







UTF-8、UTF-16 和 UTF-32 字符编码之间的主要区别在于它需要多少字节来表示内存中的字符。UTF-8 最少使用 1 个字节,而 UTF-16 最少使用 2 个字节。顺便说一句,如果字符的代码点大于 127,则 byte 的最大值则 UTF-8 可能需要 2、3 或 4 个字节,但 UTF-16 只会占用两个或四个字节。另一方面,UTF-32 是一种固定宽度的编码方案,总是使用 4 个字节来编码一个 Unicode 代码点。现在,让我们从什么是字符编码开始,以及为什么它很重要?嗯,字符编码是字节流转化为字符的过程中的一个重要概念,可以显示。
有两件事对于将字节转换为字符很重要,即字符集和编码。由于世界上有如此多的字符和符号,因此需要一个字符集来支持所有这些字符。字符集只不过是字符列表,其中每个符号或字符都映射到一个数值,也称为代码点。
另一方面,UTF-16、UTF-32 和 UTF-8 是编码方案,它们描述了这些值(代码点)如何映射到字节(使用不同的位值作为基础;例如 UTF-16 为 16 位,UTF-32 为 32 位,UTF-8 为 8 位)。UTF 代表 Unicode 转换,它定义了一种算法来将每个 Unicode 代码点映射到唯一的字节序列。
例如,对于字符 A,即拉丁大写字母 A,Unicode 代码点为 U+0041,UTF-8 编码字节为 41,UTF-16 编码为 0041,Java 字符文字为'\u0041'。简而言之,您只需要一个字符编码方案来解释一个字节流,在没有字符编码的情况下,您无法正确显示它们。Java 编程语言广泛支持不同的字符集和字符编码,默认情况下它使用 UTF-8。
UTF-32、UTF-16 和 UTF-8 编码之间的区别
正如我之前所说,UTF-8、UTF-16 和 UTF-32 只是存储 Unicode 代码点的几种方式,即在计算机内存中使用 8、16 和 32 位的 U+ 幻数。一旦 Unicode 字符转换为字节,它就可以很容易地保存在磁盘中,通过网络传输并在另一端重新创建。
UTF-32和UTF-8的根本区别在于,UTF-16是前者是定宽编码方案,后者是变长编码方案。顺便说一句,尽管UTF-8 和 UTF-16 都使用 Unicode 字符和可变宽度编码,但它们之间也存在一些差异。
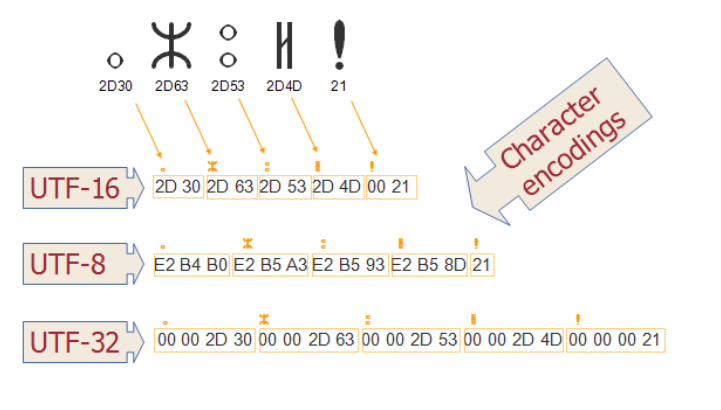
这是一个例子,它显示了在不同的字符编码方案(例如 UTF-16、UTF-8 和 UTF-32)下,不同的字符是如何映射到字节的。您可以看到不同的方案如何使用不同数量的字节来表示相同的字符。
1. UTF-8 在编码字符时最少使用一个字节,而 UTF-16 最少使用两个字节。
在 UTF-8 中,从 0 到 127 的每个代码点都存储在单个字节中。仅使用 2,3 或实际上最多 4 个字节存储代码点 128 及以上。简而言之,UTF-8 是可变长度编码,占用 1 到 4 个字节,具体取决于代码点。UTF-16 也是可变长度字符编码,但需要 2 或 4 个字节。另一方面,UTF-32 是固定的 4 个字节。2. UTF-8 与 ASCII 兼容,而 UTF-16 与 ASCII 不兼容
UTF-8 的优势在于 ASCII 是最常用的字符,在这种情况下,大多数字符只需要一个字节。仅包含 ASCII 字符的 UTF-8 文件与 ASCII 文件具有相同的编码,这意味着 UTF-8 中的英文文本看起来与 ASCII 中的完全相同。鉴于过去 ASCII 占主导地位,这是最初接受 Unicode 和 UTF-8 的主要原因。这是一个例子,它显示了在不同的字符编码方案(例如 UTF-16、UTF-8 和 UTF-32)下,不同的字符是如何映射到字节的。您可以看到不同的方案如何使用不同数量的字节来表示相同的字符。



















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











