







一、KMP算法
1、实现思想
-
思想
KMP 算法的基本思想是利用已经匹配过的信息,尽量减少匹配的次数。其核心在于构建模式串的“部分匹配表”(Partial Match Table),也称为“next 数组”。该表记录了模式串中每个位置的最长前缀子串,使得该前缀子串同时也是该位置的后缀子串的长度。这个表的构建过程是 KMP 算法的关键步骤之一。
2、匹配动画
-
KMP算法匹配动画
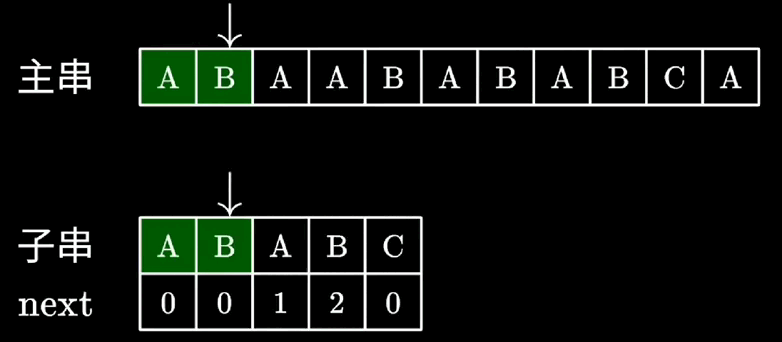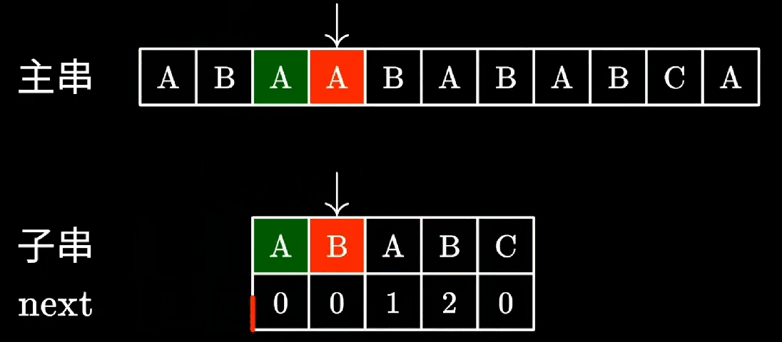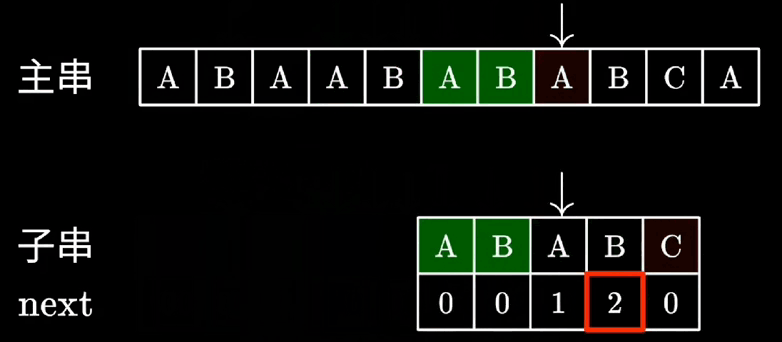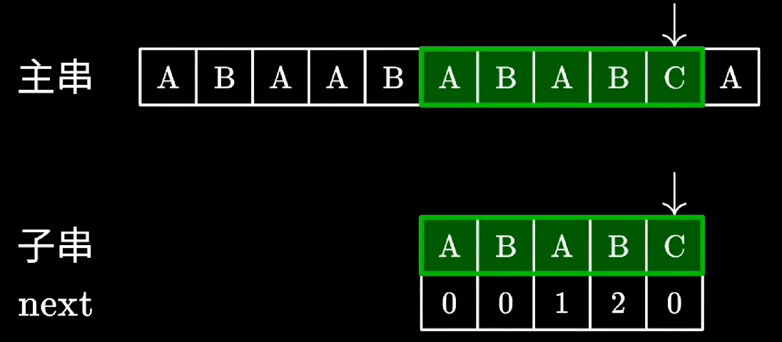
-
数组动画

-
代码实现
int KMPIndex(SqString s, SqString t) { // 定义KMP算法函数,返回匹配的起始位置索引
int next[MaxSize], i = 0, j = 0; // 定义next数组,以及两个索引i和j
GetNext(t, next); // 调用GetNext函数获取模式串t的next数组
// 当主串s和模式串t均未遍历完时进行匹配
while (i < s.length && j < t.length) {
// 当前字符匹配或已到达模式串开头时,继续匹配下一个字符
if (j == -1 || s.data[i] == t.data[j]) {
i++; // 主串指针后移
j++; // 模式串指针后移
} else {
j = next[j]; // 模式串指针回溯到next[j]位置
}
}
// 若模式串已完全匹配,则返回匹配的起始位置索引
if (j >= t.length)
return (i - t.length);
else
return (-1); // 否则返回匹配失败标志
}
3、改进Kmp算法
大家来看一个例子: 主串s=“aaaaabaaaaac” 子串t=“aaaaac”
这个例子中当‘b’与‘c’不匹配时应该‘b’与’c’前一位的‘a’比,这显然是不匹配的。'c’前的’a’回溯后的字符依然是‘a’。 我们知道没有必要再将‘b’与‘a’比对了,因为回溯后的字符和原字符是相同的,原字符不匹配,回溯后的字符自然不可能匹配。但是KMP算法中依然会将‘b’与回溯到的‘a’进行比对。这就是我们可以改进的地方了。我们改进后的next数组命名为:nextval数组。KMP算法的改进可以简述为: 如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next值。 这应该是最浅显的解释了。如字符串"ababaaab"的next数组以及nextval数组分别为:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 子串 | a | b | a | b | a | a | a | b |
| next | -1 | 0 | 0 | 1 | 2 | 3 | 1 | 1 |
| nextval | -1 | 0 | -1 | 0 | -1 | 3 | 1 | 0 |
-
代码实现
int KMPIndex1(SqString s, SqString t)
// 修正的KMP算法
// 函数名:KMPIndex1
// 参数:s为主串,t为模式串
{
int nextval[MaxSize], i = 0, j = 0;
GetNextval(t, nextval); // 调用GetNextval函数获取模式串的nextval数组
while (i < s.length && j < t.length){
if (j == -1 || s.data[i] == t.data[j]){
i++; j++; // 主串和模式串匹配,继续向后移动
}else{
j = nextval[j]; // 主串和模式串不匹配,根据nextval数组移动模式串指针
}
}
if (j >= t.length)
return (i - t.length); // 返回主串中匹配到模式串的起始位置
else
return (-1); // 主串中未匹配到模式串,返回-1
}















 1237
1237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









