






LLM Agent 正在变得越来越普及,似乎逐渐取代了我们熟悉的“常规”对话型 LLM。这些令人惊叹的能力并非轻易实现,而是需要许多组件协同工作。
本文通过 60 多张定制化可视化图表,带你深入探索 LLM Agent 领域,了解其核心组件,并进一步探讨多代理框架。
什么是 LLM Agent?
要了解 LLM Agent 是什么,我们首先需要探讨 LLM 的基础能力。传统意义上,LLM 的核心功能只是进行下一个 token 的预测。

通过连续采样多个 token,我们可以模拟对话,并利用 LLM 为我们的问题提供更详尽的答案。

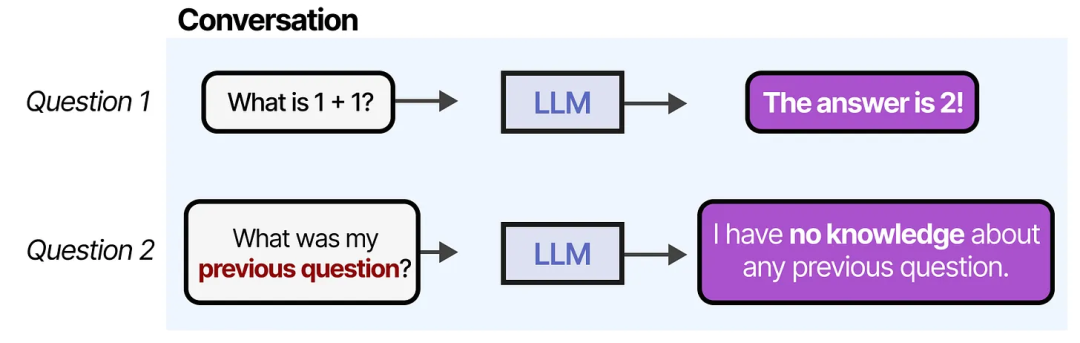
然而,当我们继续“对话”时,任何给定的 LLM 都会暴露其主要缺点之一:它无法记住对话内容!
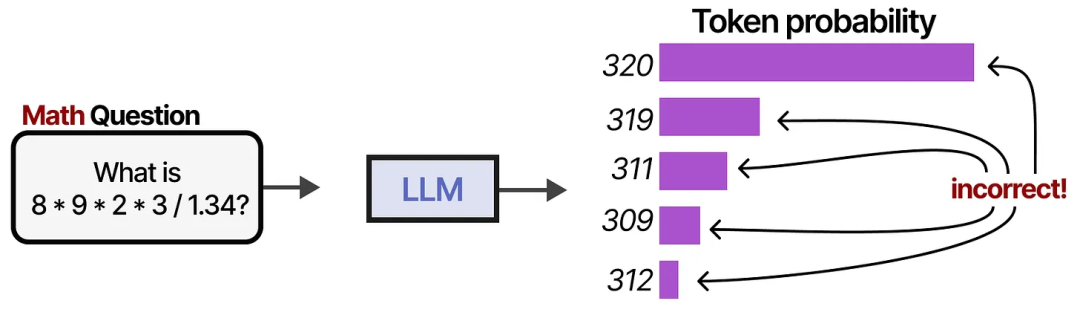
此外,LLM 在许多其他任务上也经常出错,比如基本的数学运算(如乘法和除法):
这是否意味着 LLM 很糟糕?当然不是!我们并不需要 LLM 具备所有能力,因为我们可以通过外部工具、记忆系统和检索系统来弥补其缺陷。
借助外部系统,LLM 的能力可以得到增强。Anthropic 将这种方式称为“增强型 LLM”(The Augmented LLM)。
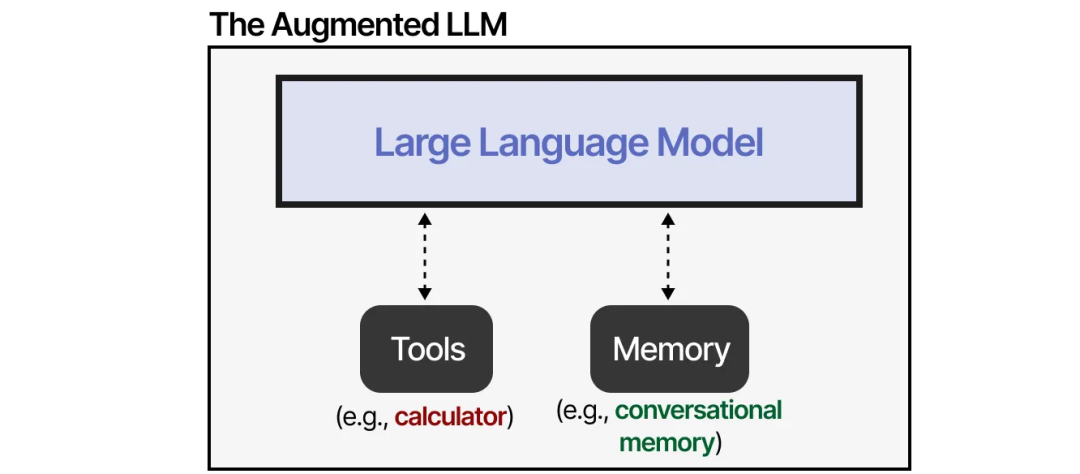
例如,当面对一个数学问题时,LLM 可能会选择使用适当的工具(如计算器)。
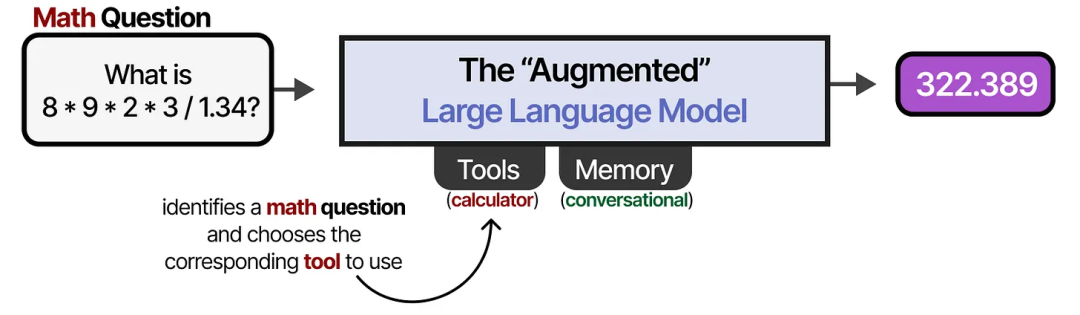
那么,这种“增强型 LLM”算是一个 Agent 吗?不算,但也可以说稍微算是……
让我们从 Agent 的定义开始:
“一个 Agent 可以被视为通过传感器感知环境,并通过执行器对环境采取行动的任何事物。”
—— Russell & Norvig,《人工智能:一种现代方法》(2016)
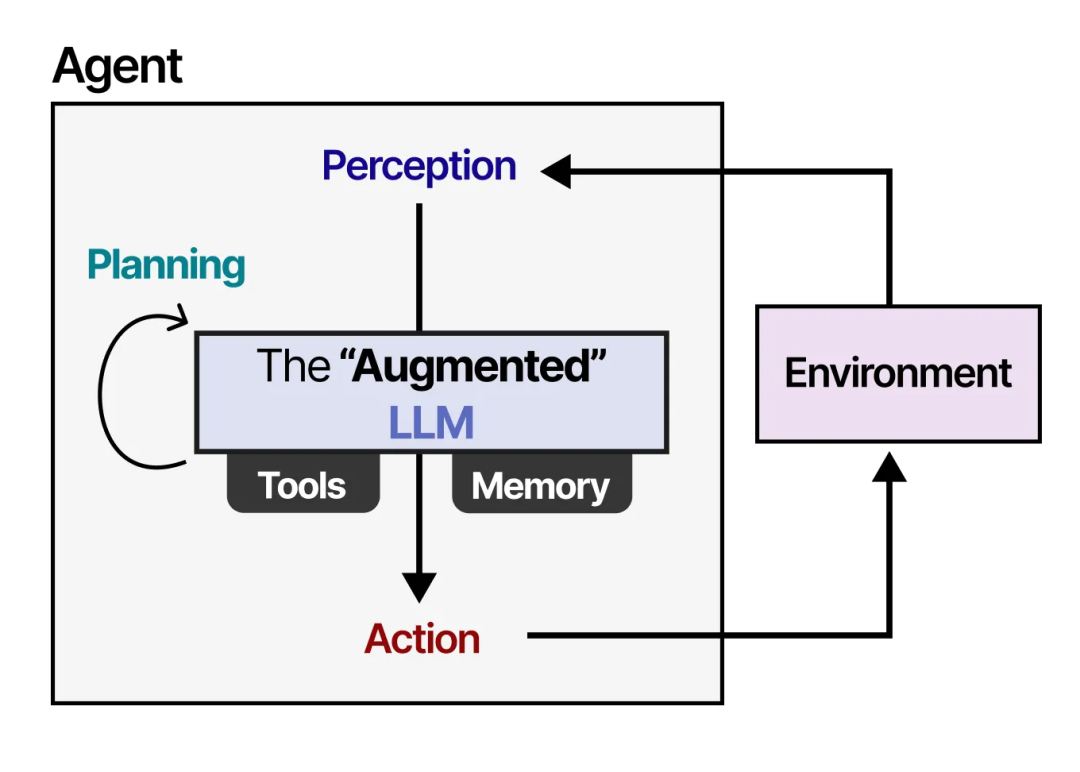
Agent 会与环境交互,通常由几个重要组成部分构成:
Environments(环境) —— Agent 所交互的世界
Sensors(传感器) —— 用于观察环境
Actuators(执行器) —— 用于与环境交互的工具
Effectors(效应器) —— 决定如何从观察到行动的“思维”或规则
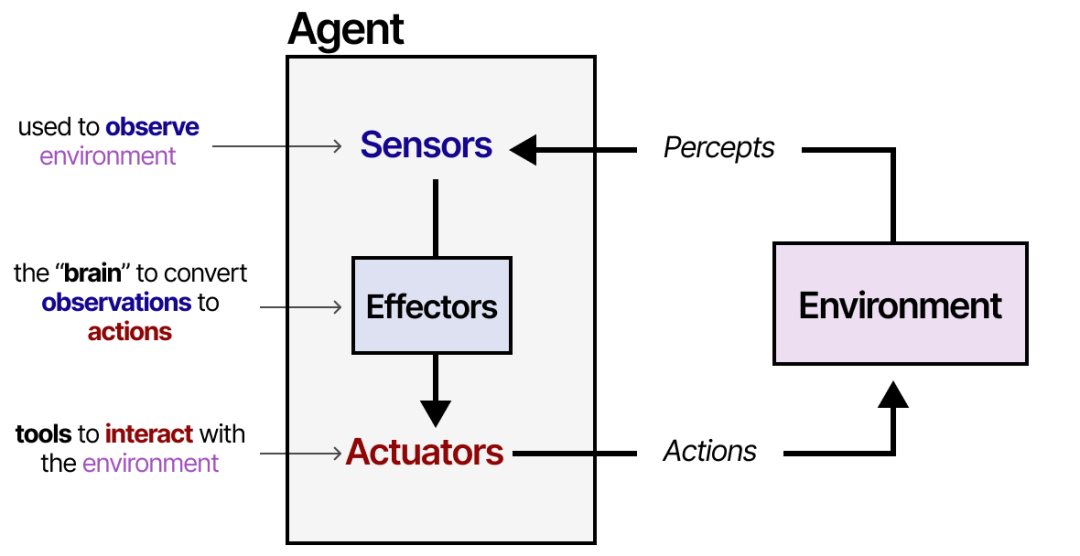
这一框架适用于所有与各种环境交互的 Agent,例如机器人与物理环境交互,或 AI Agent 与软件交互。
我们可以稍微泛化这一框架,使其适用于“增强型 LLM”。
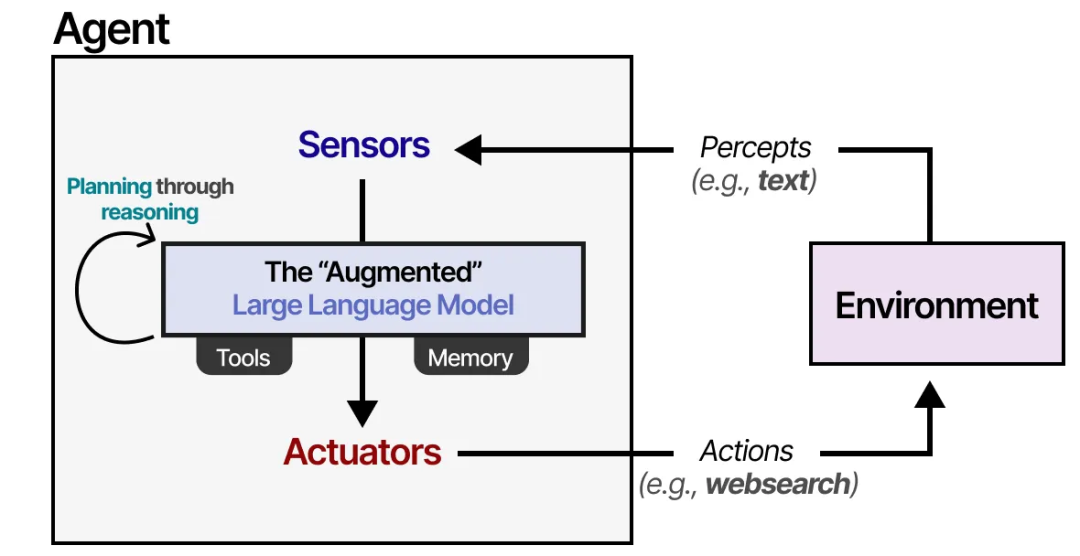
通过“增强型 LLM”,Agent 可以通过文本输入观察环境(因为 LLM 通常是基于文本的模型),并通过使用工具(如搜索网络)执行某些操作。
为了选择需要采取的操作,LLM Agent 有一个关键组件:它的规划能力。为此,LLM 需要能够通过链式思维(chain-of-thought)等方法进行“推理”和“思考”。
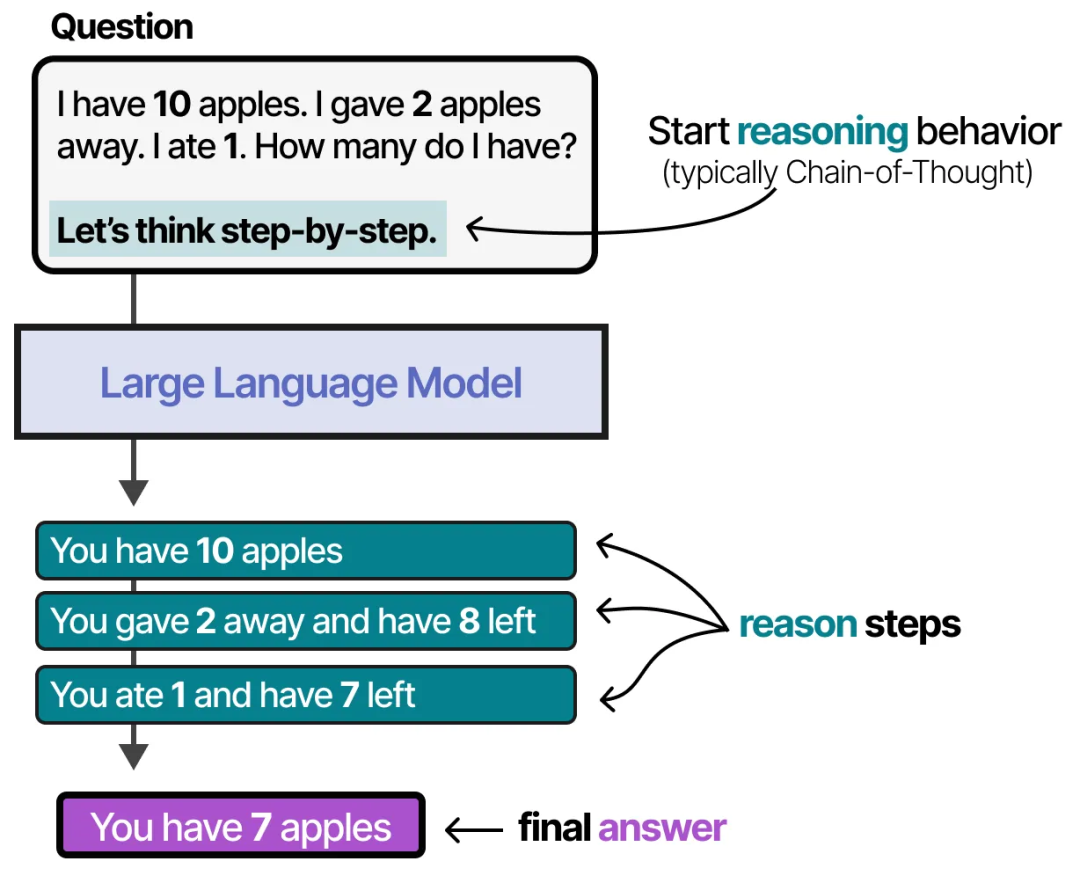
通过这种推理行为,LLM Agent 可以规划出需要执行的操作。
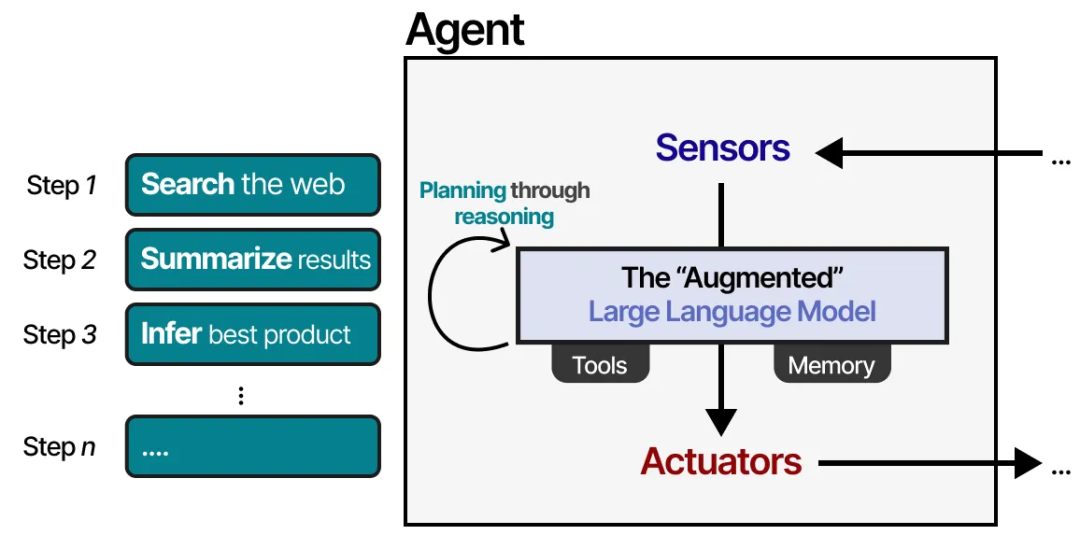
这种规划行为使 Agent 能够理解当前情境(LLM)、规划下一步行动(规划)、执行操作(工具),并跟踪已采取的行动(记忆)。
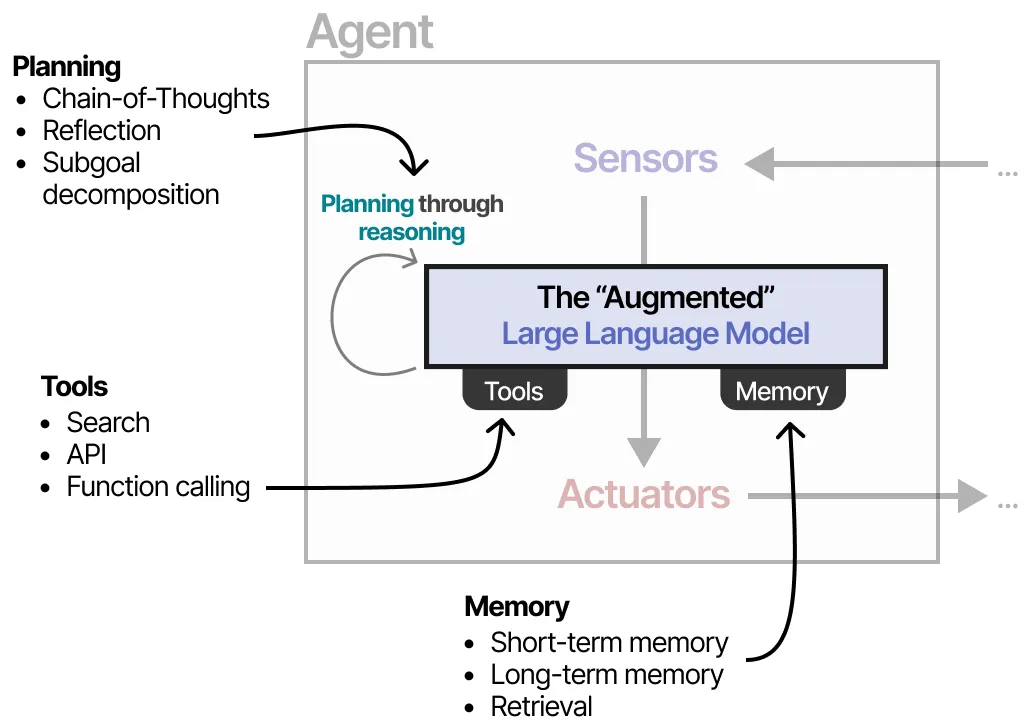
根据系统的设计,LLM Agent 可以具有不同程度的自主性。
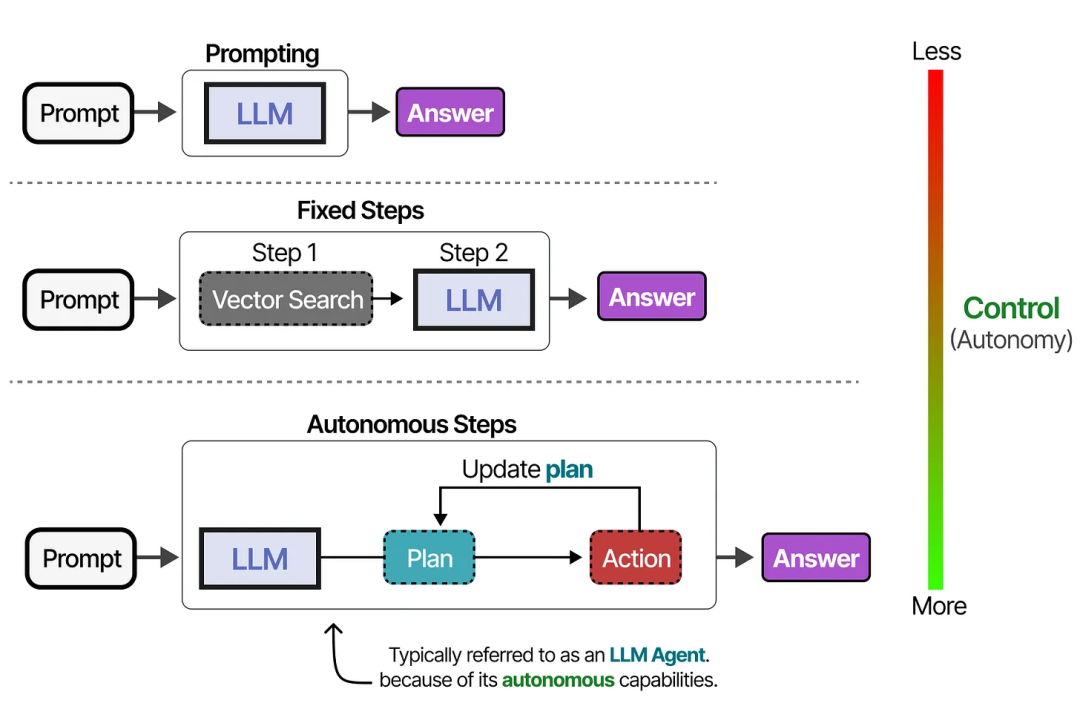
根据不同的观点,系统越多地依赖 LLM 来决定其行为方式,就越“像 Agent”。
在接下来的章节中,我们将通过 LLM Agent 的三个主要组成部分——记忆、工具和规划,来探讨各种实现自主行为的方法。
记忆
LLM 是遗忘型系统,或者更准确地说,在与其交互时,它并不会执行任何记忆存储的功能。
例如,当你向 LLM 提出一个问题后,再跟进另一个问题,它不会记得之前的问题内容。
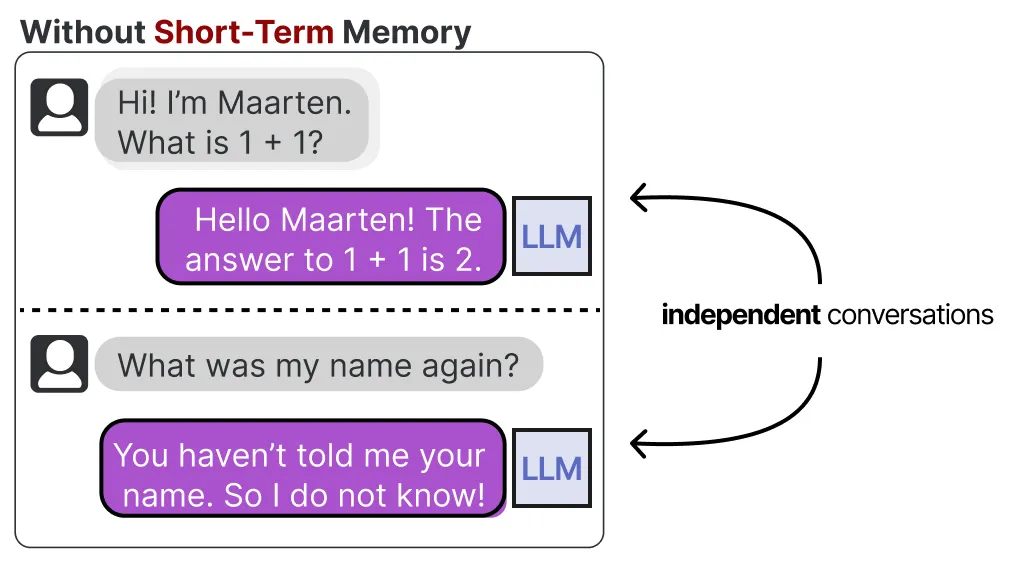
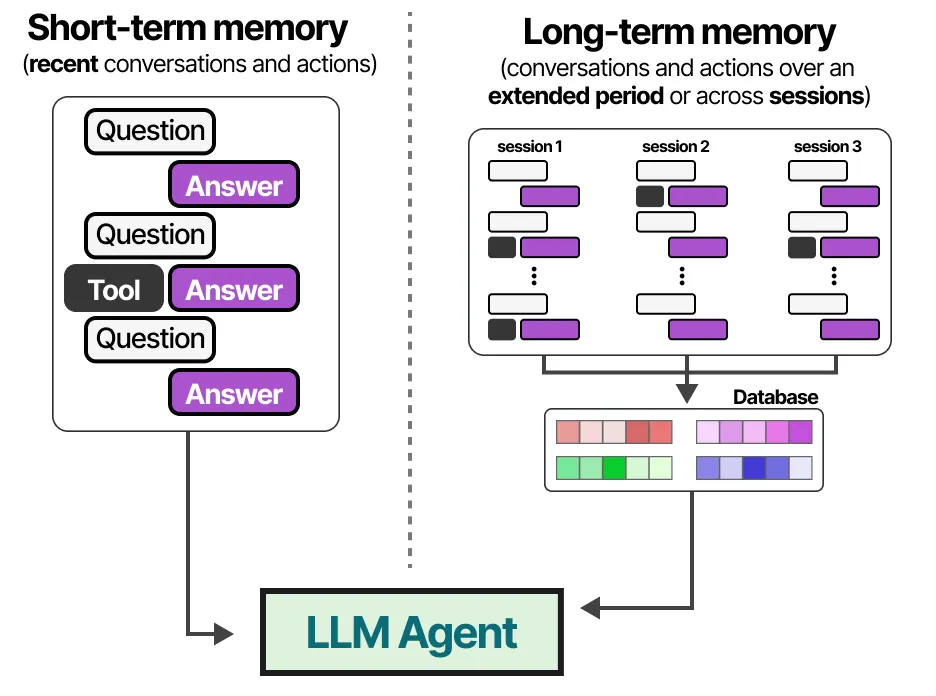
我们通常将这种记忆称为短期记忆,也叫工作记忆,它起到一个缓冲区的作用,用于存储(几乎)即时的上下文信息。这包括 LLM Agent 最近执行的操作。
然而,LLM Agent 还需要能够跟踪可能几十步的操作,而不仅仅是最近的行动。
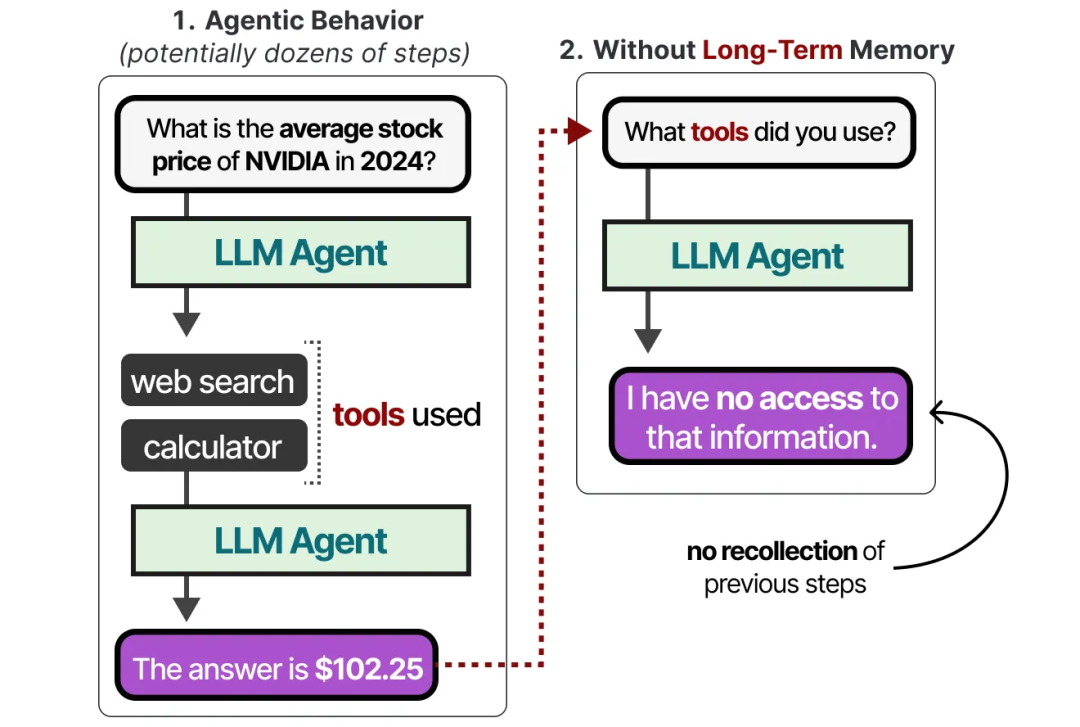
这被称为长期记忆,因为理论上 LLM Agent 可能需要记录几十甚至上百步的操作。
接下来,让我们探讨几种为这些模型提供记忆的方法。
短期记忆
为模型启用短期记忆最直接的方法是利用模型的上下文窗口(context window),也就是 LLM 能够处理的 token 数量。
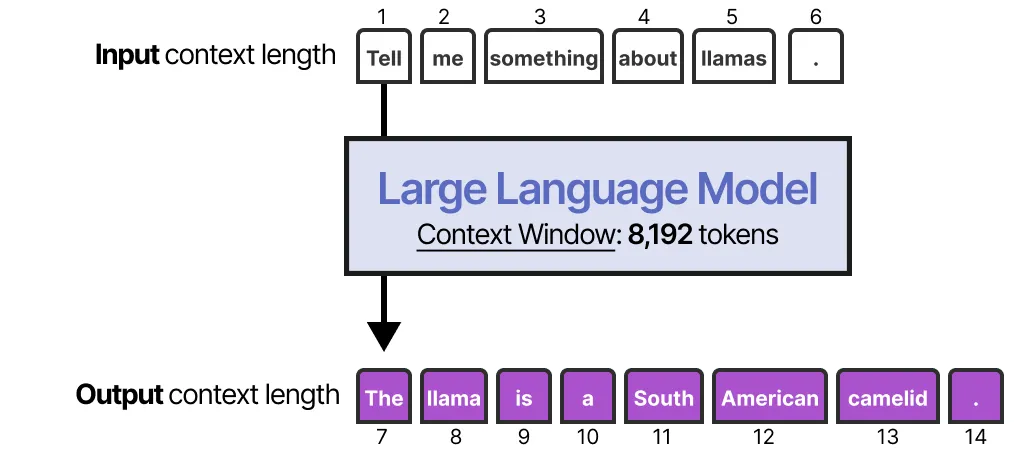
上下文窗口通常至少为 8192 个 token,有时甚至可以扩展到数十万 token!
较大的上下文窗口可以将完整的对话历史作为输入提示的一部分,从而实现对话跟踪。
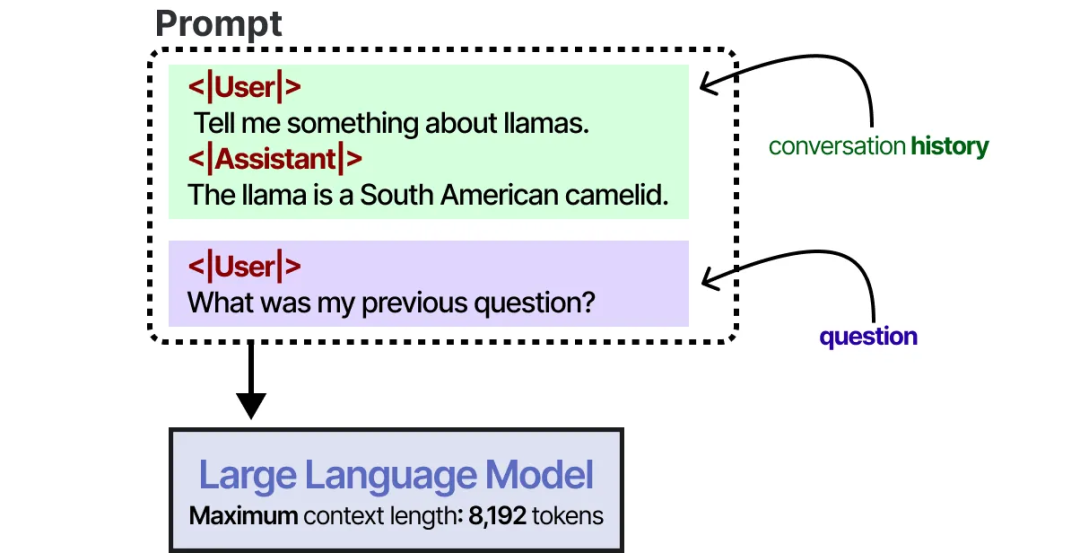
只要对话历史能被包含在 LLM 的上下文窗口内,这种方式就是一种模仿记忆的不错方法。然而,与其说是实际记住对话,不如说我们是通过输入“告知” LLM 对话的内容。
对于上下文窗口较小的模型,或者当对话历史过多时,我们可以改用另一个 LLM 来总结迄今为止发生的对话内容。
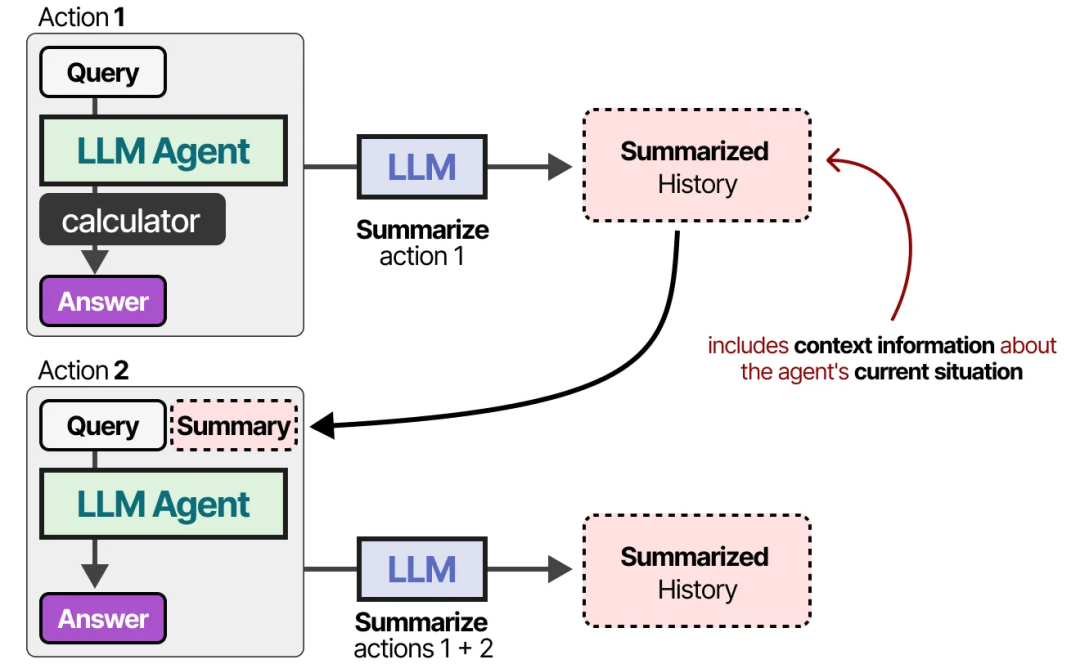
通过不断总结对话,我们可以使对话内容保持较小的规模。这种方式能够减少 token 的数量,同时只保留最重要的信息。
长期记忆
LLM Agent 的长期记忆包括需要在较长时间内保留的过去操作记录。
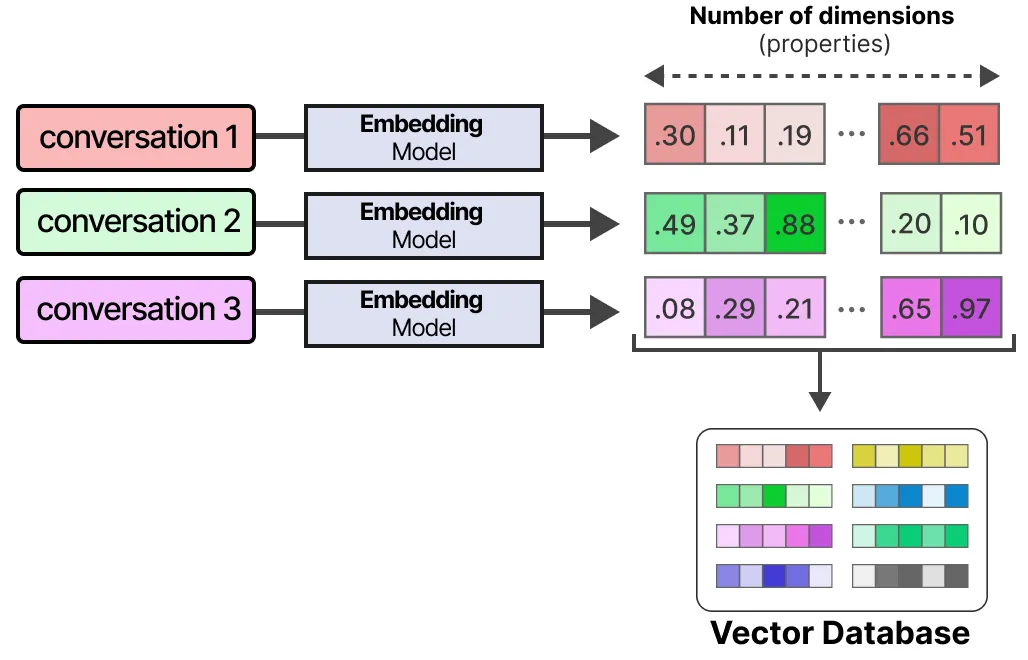
一种常见的启用长期记忆的方法是将所有过去的交互、操作和对话存储在一个外部向量数据库中。
构建这样的数据库时,首先需要将对话内容嵌入为能够捕捉其语义的数值表示。
构建数据库后,我们可以将任何给定的提示(prompt)嵌入为向量表示,并通过与数据库中的嵌入向量进行比较,找到最相关的信息。
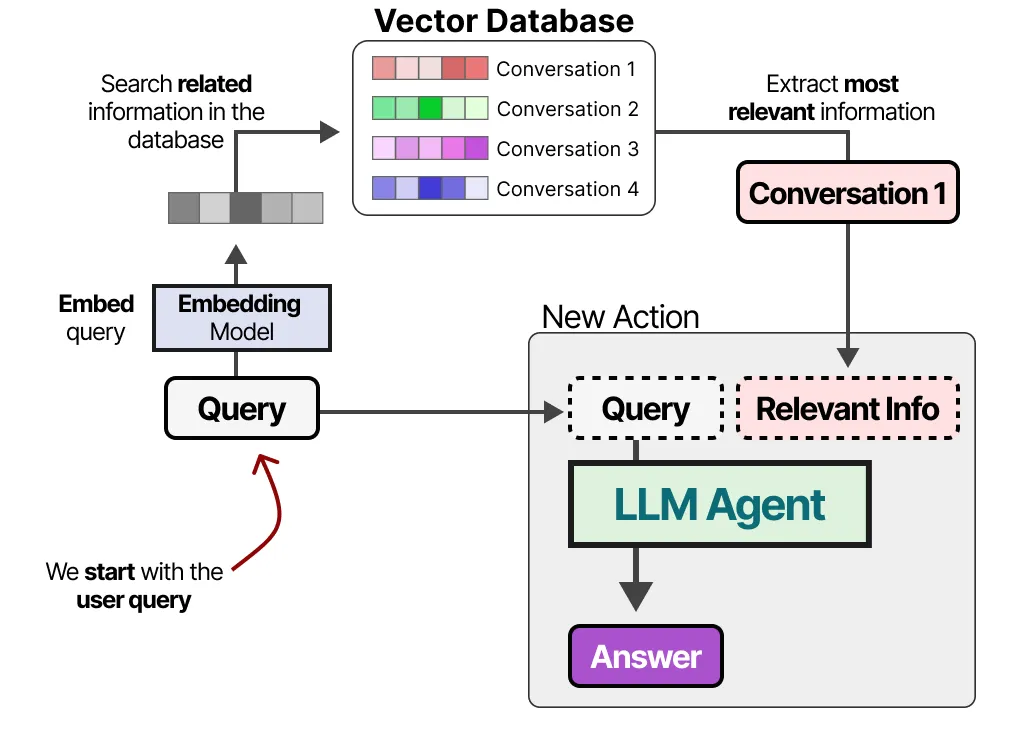
这种方法通常被称为 Retrieval-Augmented Generation(RAG)。
长期记忆还可以涉及跨会话保留信息。例如,你可能希望 LLM Agent 记住它在之前会话中完成的研究内容。
此外,不同类型的信息可以对应于不同类型的记忆进行存储。在心理学中,有许多记忆类型的划分,而 Cognitive Architectures for Language Agents 论文将其中的四种类型与 LLM Agent 相关联。

这种区分有助于构建具备代理能力的框架。例如,语义记忆(关于世界的事实)可以存储在与工作记忆(当前和最近的情况)不同的数据库中。
工具
工具使 LLM 能够与外部环境(如数据库)进行交互,或者使用外部应用程序(如运行自定义代码)。

工具通常有两种使用场景:一是获取数据以检索最新信息,二是执行操作,比如安排会议或订餐。
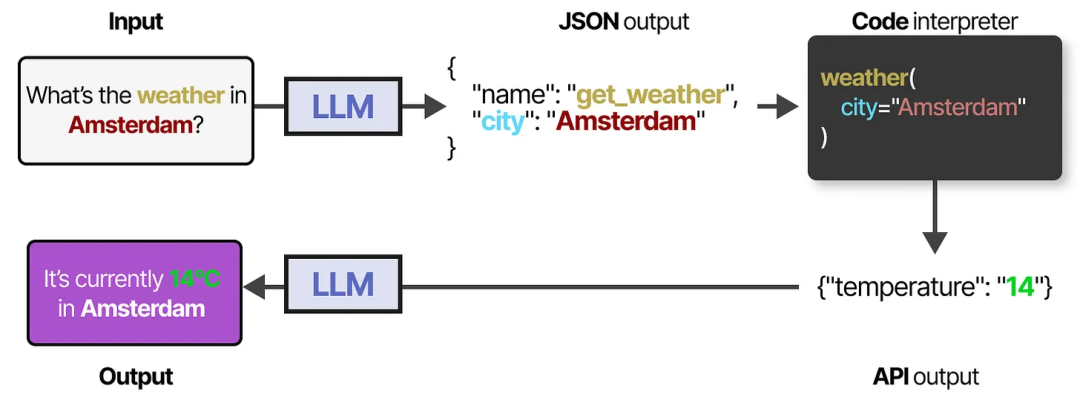
为了实际使用某个工具,LLM 需要生成与该工具 API 兼容的文本。我们通常期望生成可以格式化为 JSON 的字符串,这样可以轻松地将其传递给代码解释器。
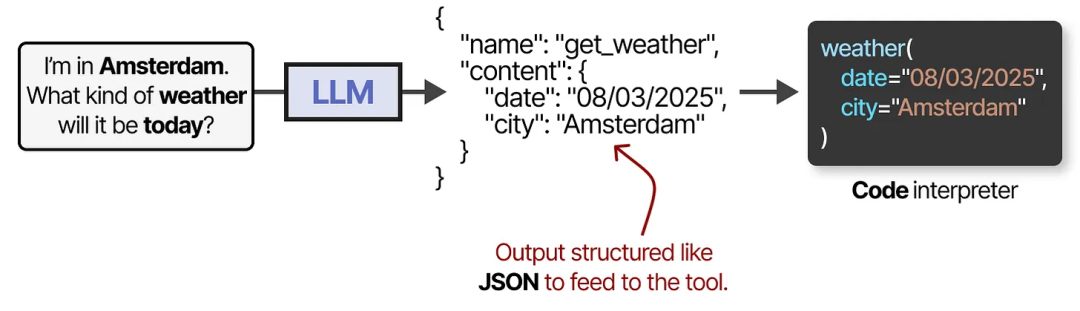
需要注意的是,这种方式并不限于 JSON,我们还可以直接在代码中调用工具!
你还可以生成供 LLM 使用的自定义函数,例如一个简单的乘法函数。这通常被称为函数调用(function calling)。
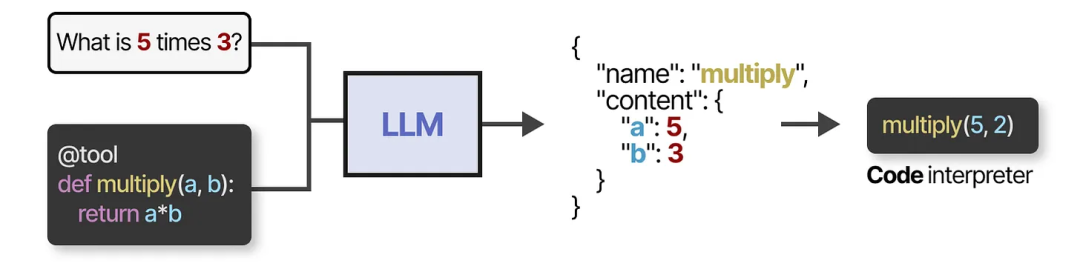
一些 LLM 如果提示得足够准确和全面,几乎可以使用任何工具。目前大多数主流的 LLM 都具备这种工具使用能力。
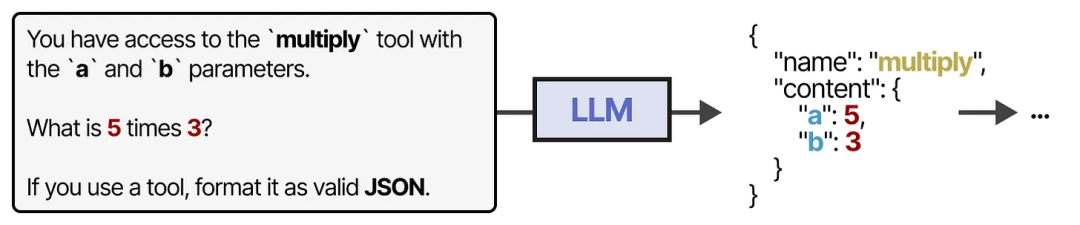
一种更稳定的工具访问方法是通过对 LLM 进行微调(后续会详细介绍这一点!)。
工具的使用可以按照固定的顺序进行(如果代理框架是固定的)……
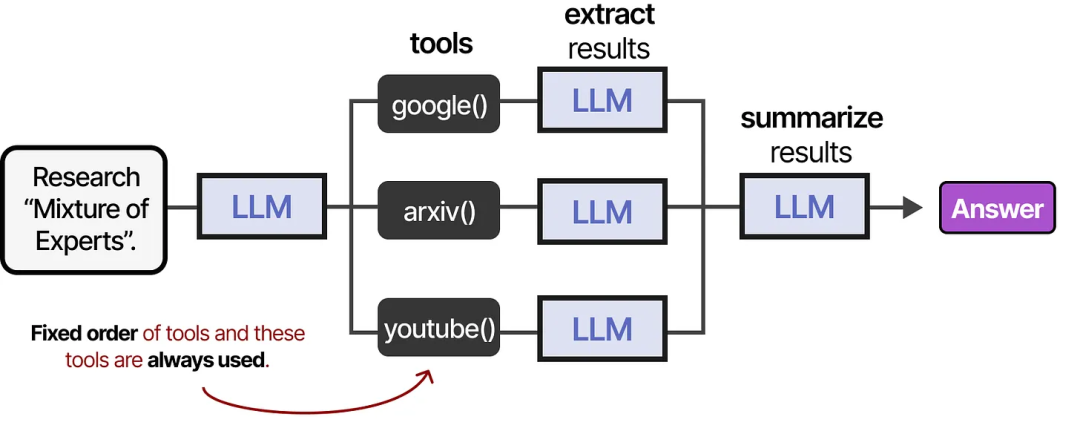
……也可以由 LLM 自主决定使用哪个工具以及何时使用。像上图中的 LLM Agent,实际上是由一系列 LLM 调用组成的(但具备自主选择操作/工具等的能力)。
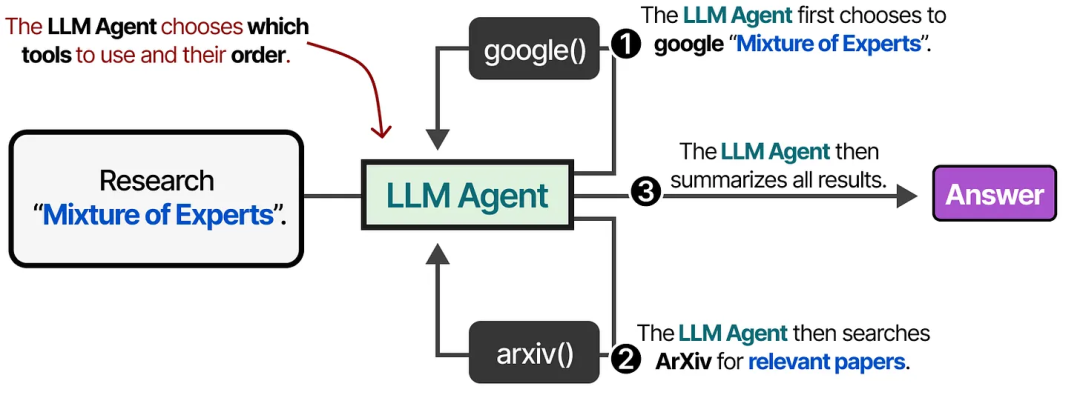
换句话说,中间步骤的输出会被反馈回 LLM,以继续后续处理。
Toolformer
工具使用是一种增强 LLM 能力并弥补其缺陷的强大技术。因此,近年来关于工具使用和学习的研究工作发展迅速。
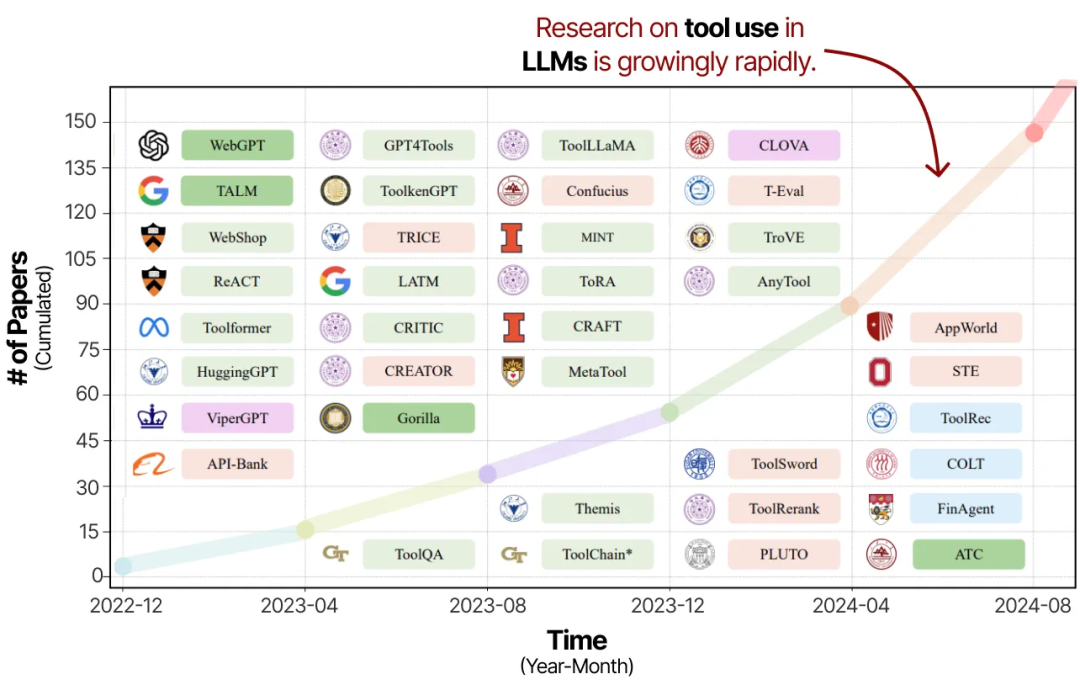 “Tool Learning with Large Language Models: A Survey” 论文图片表明,随着对工具使用的关注不断增加,(Agentic)LLMs 预计将变得更加强大。
“Tool Learning with Large Language Models: A Survey” 论文图片表明,随着对工具使用的关注不断增加,(Agentic)LLMs 预计将变得更加强大。
这项研究的重点不仅在于通过提示让 LLM 使用工具,还在于专门训练它们如何使用工具。
其中一个最早提出的技术叫做 Toolformer,这是一种能够决定调用哪些 API 以及如何调用的模型。
它通过使用 [ 和 ] 符号来表示调用工具的开始和结束。例如,当给出一个提示 “5 乘以 3 等于多少?” 时,模型会生成令牌,直到遇到 [ 符号为止。

接下来,它会生成令牌直到遇到 → 符号,这表示 LLM 停止生成令牌。

随后,工具会被调用,其输出将被加入到目前为止生成的令牌中。
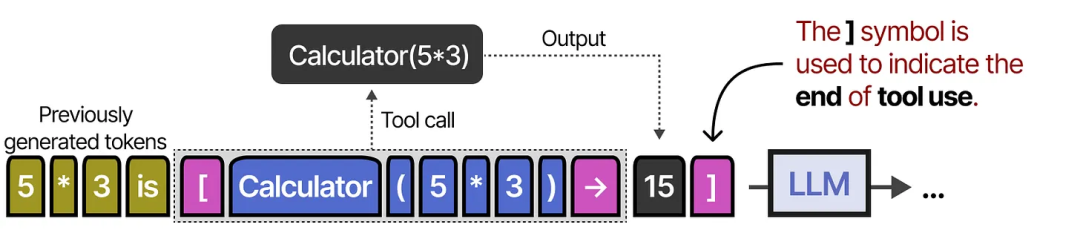
当遇到 ] 符号时,表示 LLM 可以继续生成后续内容(如果需要)。
Toolformer 通过精心生成包含大量工具使用场景的数据集来实现这种行为。对于每个工具,手动创建一个 few-shot 提示,并用它来采样包含这些工具使用的输出结果。
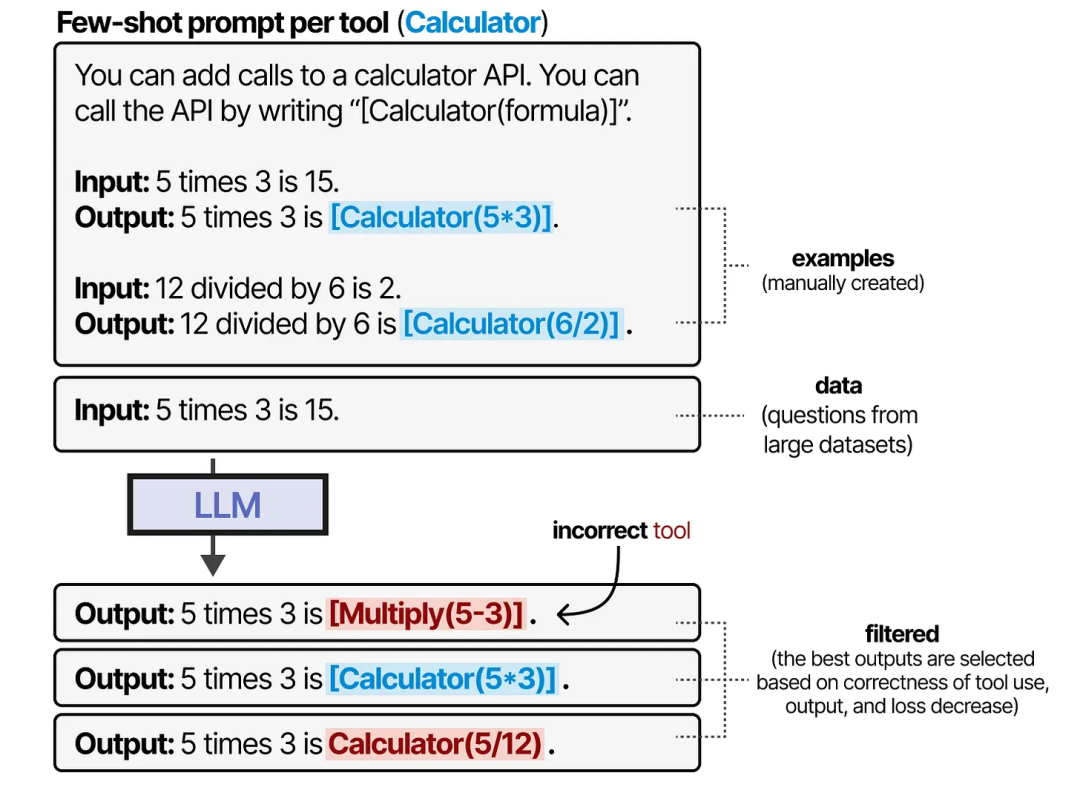
工具的输出会根据工具使用的正确性、输出结果以及损失降低情况进行过滤。最终生成的数据集被用来训练一个 LLM,使其遵循这种工具使用的格式。
自 Toolformer 发布以来,已经出现了许多令人兴奋的新技术,例如可以使用数千种工具的 LLM(如 ToolLLM)或能够轻松检索最相关工具的 LLM(如 Gorilla)。
无论哪种方式,目前大多数 LLM(截至 2025 年初)都已经被训练得可以通过 JSON 生成轻松调用工具(正如之前提到的那样)。
模型上下文协议(Model Context Protocol,MCP)
工具是 Agentic 框架中的一个重要组件,它允许 LLM 与世界互动并扩展其能力。然而,当你有许多不同的 API 时,启用工具使用变得麻烦,因为任何工具都需要:
手动追踪并提供给 LLM
手动描述(包括其预期的 JSON 结构)
在其 API 发生变化时手动更新
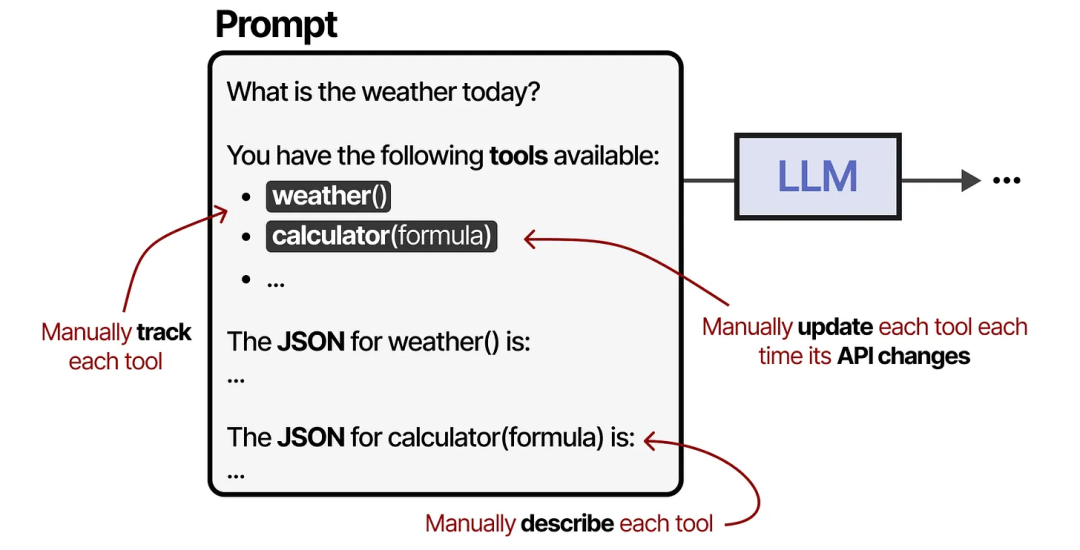
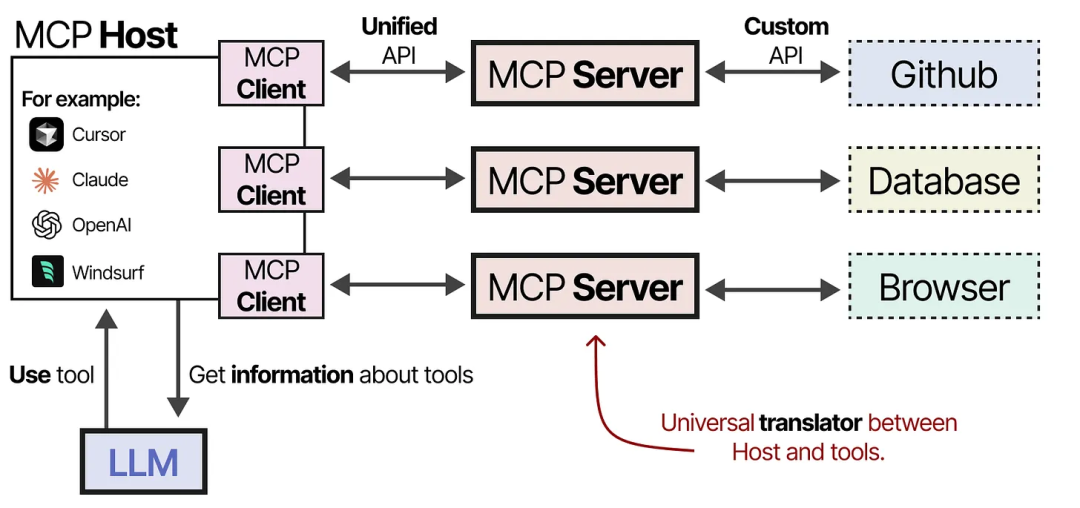
为了使工具在任何给定的 Agentic 框架中更容易实现,Anthropic 开发了模型上下文协议(Model Context Protocol,MCP)。MCP 对天气应用、GitHub 等服务的 API 访问进行了标准化。
它由三个组件构成:
MCP Host — 管理连接的 LLM 应用程序(例如 Cursor)
MCP Client — 与 MCP 服务器保持 1:1 的连接
MCP Server — 为 LLM 提供上下文、工具和功能
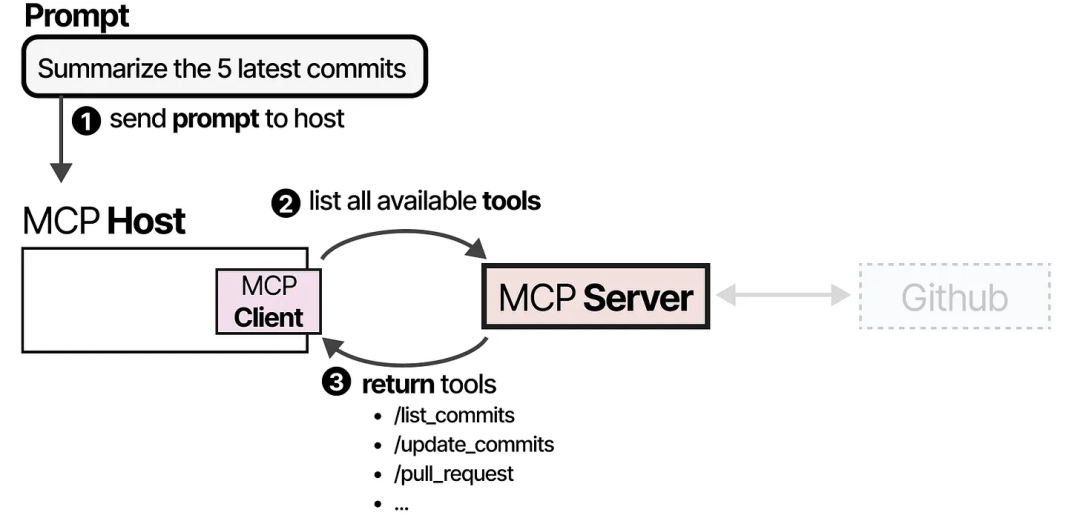
例如,假设你想让某个 LLM 应用程序总结你代码仓库中最新的 5 次提交。
MCP Host(与客户端一起)会首先调用 MCP Server,询问有哪些工具可用。
LLM 接收到信息后,可以选择使用某个工具。它通过 Host 向 MCP Server 发送请求,然后接收结果,结果中包括所使用的工具。
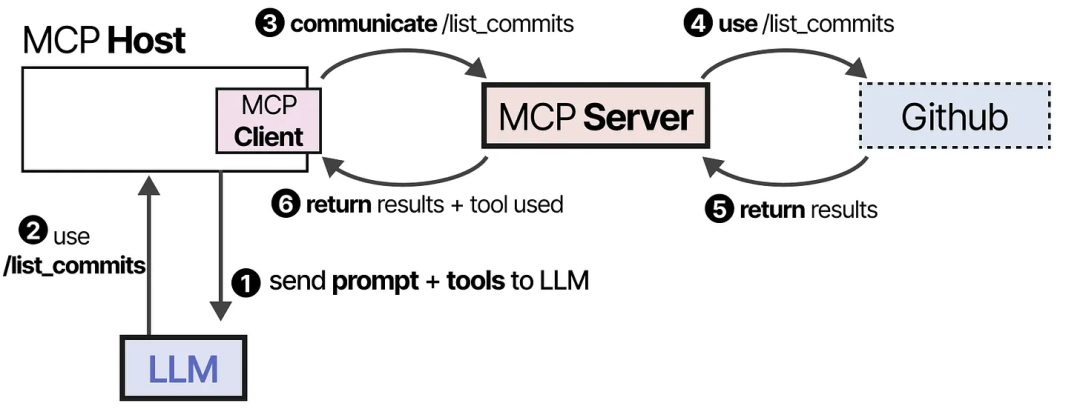
最后,LLM 接收到结果,并解析出一个答案返回给用户。
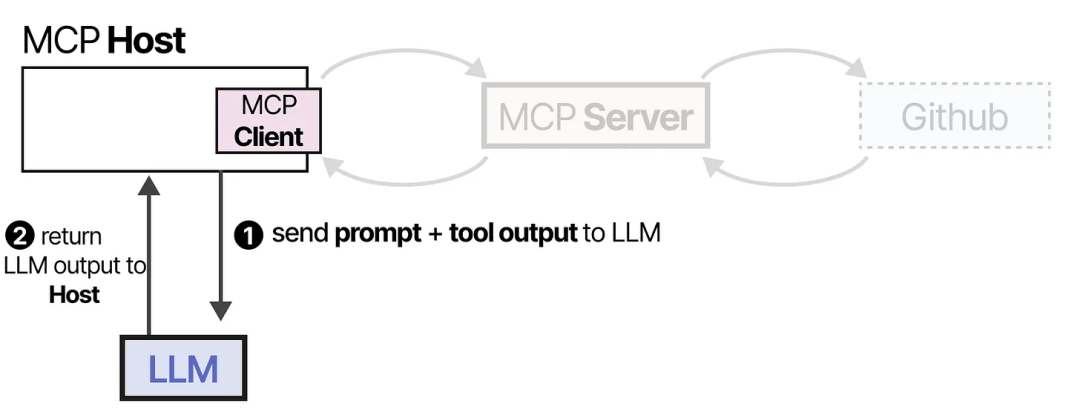
这个框架通过连接到任何 LLM 应用程序都可以使用的 MCP 服务器,使工具的创建变得更加容易。因此,当你创建一个与 Github 交互的 MCP 服务器时,任何支持 MCP 的 LLM 应用程序都可以使用它。
规划
工具的使用可以让 LLM 提升其能力。这些工具通常通过类似 JSON 的请求来调用。
但是,在一个 Agentic 系统中,LLM 如何决定使用哪个工具以及何时使用呢?
这就涉及到了规划。在 LLM Agent 中,规划指的是将给定任务分解为可操作的步骤。
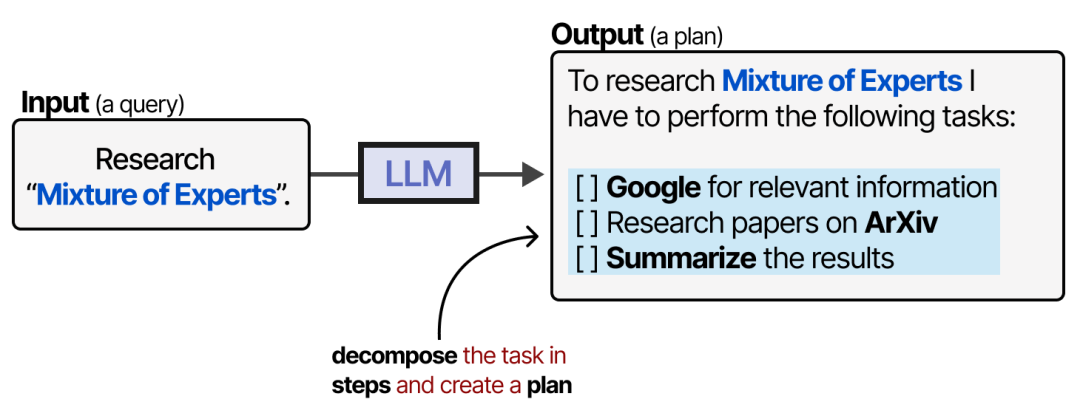
这个计划使模型能够不断反思过去的行为,并在必要时更新当前计划。

为了在 LLM Agent 中实现规划,我们首先需要了解这项技术的基础,即推理。
推理
规划可操作步骤需要复杂的推理行为。因此,在完成任务规划的下一步之前,LLM 必须能够展示出这种行为。
“推理型” LLM 是指那些在回答问题之前倾向于“思考”的模型。
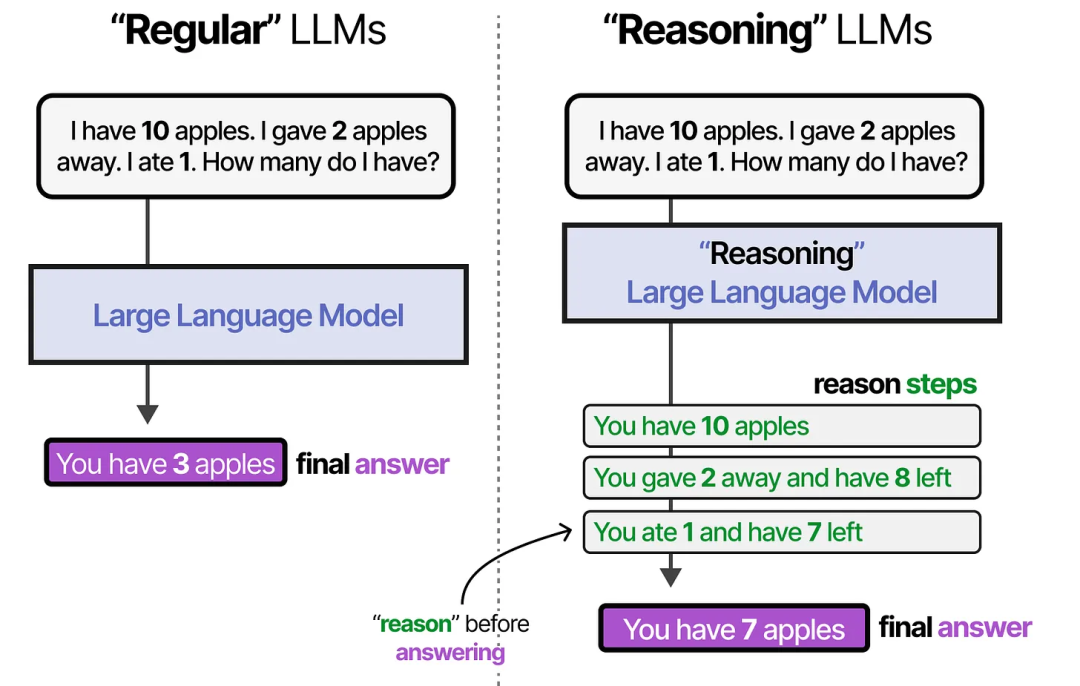
我在这里对“推理”和“思考”这两个词的使用稍微宽松一些,因为我们可以讨论这是否更像是人类的思考过程,还是仅仅将答案分解为结构化的步骤。
这种推理行为大致可以通过两种方式实现:对 LLM 进行微调或特定的提示工程。
通过提示工程,我们可以创建 LLM 应遵循的推理过程示例。提供示例(也称为少量示例提示,few-shot prompting)是一种引导 LLM 行为的绝佳方法。
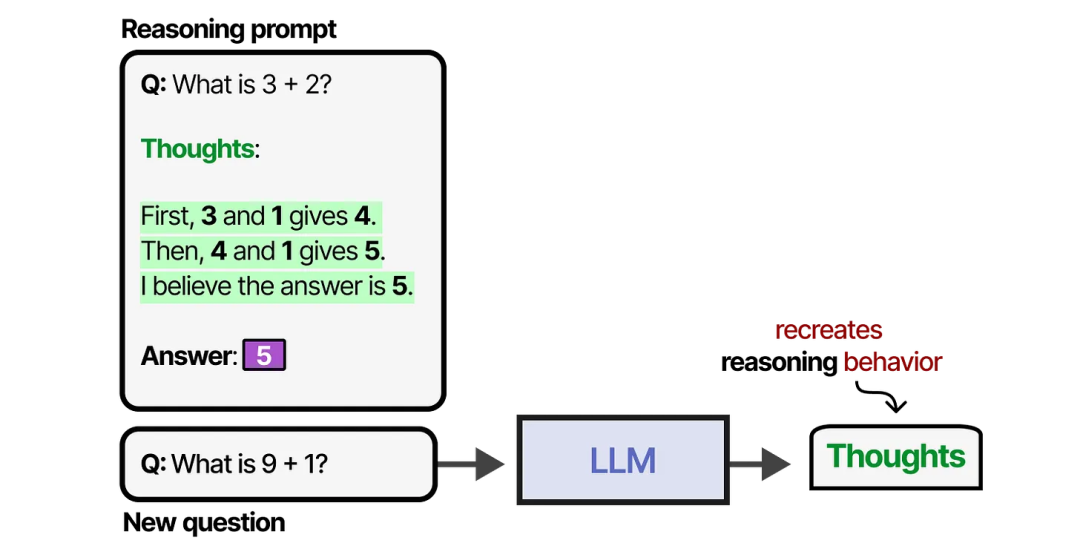
这种提供思维过程示例的方法被称为思维链(Chain-of-Thought),它能够实现更复杂的推理行为。
即使不提供任何示例(零示例提示,zero-shot prompting),也可以通过简单地说“让我们一步一步来思考”来启用思维链。

在训练 LLM 时,我们可以为其提供包含类似思维过程的足够多的数据集,或者让 LLM 自己发现其思维过程。
一个很好的例子是 DeepSeek-R1,它通过奖励机制来引导思维过程的使用。
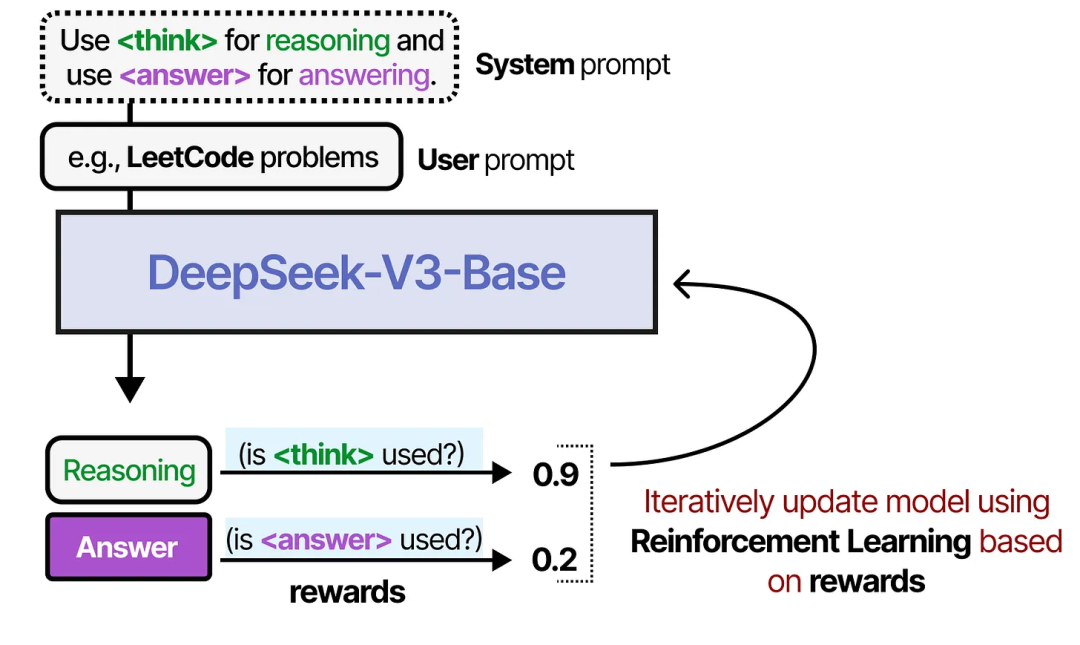
推理与行动
在 LLM 中启用推理行为固然很好,但这并不一定使其能够规划出可操作的步骤。
我们目前关注的技术要么展示推理行为,要么通过工具与环境交互。

例如,思维链(Chain-of-Thought)纯粹专注于推理。
最早将这两个过程结合起来的技术之一被称为 ReAct(Reason and Act)。
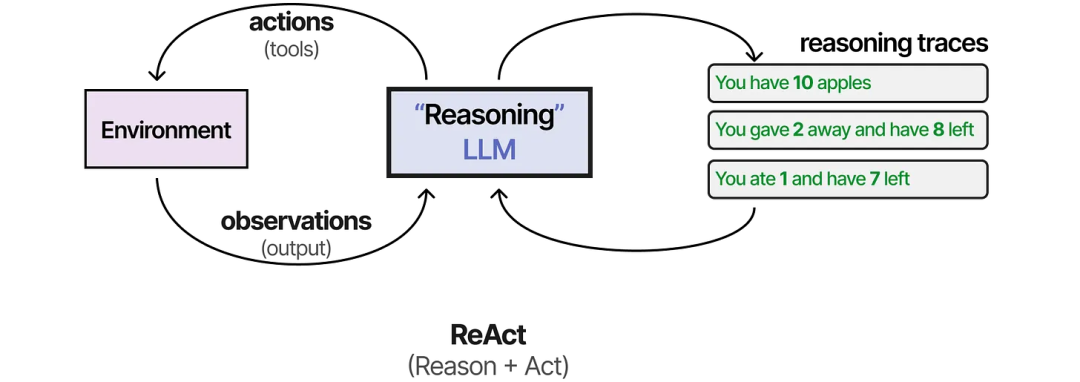
ReAct 通过精心设计的提示工程来实现这一点。ReAct 提示描述了三个步骤:
思考(Thought)- 针对当前情况的推理步骤
行动(Action)- 要执行的一组动作(例如,工具)
观察(Observation)- 针对行动结果的推理步骤
这个提示本身非常简单明了。

LLM 使用这个提示(可以用作系统提示)来引导其行为,以循环的方式进行思考、行动和观察。
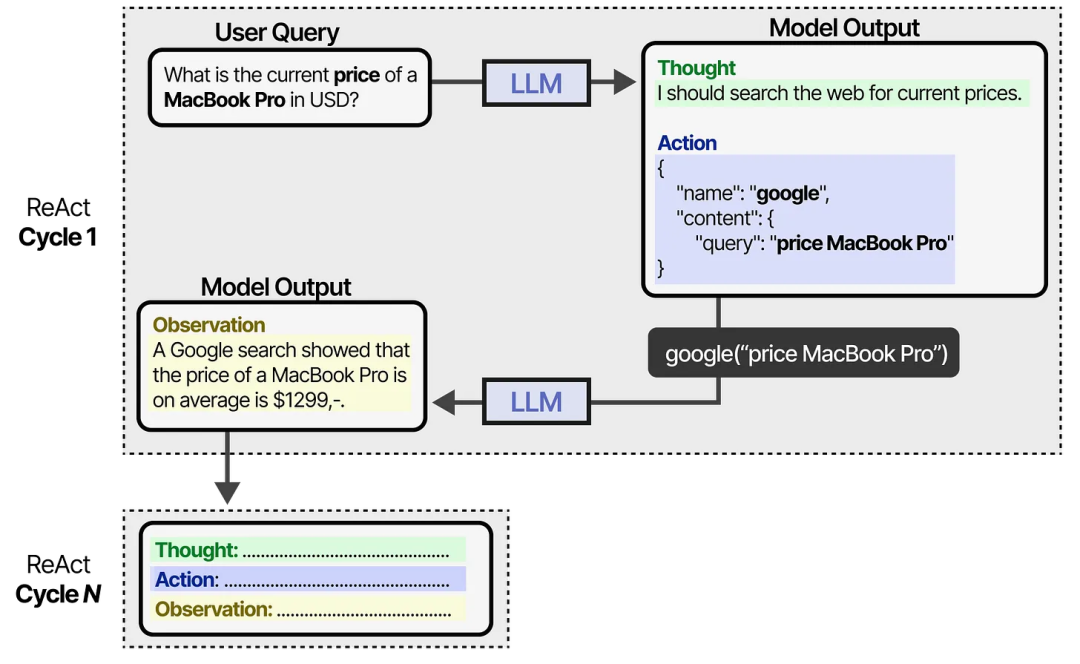
它会持续这种行为,直到某个动作指定返回结果为止。通过不断迭代思考和观察,LLM 可以规划行动、观察输出并相应调整。
因此,与具有预定义和固定步骤的 Agent 相比,这一框架使 LLM 能够表现出更具自主性的代理行为。
反思
没有人,即使是具备 ReAct 的 LLM,也并非每次都能完美完成任务。失败是过程的一部分,只要你能对这个过程进行反思。
这正是 ReAct 所缺少的部分,而 Reflexion 技术弥补了这一不足。Reflexion 是一种利用语言强化来帮助代理从先前失败中学习的技术。
该方法假设了三种 LLM 角色:
执行者(Actor)- 根据状态观察选择并执行动作。我们可以使用诸如 Chain-of-Thought 或 ReAct 等方法。
评估者(Evaluator)- 对执行者产生的输出进行评分。
自我反思(Self-reflection)- 反思执行者采取的动作以及评估者生成的评分。
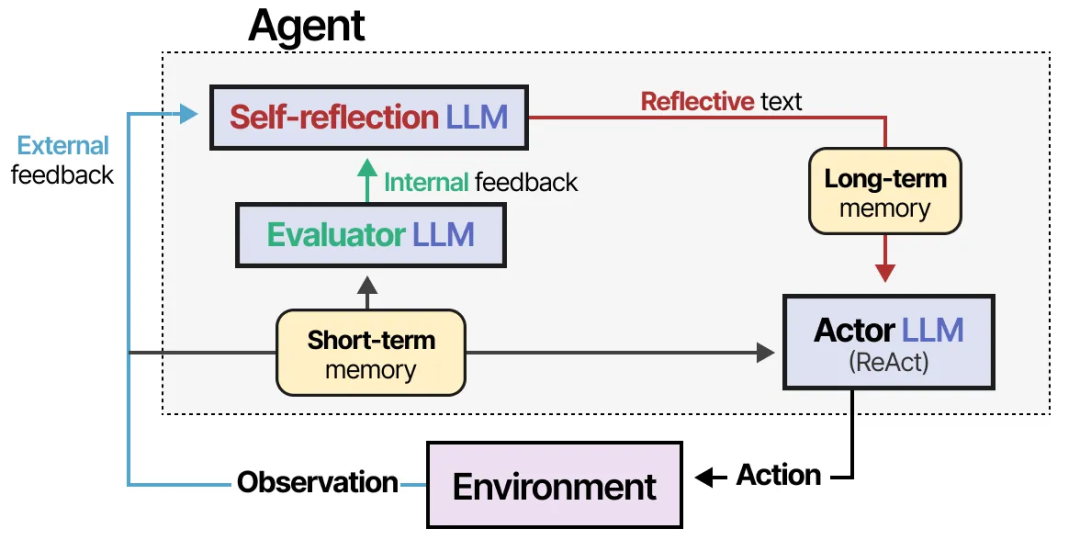
添加了记忆模块来跟踪动作(短期)和自我反思(长期),帮助代理从错误中学习并识别改进的行动。
一个类似且优雅的技术称为 SELF-REFINE,其中对输出进行优化和生成反馈的动作被反复执行。
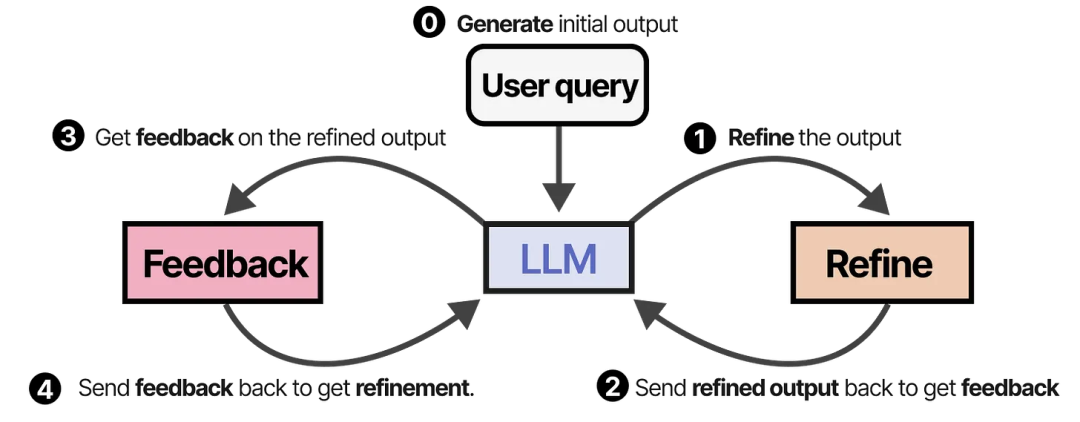
同一个 LLM 负责生成初始输出、优化后的输出以及反馈。
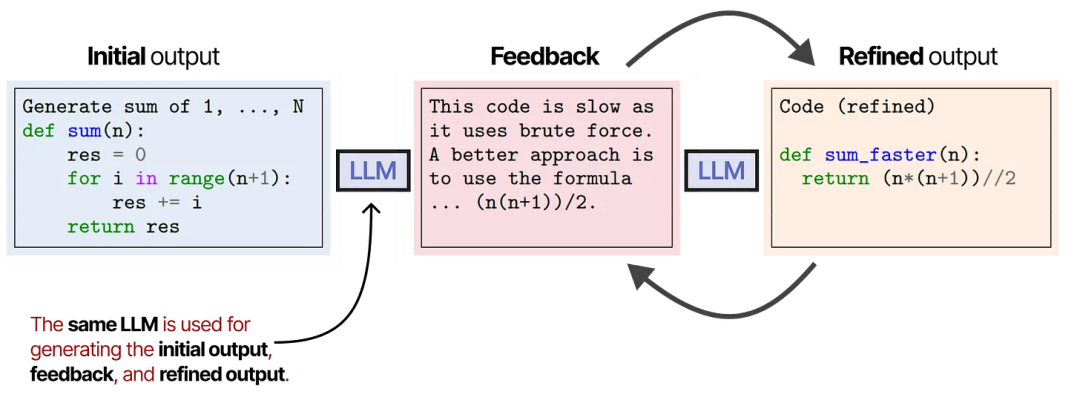 “SELF-REFINE: Iterative Refinement with Self-Feedback”论文中的注释图。
“SELF-REFINE: Iterative Refinement with Self-Feedback”论文中的注释图。
有趣的是,这种自我反思行为,无论是 Reflexion 还是 SELF-REFINE,都与强化学习的行为非常相似,即根据输出质量给予奖励。
多代理协作(Multi-Agent Collaboration)
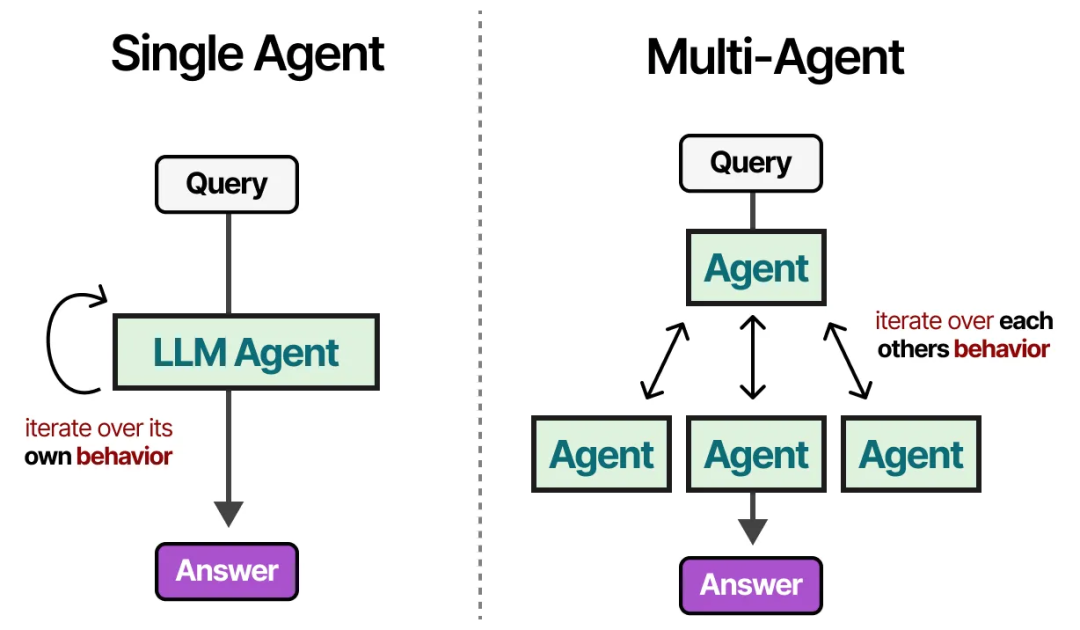
我们探讨的单一代理存在几个问题:工具过多可能使选择变得复杂,上下文变得过于复杂,任务可能需要专业化。
相反,我们可以转向多代理(Multi-Agents),这是一种多个代理(每个代理都可以访问工具、记忆和规划能力)彼此之间以及与环境交互的框架:
这些多代理系统通常由专门的代理组成,每个代理都配备了各自的工具集,并由一个主管(supervisor)进行监督。主管负责管理代理之间的通信,并可以将特定任务分配给专门的代理。
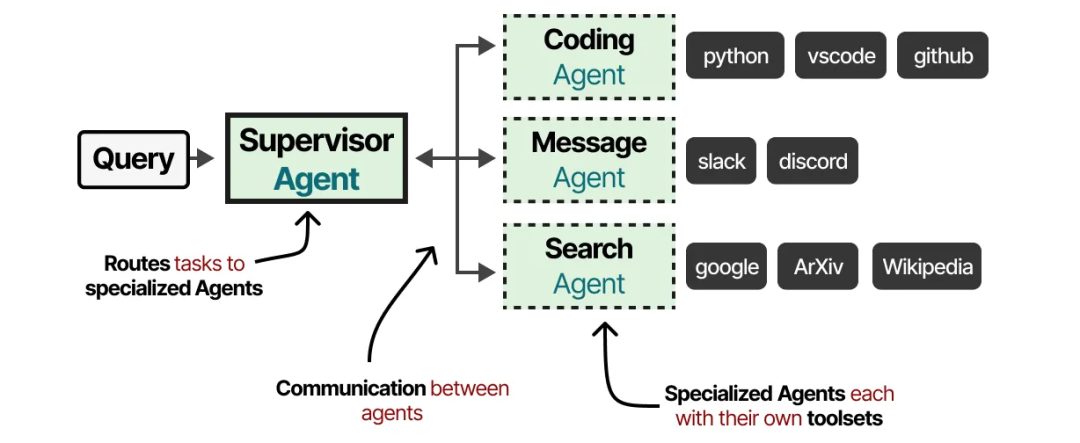
每个代理可能拥有不同类型的工具,但也可能存在不同的记忆系统。
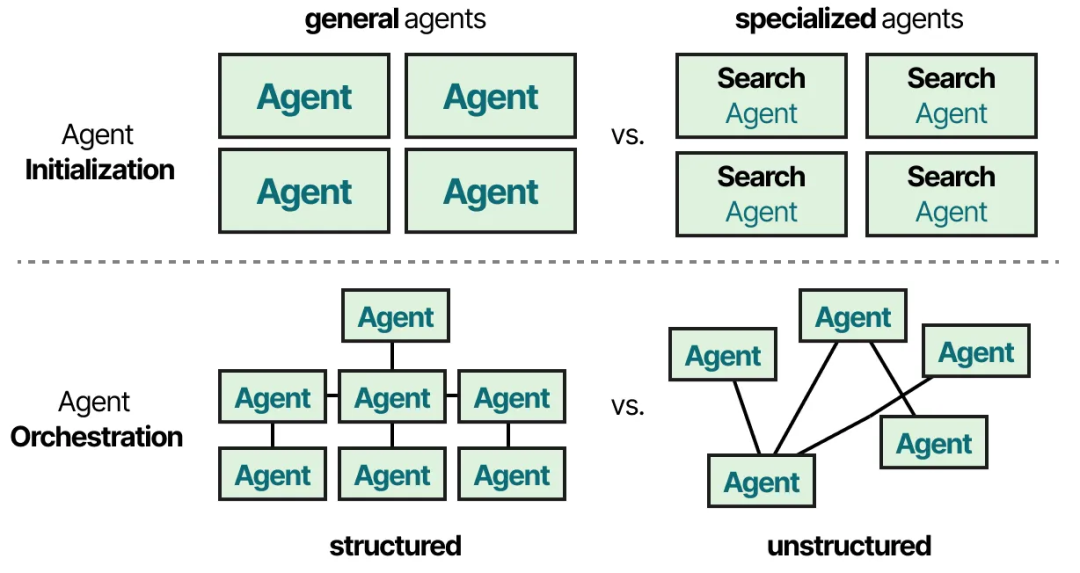
在实践中,有数十种多代理架构,但它们的核心通常包含两个组成部分:
代理初始化(Agent Initialization)— 如何创建单个(专门的)代理?
代理协调(Agent Orchestration)— 如何协调所有代理?
让我们探索各种有趣的 Multi-Agent 框架,并重点介绍这些组件是如何实现的。
人类行为的交互模拟
可以说,最具影响力且非常酷的多 Agent 论文之一是《生成式代理:人类行为的交互模拟》(Generative Agents: Interactive Simulacra of Human Behavior)。
在这篇论文中,他们创建了能够模拟可信人类行为的计算软件代理,这些代理被称为生成式代理(Generative Agents)。。

赋予每个生成式代理的配置文件使其以独特的方式行为,有助于创造出更有趣和动态的行为。
每个代理在初始化时都配备了三个模块(记忆、规划和反思),这与我们之前在 ReAct 和 Reflexion 中看到的核心组件非常相似。
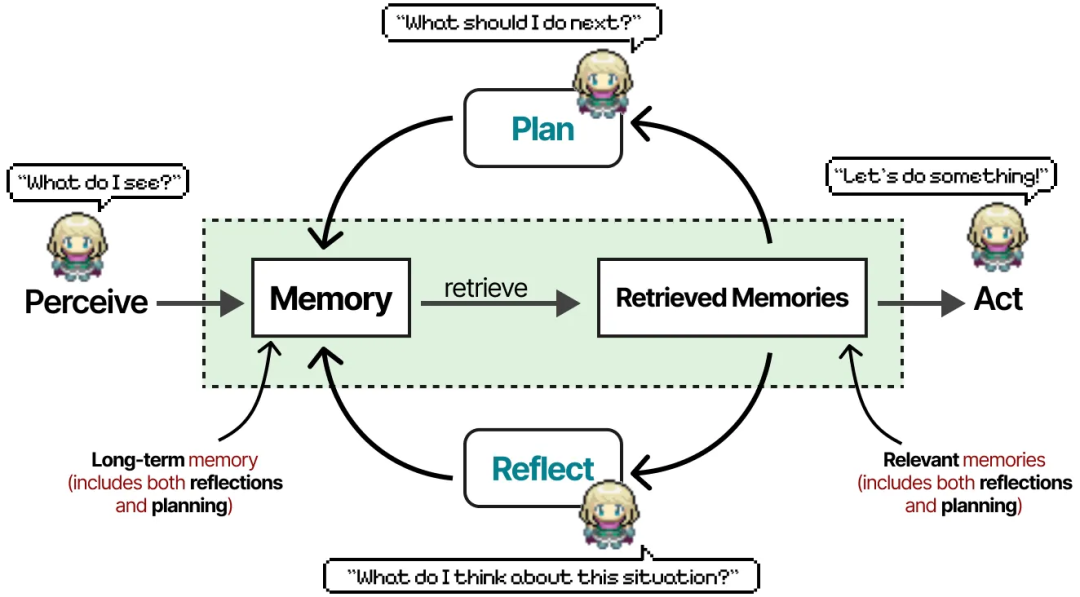
记忆模块是这个框架中最重要的组件之一。它存储了规划和反思行为,以及迄今为止的所有事件。
对于任何给定的下一步或问题,记忆会被检索出来,并根据其新近性、重要性和相关性进行评分。得分最高的记忆会被共享给 Agent。
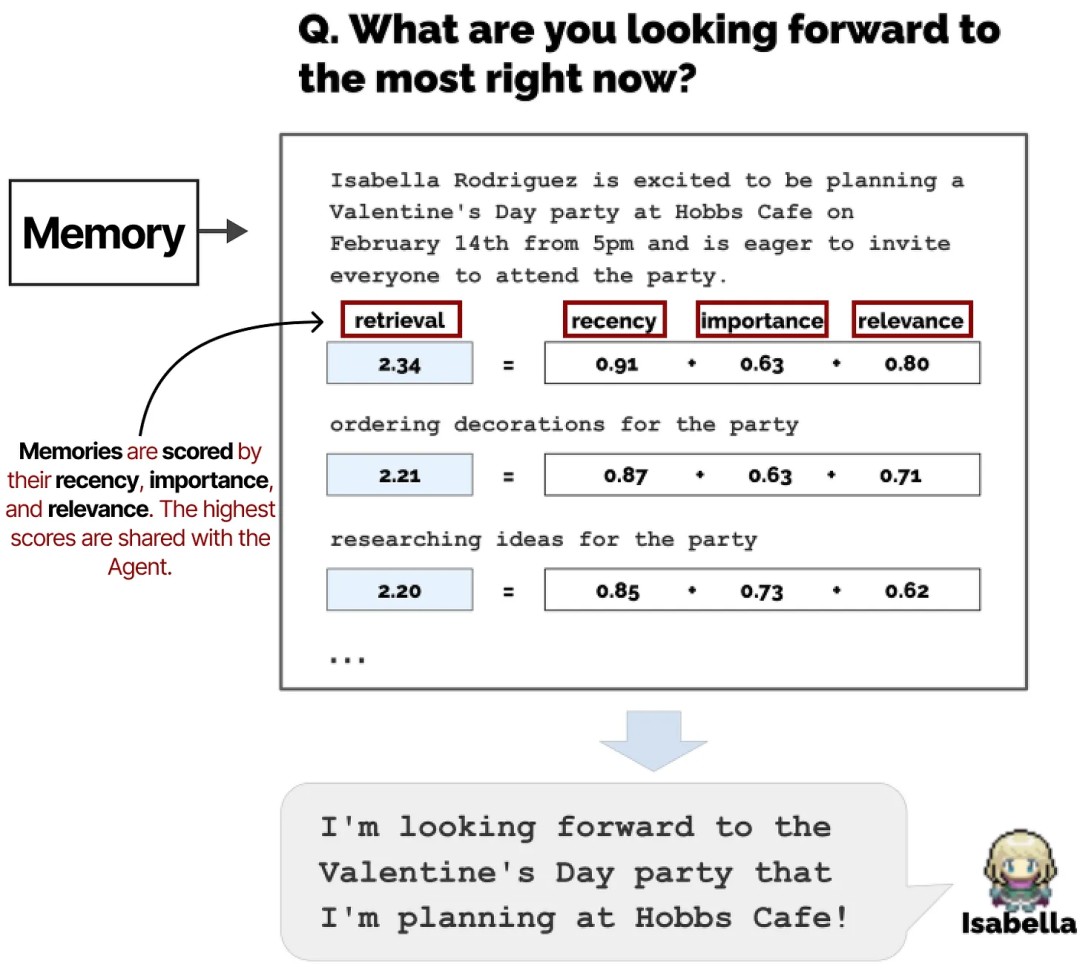 《生成式代理:人类行为的交互模拟》论文中的注释图
《生成式代理:人类行为的交互模拟》论文中的注释图
这些组件共同作用,使 Agent 能够自由地进行行为并相互交互。因此,几乎没有太多的 Agent 协调工作,因为它们并没有特定的目标需要完成。
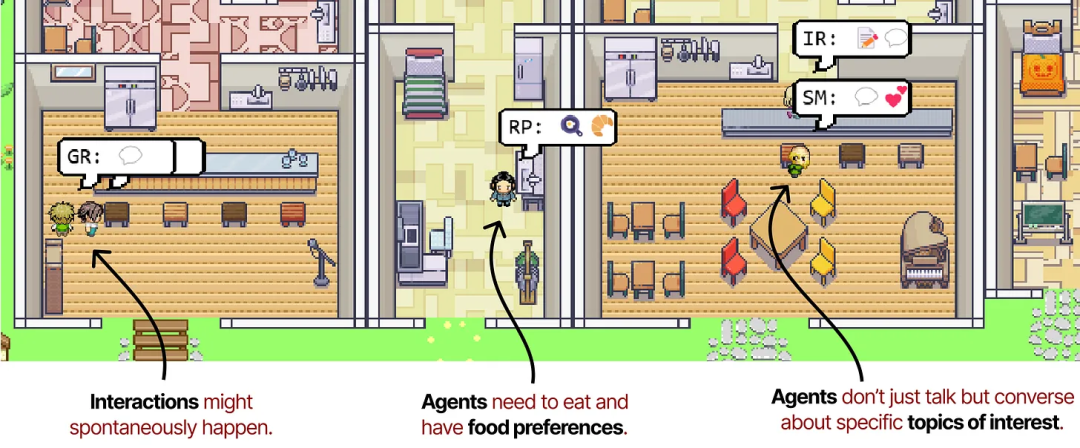 来自交互演示的注释图
来自交互演示的注释图
这篇论文中有太多精彩的信息片段,但我想特别强调他们的评估指标。
他们的评估主要以 Agent 行为的可信度为指标,并由人类评估者对其进行评分。
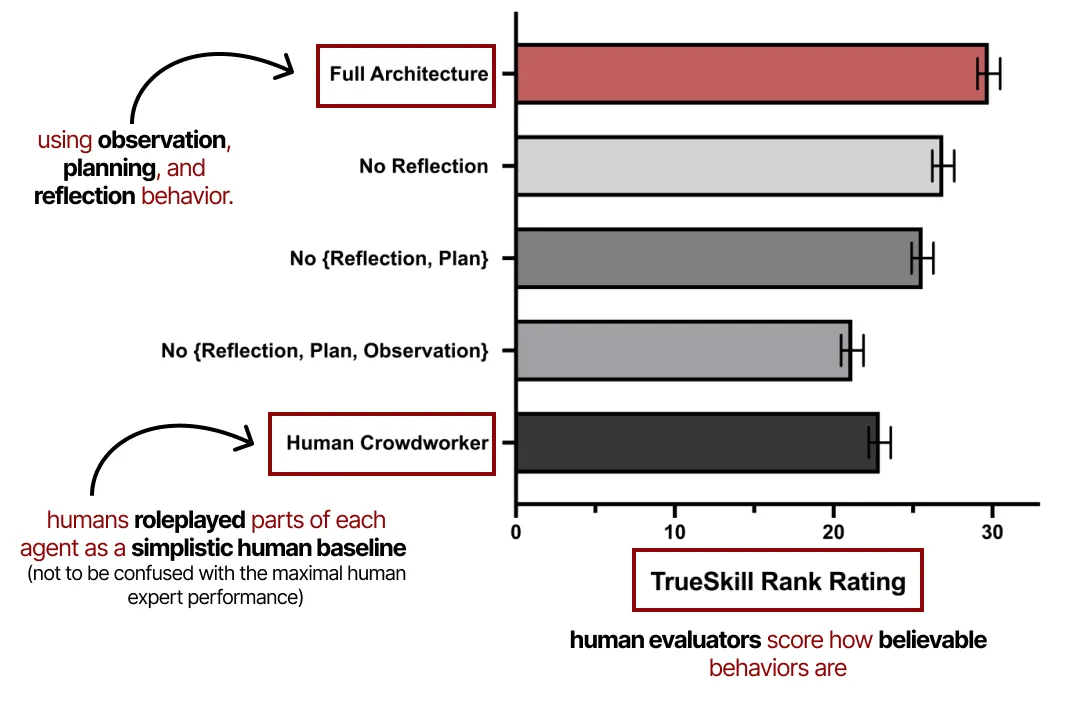 《生成式代理:人类行为的交互模拟》论文中的注释图
《生成式代理:人类行为的交互模拟》论文中的注释图
它展示了观察、规划和反思在这些生成式代理的表现中是多么重要。正如之前探讨的,没有反思行为,规划是不完整的。
模块化框架
无论你选择哪种框架来创建 Multi-Agent 系统,它们通常都由几个组成部分构成,包括 Agent 的配置文件、对环境的感知、记忆、规划以及可用的动作。
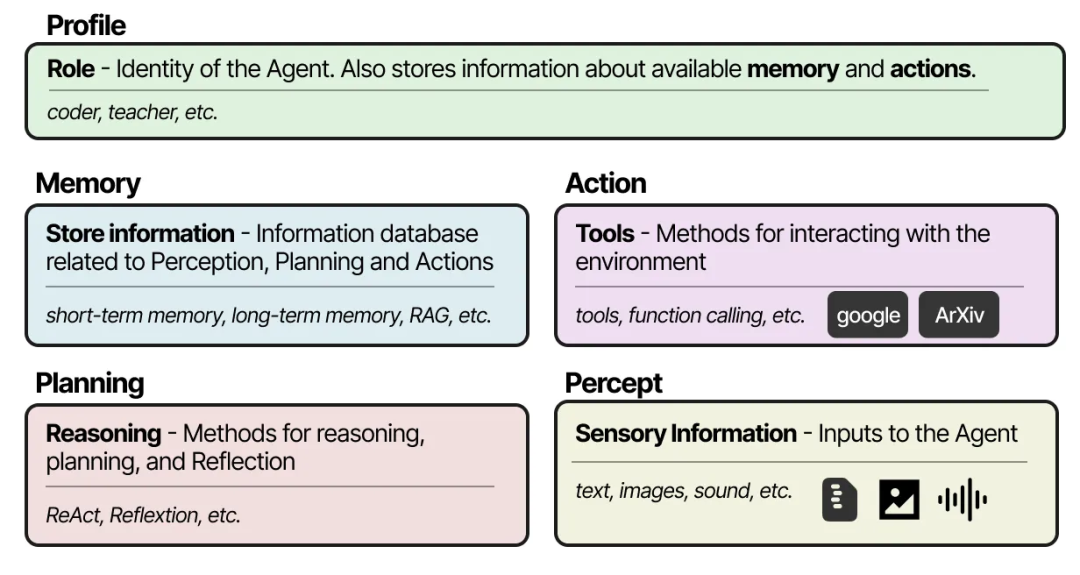
实现这些组件的流行框架包括 AutoGen 17、MetaGPT 18 和 CAMEL 19。然而,每个框架处理 Agent 之间通信的方式略有不同。
以 CAMEL 为例,用户首先创建问题并定义 AI User 和 AI Assistant 角色。AI User 角色代表人类用户,并将引导整个过程。

之后,AI User 和 AI Assistant 将通过相互交互来协作解决查询。
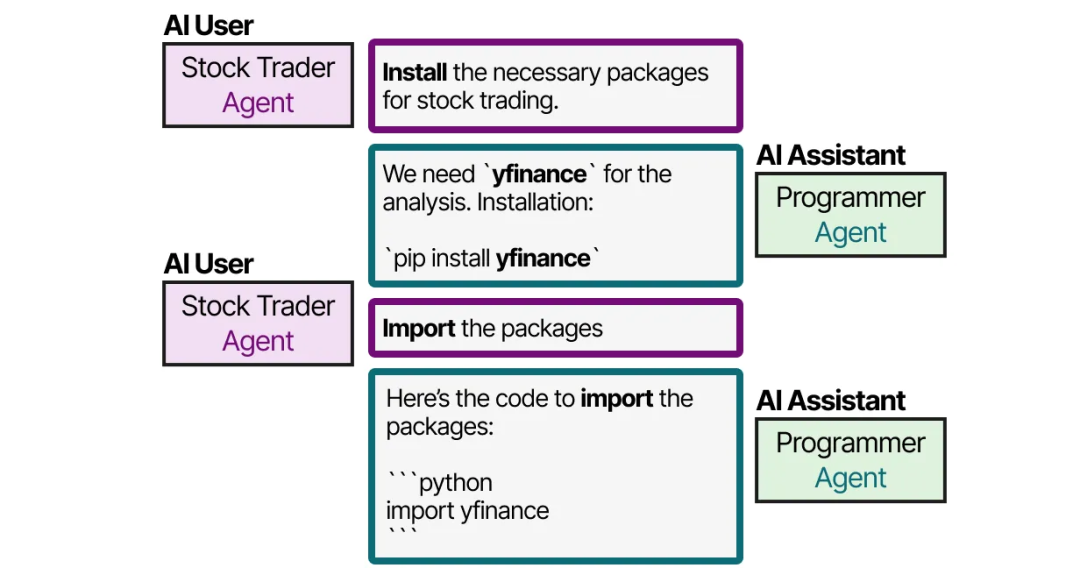
这种角色扮演方法实现了 Agent 之间的协作通信。
AutoGen 和 MetaGPT 的通信方式有所不同,但归根结底都体现了这种协作通信的本质。Agent 有机会相互交流,以更新其当前状态、目标和下一步计划。
在过去的一年里,尤其是最近几周,这些框架的发展呈现爆炸式增长。
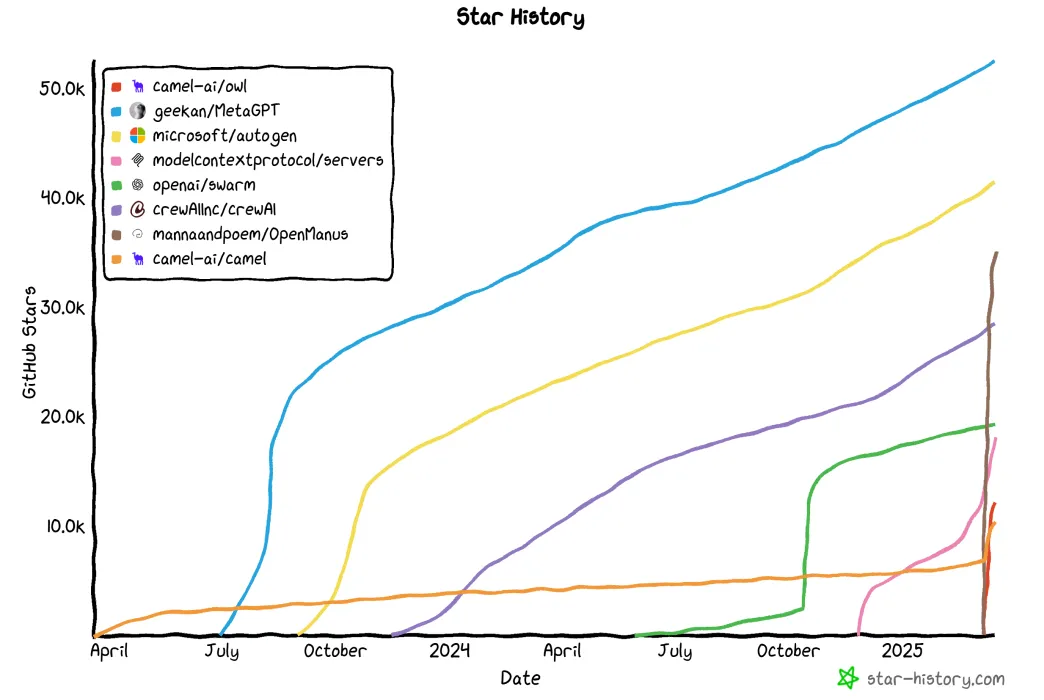
2025 年将会是令人无比兴奋的一年,因为这些框架会不断成熟和发展!
结论
到这里,我们关于 LLM Agent 的探索之旅就结束了!希望这篇文章能让你更好地理解 LLM Agent 是如何构建的。
想了解更多与 LLM 相关的可视化内容可以看看我写的书《图解大模型:生成式AI原理与实战》(Hands-On Large Language Models: Language Understanding and Generation)!

中文版预计 4 月底上市



















 5
5

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









