






背景
业务中会碰到线上数据需要导入到线下进行验证的场景。一般可以通过sql的导出导入实现,但是当数据较为复杂时sql操作次数也较多,带来不小的人工成本,故希望通过程序化方式实现数据跨环境同步
方案
数据跨环境同步常见的有数据
- 基于数据文件导出和导入的全量同步,这种同步方式一般只适用于同种数据库之间的同步,如果是不同的数据库
- 增量同步一般是做实时的同步,早期很多数据同步都是基于关系型数据库的触发器trigger来做的。
- 基于时间戳的增量同步
- 基于数据库日志(比如mysql的binlog)的同步
- 基于BulkLoad的数据同步,比如从hive同步数据到hbase
- 基于sqoop的全量导入
- Debezium+bireme:Debezium for PostgreSQL to Kafka Debezium也是一个通过监控数据库的日志变化,通过对行级日志的处理来达到数据同步,而且Debezium 可以通过把数据放入到kafka,这样就可以通过消费kafka的数据来达到数据同步的目的。而且还可以给多个地方进行消费使用
参考 https://blog.csdn.net/jnrjian/article/details/123957465
另外还可以通过rpc调用实现数据读写进行同步,在用户选择性同步或需要自定义业务逻辑时可采用此方法,通过简单业务编码就能实现。缺点是不如基于数据库那么业务无感,每个新增都完全同步时会引入性能问题。
核心步骤
- 读线上数据
- 调用线下接口,写入数据
关键问题
线上访问线下
一般公司会对环境做管控,不同环境相互隔离。此时需要一个暴露出来的负载调度服务器实现线上rpc路由到线下服务器。
写入安全问题
线上写线下,出现问题也只是在线下,这种数据写入的调用不能调到线上
#if(${dbmode}=="dev" || ${dbmode}=="stable" || ${dbmode}=="test" || ${dbmode}=="sit")
<bean id="syncWriteFacade" class="com.xxx.SyncWriteFacadeImpl"/>
<sofa:service ref="syncWriteFacade" interface="com.xxx.SyncWriteFacade">
<sofa:binding.tr/>
</sofa:service>
#end
唯一键冲突问题
唯一键id,code等带上环境位,如线下0,线上1,一定程度上,避免插入时冲突。实在冲突直接删除线下,使用线上数据。
读写性能问题
读写时直接读写do层数据,减少业务侵入。但是读写整个业务数据体才有意义。
一般方案
直接递归查询其依赖的数据。sql太多,性能差,强耦合,需数据整体一一对应的读取和存储接口配合进行同步
例子:A关联了B1、B2、…、Bn,每个B又关联了C1、C2、…、Cm,每个C又关联了D1、D2、…、Di,同时A也关联了Ci、Ci+1…、Cj,假设都以id关联
递归查询时:
由A能够使用1条sql批量查询出B1、B2、…、Bn,再一条批量sql查询出Ci、…、Cj
每个B可以一个sql批量查询出C1、C2、…、Cm,一共有n个B,则每个B查出关联的C一共需要n条sql;
每个C可以一个sql批量查询出D1、D2、…、Di,一共有nm+j-i个C,则每个C查出关联的D一共需要nm+j-i条sql;
即使每一步使用批量sql加载A总共也需要1+n+n*m+j-i条sql
插入同理,不做赘述
优化方案
读取任务队列:放置读取任务的优先级队列,根据任务类型定义任务优先级,按照依赖数据数据链路长度划分优先级,依赖链路越长优先级越高。任务优先级能帮助依赖链路长的上层数据结构先加载,下层共用的数据加载能凑到一起更大的提升任务聚合能力,属于参数优化,即使没有设置或者设置有问题,保底性能也能部分聚合任务,速度优于无聚合读取。理论上通过合理设置,每种类型数据都只用加载一次。
任务:包含任务关键数据,如id,code列表和任务类型
任务类型:与数据类型相关,如“A数据根据id加载型任务”或“A数据根据code加载型任务”
任务合并:同任务类型的任务包含的任务关键数据也相同,如A数据根据id加载型任务,都包含id列表,则合并时将id列表合并
读取器:进行任务处理,执行读取任务,并生成相关联的读取任务加入到读取任务队列
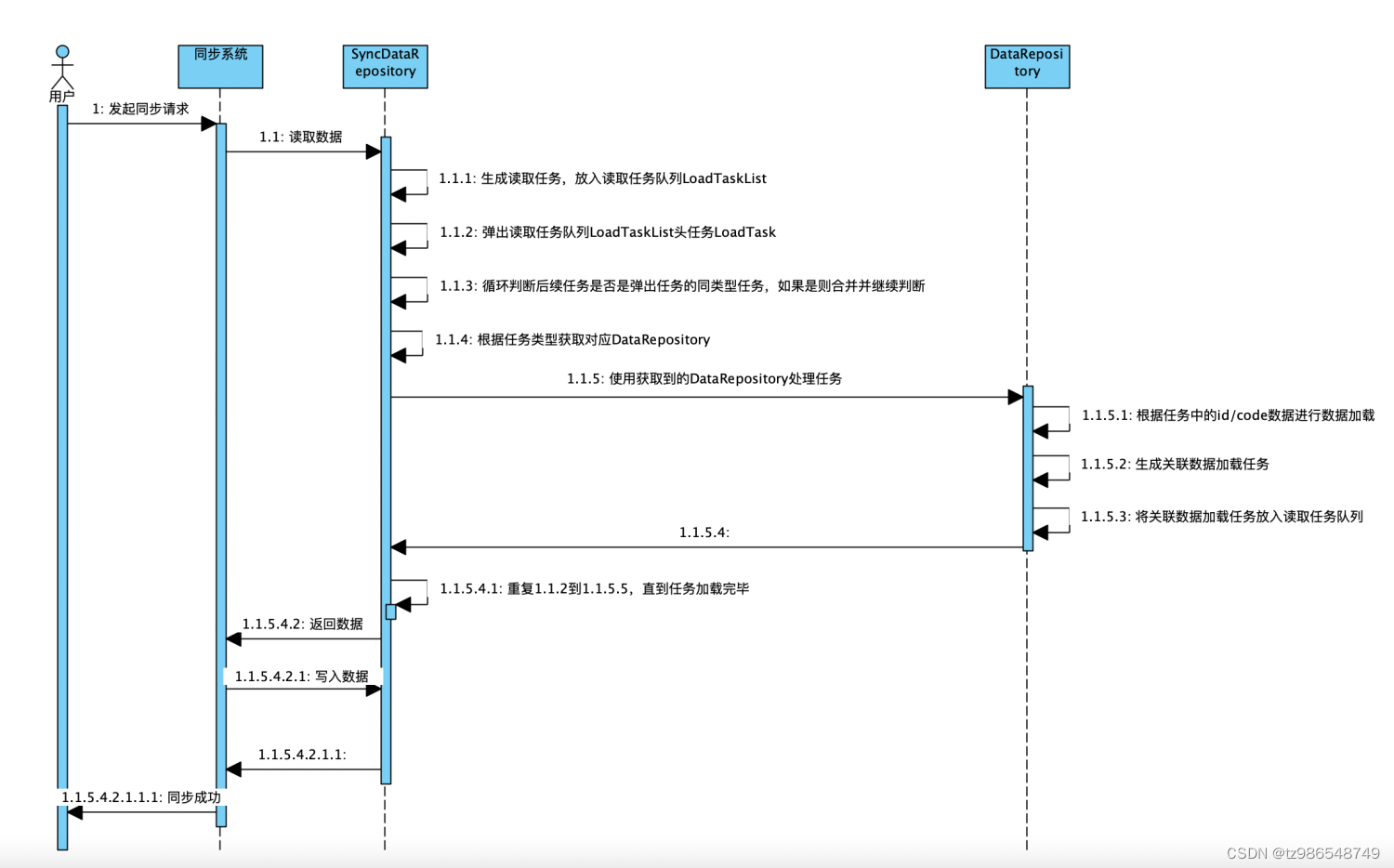
- 初始任务放入:数据读取时将需要读取数据id和数据类型生成数据读取任务放入读取任务队列中。
- 任务取出:判断读取任务队列不为空,则从数据读取任务队列中取出第一个任务,
- 任务合并:判断下一个任务是否是同类型的,如果是同类型任务则进行任务合并,重复此动作,直到下一个是不同类型任务
- 任务执行:根据任务类型,使用对应的读取器读取任务,并生成相关联的读取任务
- 重复执行以上2-4步直到任务处理完毕,则数据读取完成
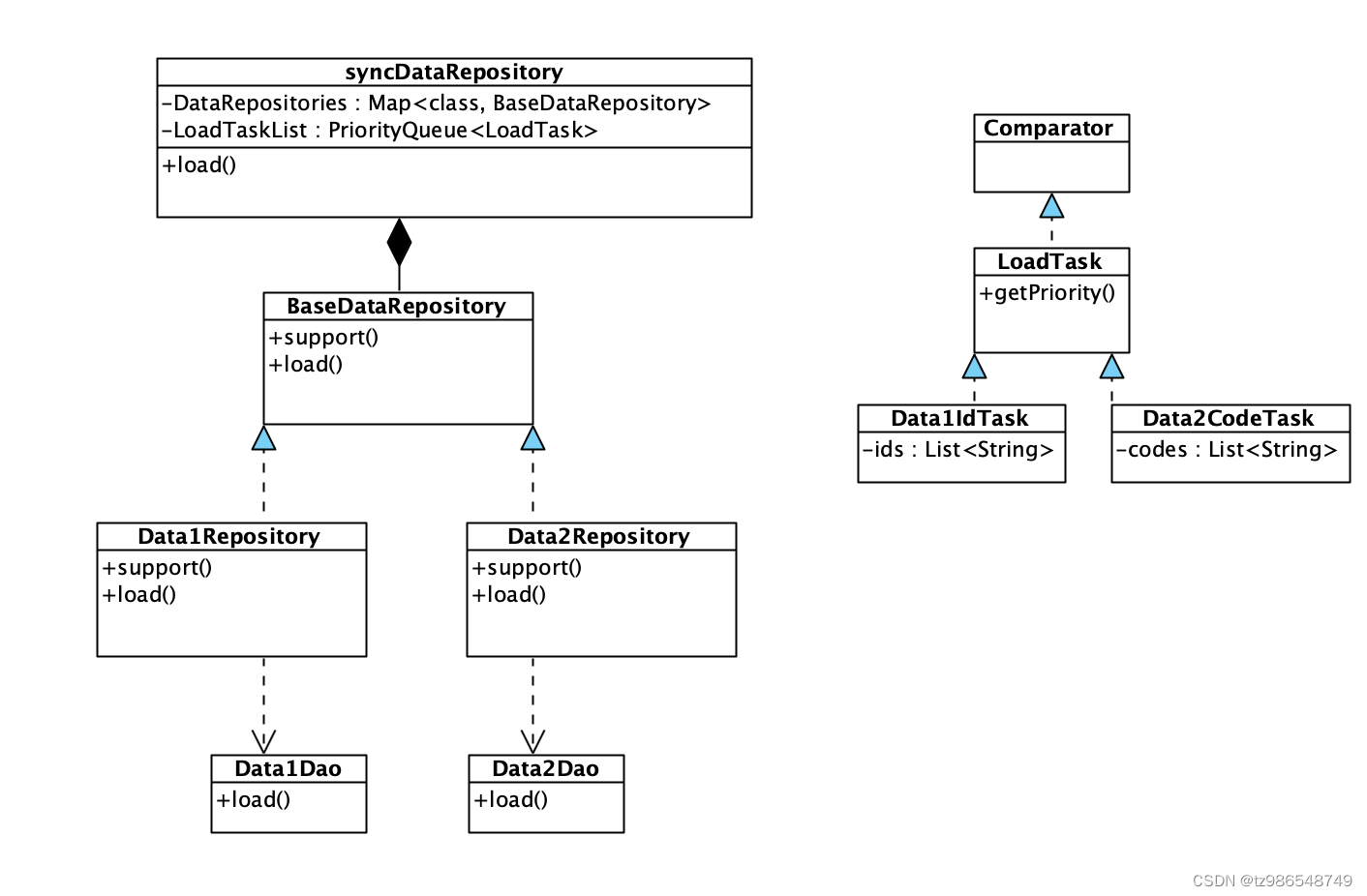 syncDataRepository:数据同步仓储,维护数据加载仓储与数据加载任务的关联关系,承载数据加载任务优先级队列。根据任务类型获取对应数据仓储DataRepository,进行数据加载
syncDataRepository:数据同步仓储,维护数据加载仓储与数据加载任务的关联关系,承载数据加载任务优先级队列。根据任务类型获取对应数据仓储DataRepository,进行数据加载
DoLoadTask:实现comparator接口,用getPriority获取优先级。在getPriority中根据任务类型定义任务优先级
同例:A关联了B1、B2、…、Bn,每个B又关联了C1、C2、…、Cm,每个C又关联了D1、D2、…、Dk,同时A也关联了Ci、Ci+1、…、Cj,假设都以id关联
- 定义A的优先级为1,B为2,C为3,D为4。
- 将A的查询信息转化为A数据读取读取任务(如,A的id转化为A的id读取任务)
- 加入A的读取任务到读取任务队列后进行执行
- 执行A的读取任务,1个批量sql查询出A,
- 从A中生成B1、B2、…、Bn,Ci、Ci+1、…、Cj读取任务,加入任务队列
- B1、B2、…、Bn优先级为2,Ci、Ci+1、…、Cj读取任务优先级为3,队列中B任务全排在C任务之前,假设弹出B1查询任务
- 判断后续任务是否同为C加载任务,是则合并任务
- 重复7直到后续任务不是B的加载任务,此时弹出任务为B1…Bn的合并任务,队列里面全为C的加载任务
- 执行弹出的B1…Bn的合并任务,1个sql查询出B1、B2、…、Bn
- 从B1、B2、…、Bn中生成n组(C1、C2、…、Cm)的读取任务,加入任务队列
- n组(C1、C2、…、Cm)和6中Ci、Ci+1、…、Cj任务优先级都为3,假设弹出Ci查询任务
- 判断后续任务是否同为C加载任务,是则合并任务
- 重复12直到后续任务不是C的加载任务,此时弹出任务为n组(C1、C2、…、Cm)和6中Ci、Ci+1、…、Cj共n*m+j-i个C的合并任务
- 执行弹出的nm+j-i个C的合并任务,1个sql查询出nm+j-i个C
- 从nm+j-i个C中生成关联的nm+j-i组(D1、D2、…、Dk)的读取任务,加入任务队列
- 所有D读取任务优先级都是4,假设弹出D1查询任务
- 判断后续任务是否同为D加载任务,是则合并任务
- 重复17直到后续任务不是D的加载任务,此时弹出任务为所有D的合并任务
- 执行D的合并任务,1个sql查询出所有D
整个过程只有4、9、14、19四条sql,极大提升数据加载性能














 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









