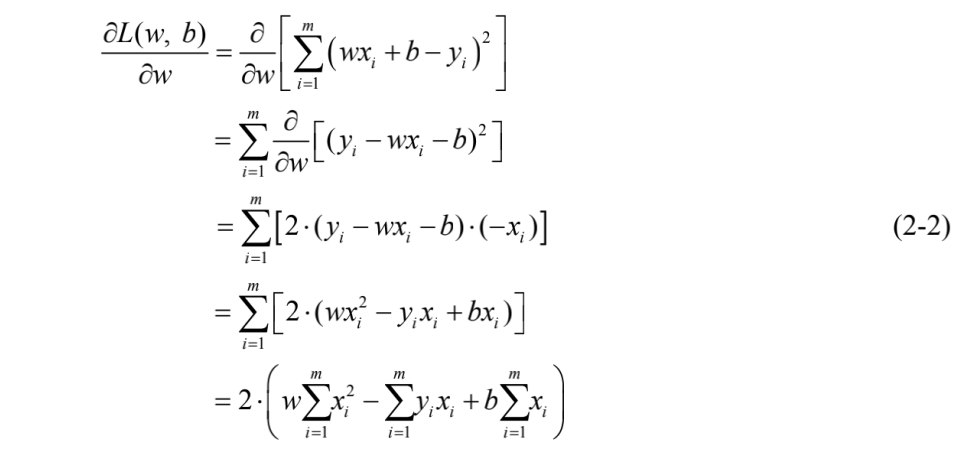
同理,对参数b求导的推导过程如式(2-3)所示:
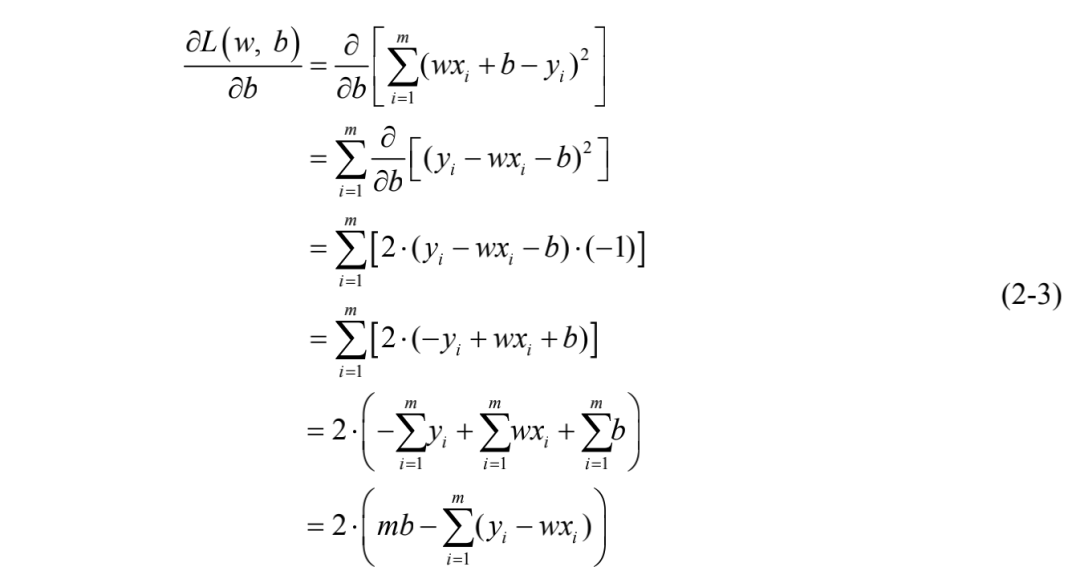
基于式(2-2)和式(2-3),分别令其为0,可解得w和b的最优解表达式为:
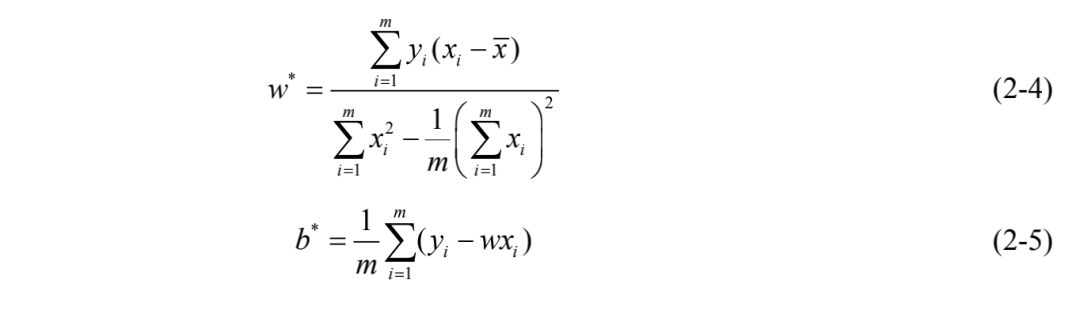
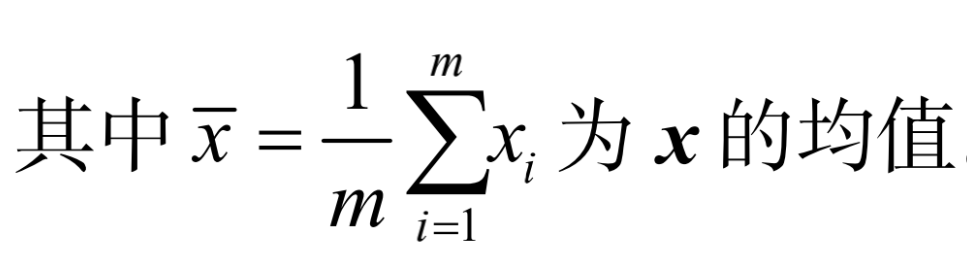
这种基于均方误差最小化求解线性回归参数的方法就是著名的最小二乘法。最小二乘法的简单图示如下所示。
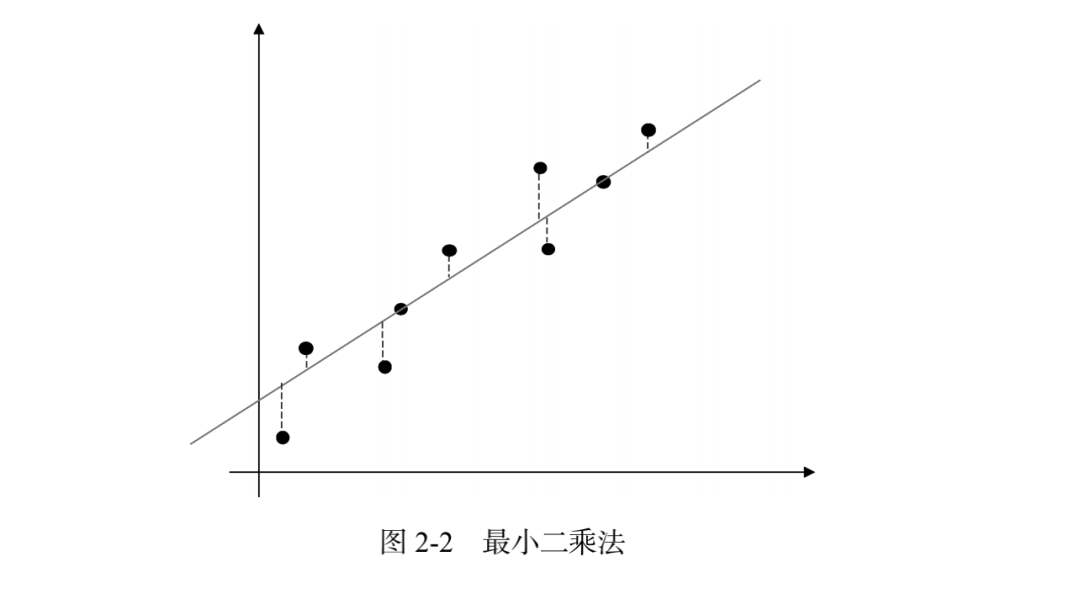
下面我们将上述推导过程进行矩阵化以适应多元线性回归问题。
所谓多元问题,就是输入有多个变量,如前述影响薪资水平的因素包括城市、学历、年龄和经验等。为方便矩阵化的最小二乘法的推导,可将参数w和b合并为向量表达形式:
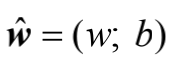
训练集D的输入部分可表示为一个m×d 维的矩阵X,其中d为输入变量的个数。则矩阵X可表示为式(2-6):

输出y的向量表达式为y=(y1,y2,…,ym),类似于式(2-1),参数优化目标函数的矩阵化表达式(2-7)为:
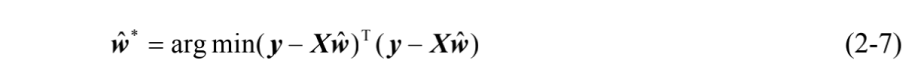
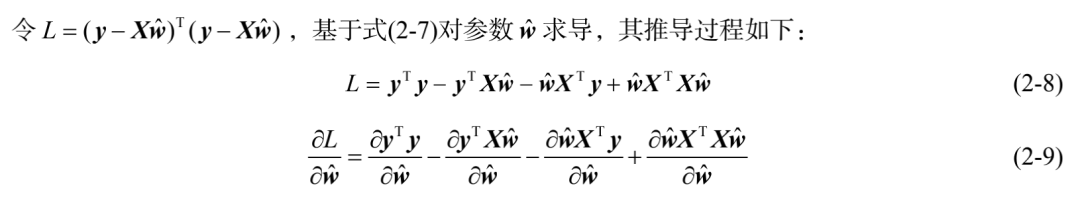
根据矩阵微分公式:
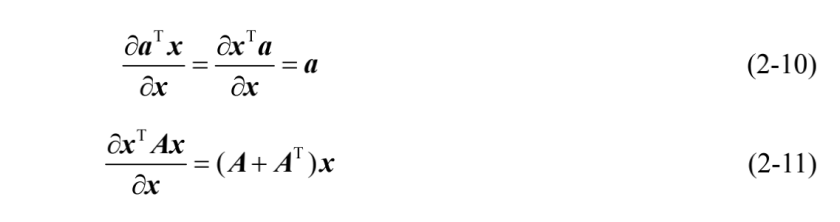
可得:
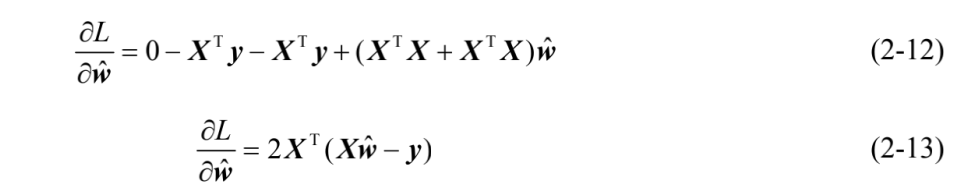
令矩阵XᐪX为满秩矩阵或者正定矩阵,令式(2-13)等于0,可解得参数为:

但有些时候,矩阵XᐪX并不是满秩矩阵,我们通过对XᐪX添加正则化项来使得该矩阵可逆。一个典型的表达式如下:

其中λΙ即为添加的正则化项。在线性回归模型的迭代训练时,基于式(14)直接求解参数的方法并不常用,通常可以使用梯度下降之类的优化算法来求得的最优估计。
线性回归的代码实现
基于一个完整机器学习模型实现的视角,我们从整体编写思路到具体分步实现,使用NumPy实现一个线性回归模型。
按照机器学习三要素——模型、策略和算法的原则,逐步搭建线性回归代码框架。
一、编写思路
线性回归模型的主体较为简单,即y=wTx+b,在具体编写过程中,基于均方损失最小化的优化策略和梯度下降的寻优算法非常关键。一个线性回归模型代码的编写思路如图2-3所示。
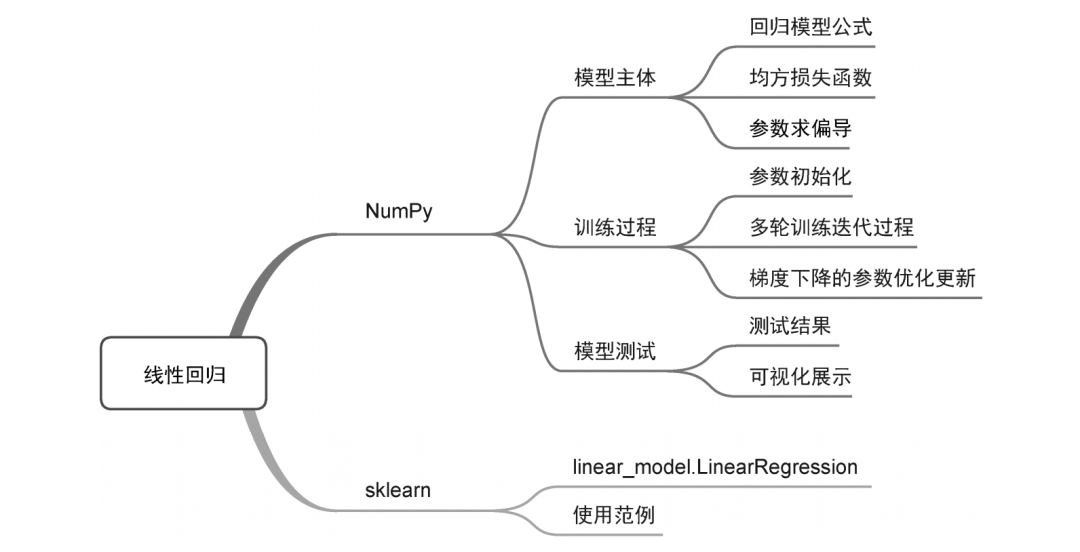
图2-3 线性回归模型代码的编写思路
可以看到,图3提供了两种实现方式。一种是基于Numpy的手动实现,也是本文的重点所在。另一种是调用sklearn机器学习库的实现方式,旨在提供对比参考。
二、基于Numpy的代码实现
首先尝试实现线性回归模型的主体部分,包括回归模型公式、均方损失函数和参数求偏导。线性回归模型主体部分的实现如代码清单2-1所示。

在代码清单2-1中,我们尝试将线性回归模型的主体部分定义为linear_loss函数。该函数的输入参数包括训练数据和权重系数,输出为线性回归模型预测值、均方损失、权重参数一阶偏导和偏置一阶偏导。
在给定模型初始参数的情况下,线性回归模型根据训练数据和参数计算出当前均方损失和参数一阶梯度。
然后在linear_loss函数的基础上,定义线性回归模型的训练过程。主要包括参数初始化、迭代训练和梯度下降寻优。
我们可以先定义一个参数初始化函数initialize_params,再基于linear_loss函数和initialize_params函数来定义包含迭代训练和梯度下降寻优的线性回归拟合过程。
参数初始化函数initialize_params如代码清单2-2所示。

在代码清单2-2中,我们输入训练数据的变量维度,即对于线性回归而言,每一个变量都有一个权重系数。输出为初始化为零向量的权重系数和初始化为零的偏置参数。
最后,我们尝试结合linear_loss和initialize_params函数定义线性回归模型训练过程的函数linear_train,如代码清单2-3所示。


在代码清单2-3中,我们首先初始化模型参数,然后对遍历设置训练迭代过程。在每一次迭代过程中,基于linear_loss函数计算当前迭代的预测值、均方损失和梯度,并根据梯度下降法不断更新系数。
在训练过程中记录每一步的损失、每10000次迭代打印当前损失信息、保存更新后的模型参数字典和梯度字典。这样,一个完整的线性回归模型就基本完成了。
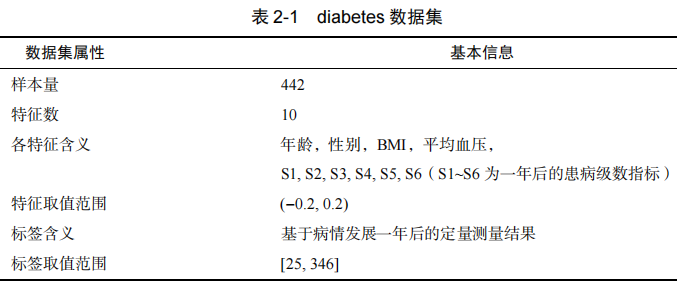
基于上述代码实现,我们使用sklearn的diabetes数据集进行测试,其具体信息如表2-1所示。
从sklearn中导入该数据集并将其划分为训练集和测试集,如代码清单2-4所示。


代码清单2-4首先导入sklearn的diabetes公开数据集,获取数据输入和标签并打乱顺序后划分数据集,输出为:

然后我们使用代码清单2-3定义的linear_train函数训练划分后的数据集,如代码清单2-5所示。
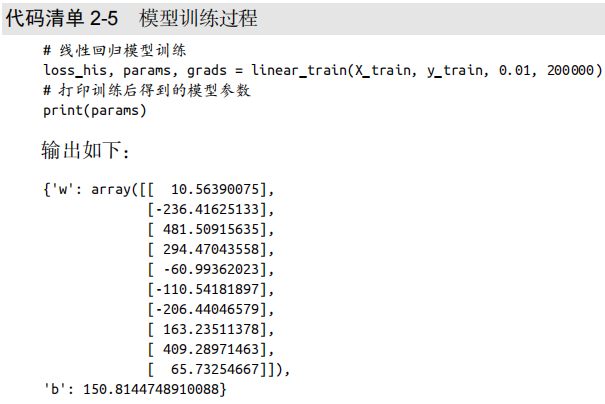
在学习率为0.01、迭代次数为200000的条件下,我们得到上述训练参数。训练中的均方损失下降过程如图2-4所示。
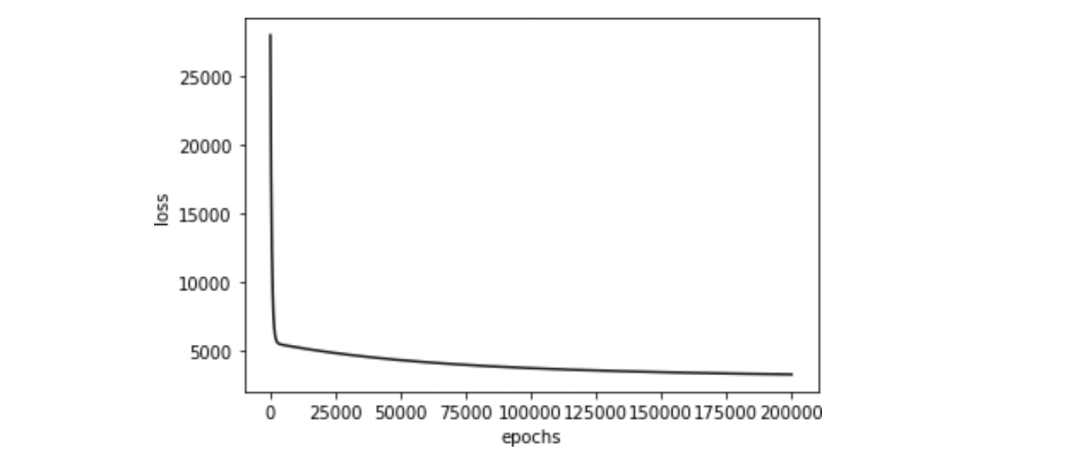
图2-4 训练中的均方损失下降过程
基于前述训练参数,我们可以定义一个预测函数对测试集进行预测,如代码清单2-6所示。

代码清单2-6定义了回归模型的预测函数,输入参数为测试集和模型训练参数,然后通过回归表达式即可进行回归预测。
如何衡量预测结果的好坏呢?
除均方损失外,回归模型的一个重要评估指标是R2系数,用来判断模型拟合水平。我们尝试自定义一个R2系数计算方法,并基于该系数计算代码清单2-6预测结果的拟合水平,具体如代码清单2-7所示。
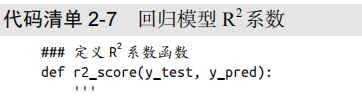

代码清单2-7给出了回归模型R2系数的计算方式。根据总离差平方和、残差平方和以及R2计算公式,我们计算测试集的R2系数。代码清单2-7的输出如下:
0.5334188457463576
可以看到,我们自定义并训练的线性回归模型在该测试集上的R2系数为0.53,结果并不算太好,除了模型的一些超参数需要做一些调整和优化外,可能线性回归模型本身对该数据集拟合效果有限。
三、基于sklearn的模型实现
作为参考对比,这里同样基于sklearn的LinearRegression类给出对于该数据集的拟合效果。LinearRegression函数位于sklearn的linear_model模块下,定义该类的一个线性回归实例后,直接调用其fit方法拟合训练集即可。
参考实现如代码清单2-8所示。

输出如下:

可以看到,在不做任何特征处理的情况下,基于sklearn的线性回归模型在同样的数据集上与我们基于NumPy手写的模型表现差异并不大,这也验证了手写算法的有效性。
本文摘编自《机器学习:公式推导与代码实现》
题图来源 | iStock

图书简介:作为一门应用型学科,机器学习植根于数学理论,落地于代码实现。这就意味着,掌握公式推导和代码编写,方能更加深入地理解机器学习算法的内在逻辑和运行机制。本书在对全部机器学习算法进行分类梳理的基础之上,分别对监督学习单模型、监督学习集成模型、无监督学习模型、概率模型四个大类共26个经典算法进行了细致的公式推导和代码实现,旨在帮助机器学习学习者和研究者完整地掌握算法细节、实现方法以及内在逻辑。


















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









