









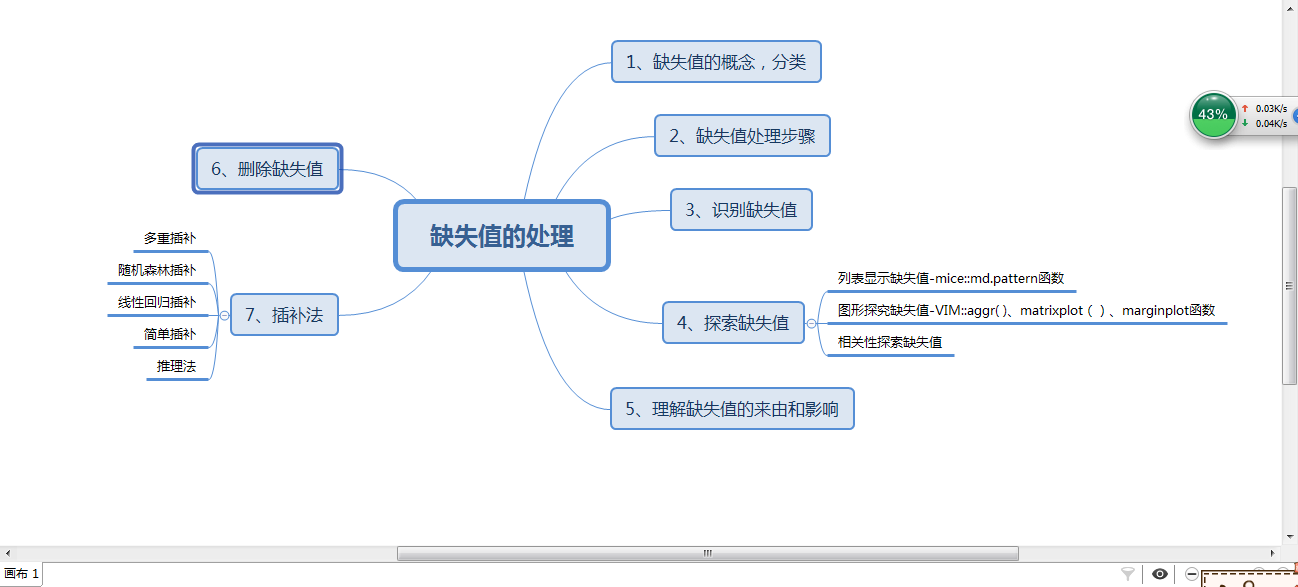
image.png
一、认识缺失值
在我们的数据分析过程中,经常会碰到缺失值的情况。缺失值产生的原因很多,比如人工输入失误,系统出错,或者是正常情况,比如未婚状态下的子女个数肯定是0或者直接不填,这种情况就是正常的。所以我们处理缺失值的步骤一般是:
1) 识别缺失值
2) 检查导致缺失值的原因
3) 删除包含缺失值的行或列或者用合理的数值填补缺失值或者不处理
R使用 NA (不可得)代表缺失值, NaN (不是一个数)代表不可能值。
缺失的数据有三种类型:
将数据集中不含缺失值的变量(属性)称为完全变量,数据集中含有缺失值的变量称为不完全变量,Little 和 Rubin定义了以下三种不同的数据缺失机制:
1)完全随机缺失(Missing Completely at Random,MCAR)。数据的缺失与不完全变量以及完全变量都是无关的。
2)随机缺失(Missing at Random,MAR)。数据的缺失仅仅依赖于完全变量。
3)非随机、不可忽略缺失(Not Missing at Random,NMAR,or nonignorable)。不完全变量中数据的缺失依赖于不完全变量本身,这种缺失是不可忽略的。
以下图中是R中用来处理缺失值的一些总结
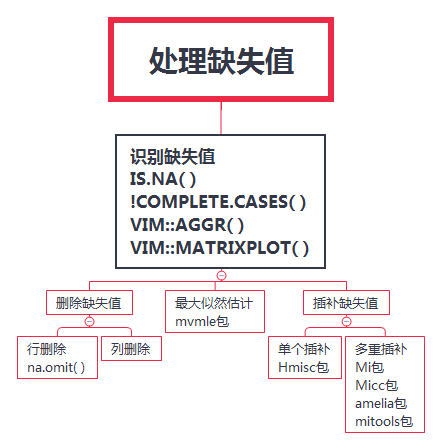
image.png
二、识别缺失值
library(VIM)
a <- head(sleep)
is.na(a)
complete.cases(a) #查看行是否完整
nrow(na.omit(sleep)) #查看行没有缺失值的行数
nrow(sleep)-nrow(na.omit(sleep)) #查看缺失值的行数
nrow(sleep[!complete.cases(sleep),]) #查看缺失值的行数
nrow(sleep[!complete.cases(sleep),])/nrow(sleep) #查看缺失值的占比
nrow(sleep[!complete.cases(sleep$Dream),])/nrow(sleep) #查看Dream这一列缺失值的占比
sum(!complete.cases(sleep$Dream))/nrow(sleep)
注意:complete.cases函数仅将 NA 和 NaN 识别为缺失值,无穷值( Inf 和 -Inf )被当作有效值。
以上代码都是针对全部特征或者全部样本而言,如果我们想查看某几列或者某几行的缺失情况,上面的代码就有点麻烦。我们可以通过构建一个函数,并用向量化的方式来操作:
apply(mice::nhanes2,2,function(x){paste0((sum(is.na(x))/length(x))*100,"%")})
apply(mice::nhanes2,1,function(x){paste0((sum(is.na(x))/length(x))*100,"%")})
一般来说,缺失值可靠的最大阈值是数据集总数的5%。如果某些特征或样本缺失的数据超过了5%,你可能需要忽略掉这些特征或样本。
以上代码都很简单,但是不怎么形象,我们可以借助mice,VIM包中的一些函数对缺失值进行可视化探索,然后在决定下一步该怎么操作
base::summary函数
> summary(mice::nhanes2)
age bmi hyp chl
20-39:12 Min. :20.40 no :13 Min. :113.0
40-59: 7 1st Qu.:22.65 yes : 4 1st Qu.:185.0
60-99: 6 Median :26.75 NA's: 8 Median :187.0
Mean :26.56 Mean :191.4
3rd Qu.:28.93 3rd Qu.:212.0
Max. :35.30 Max. :284.0
NA's :9 NA's :10
三、探索缺失值
3.1列表显示
mice::md.pattern函数
mice::md.pattern(sleep)
得到如下结果:
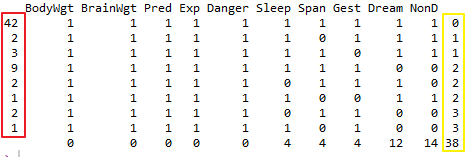
image.png
1代表不是缺失值,0代表缺失值
红色部分,比如42,代表数据集sleep中每个变量的值都不是缺失值的行数有42行;
2代表在Span变量这里有缺失值,其他变量没有缺失值的情况有两行
黄色部分代表缺失值的个数
3.2图形探究缺失值
VIM::aggr()
VIM::aggr(VIM::sleep,prop=F,numbers=T,col=c("darkblue","red"),sortVars=TRUE,
labels=names(VIM::sleep),ylab=c("Histogram of missing data", "Pattern"))
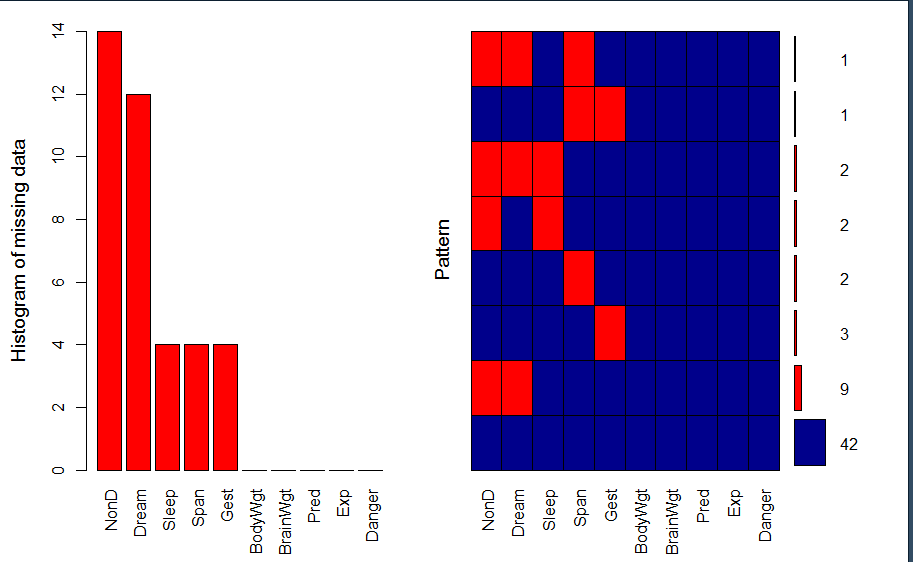
image.png
VIM::aggr(sleep,prop=T,numbers=T)
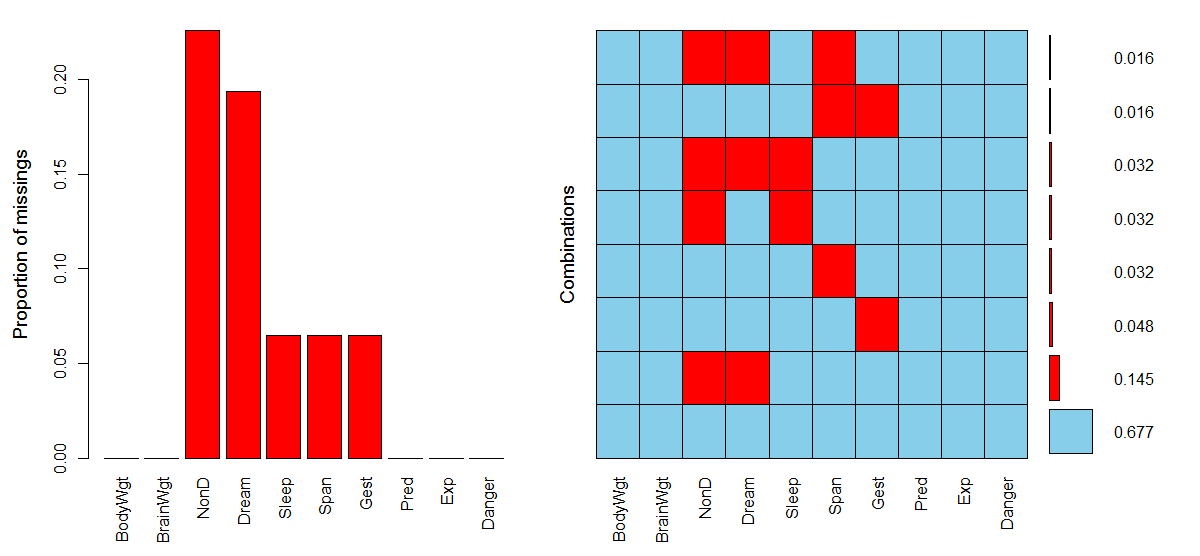
image.png
VIM::aggr(sleep,prop=F,numbers=F) #numbers操纵数值标签
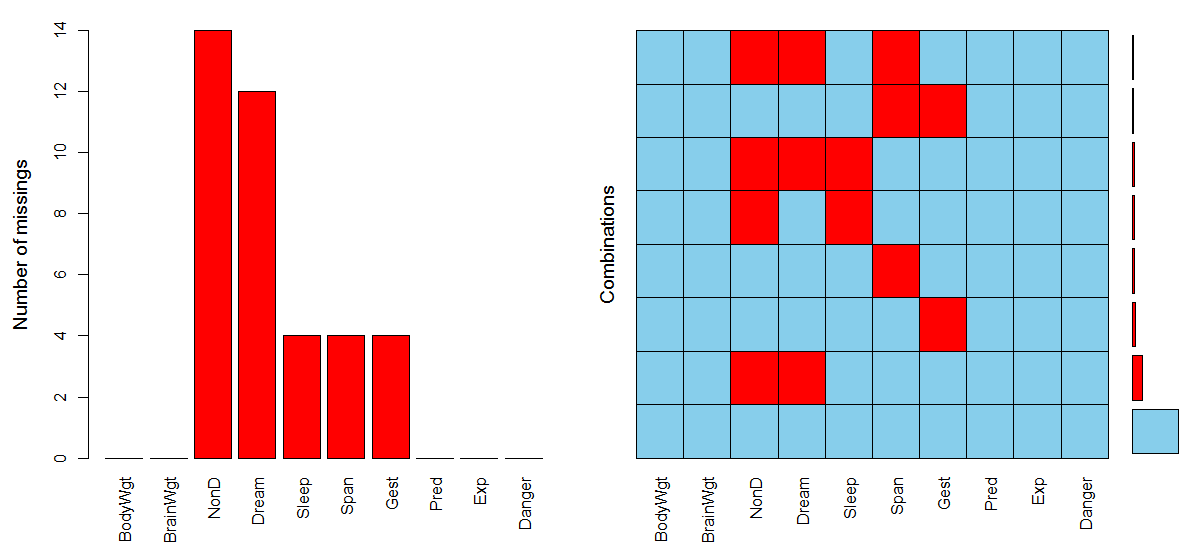
image.png
VIM::matrixplot()
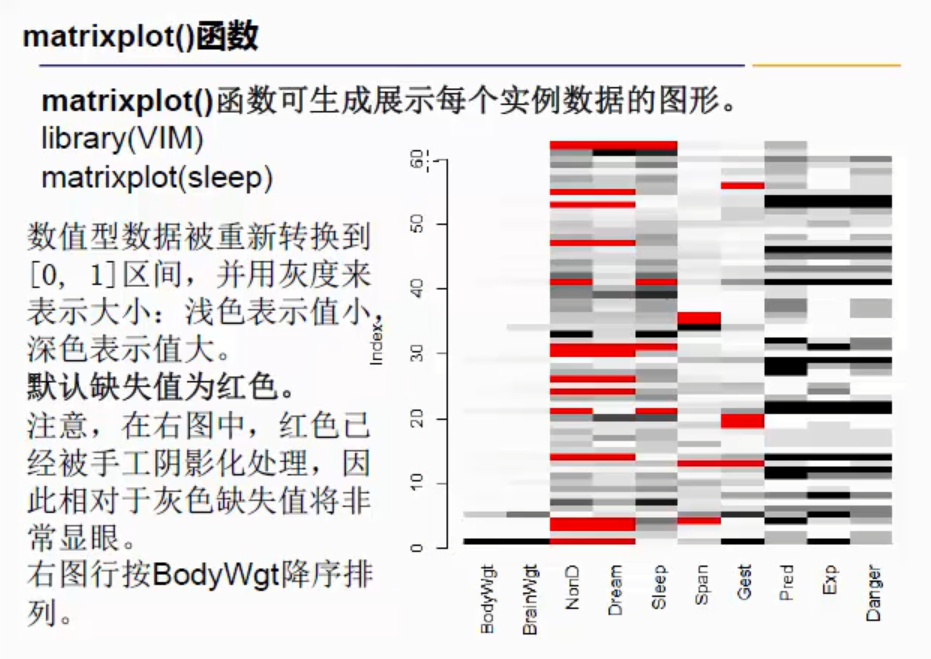
image.png
VIM::marginplot( )
VIM::marginplot(VIM::sleep[,4:5])
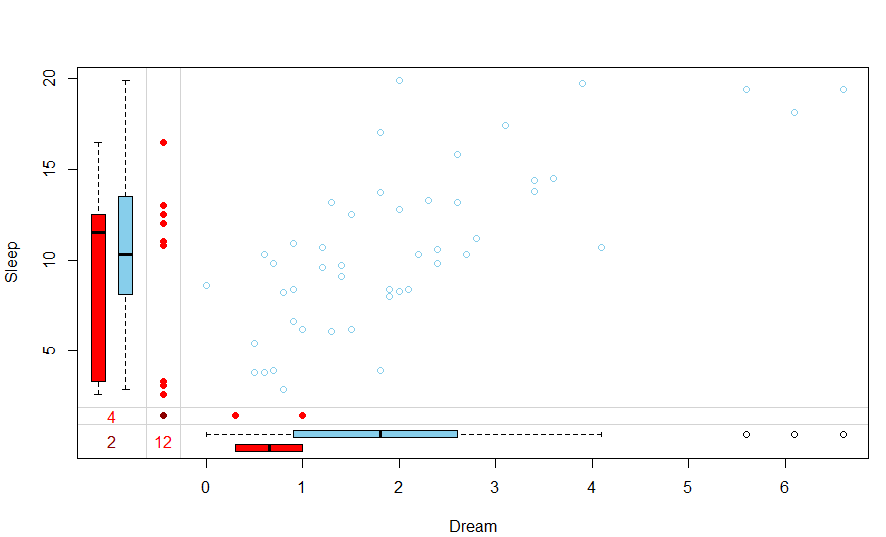
image.png
左边的红色箱线图代表Dream值缺失的情况下Sleep的分布,蓝色箱线图代表Dream值不缺失的情况下Sleep分布。底下的两个箱线图的关系反过来理解。左边的(y轴)9个红点代表缺失了Dream的Sleep值。两个变量均有缺失值的观测个数在最左下角那里,即2.可以看出Sleep和Dream变量大致呈正相关关系
如果对数据缺失假定为MCAR(完全随机)类型正确的话,那么我们预期的红色箱线图和蓝色箱线图应该是非常相似的。
VIM 包有许多图形可以帮助你理解缺失数据在数据集中的模式,包括用散点图、箱线图、直方图、散点图矩阵、平行坐标图、轴须图和气泡图来展示缺失值的信息,因此这个包很值得探索
3.3相关性探索缺失值
我们可以用指示变量代替数据集中的数据(1表示缺失值,0表示完整)生成影子矩阵
- 1)求影子矩阵中指示变量之间的相关性,看看哪些变量经常一起缺失
> data(sleep,package = "VIM")
>
> x<- as.data.frame(abs(is.na(sleep)))
> head(x)
BodyWgt BrainWgt NonD Dream Sleep Span Gest Pred Exp Danger
1 0 0 1 1 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0 0
3 0 0 1 1 0 0 0 0 0 0
4 0 0 1 1 0 1 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0 0 0
然后求相关性
> y <- x[which(apply(x,2,sum)>0)] #筛选出有缺失值的变量
> cor(y)
NonD Dream Sleep Span Gest
NonD 1.00000000 0.90711474 0.48626454 0.01519577 -0.14182716
Dream 0.90711474 1.00000000 0.20370138 0.03752394 -0.12865350
Sleep 0.48626454 0.20370138 1.00000000 -0.06896552 -0.06896552
Span 0.01519577 0.03752394 -0.06896552 1.00000000 0.19827586
Gest -0.14182716 -0.12865350 -0.06896552 0.19827586 1.00000000
通过以上相关性矩阵的结果可以看出Dream和NonD常常一起缺失(r=0.91)。可能性较小的是 Sleep 和 NonD 一起缺失(r=0.49),以及 Sleep 和 Dream (r=0.20)。
- 2)计算指示变量和原始变量的相关性,查看缺失变量和其他变量的相关性
> cor(sleep,y,use="pairwise.complete.obs")
NonD Dream Sleep Span Gest
BodyWgt 0.22682614 0.22259108 0.001684992 -0.05831706 -0.05396818
BrainWgt 0.17945923 0.16321105 0.007859438 -0.07921370 -0.07332961
NonD NA NA NA -0.04314514 -0.04553485
Dream -0.18895206 NA -0.188952059 0.11699247 0.22774685
Sleep -0.08023157 -0.08023157 NA 0.09638044 0.03976464
Span 0.08336361 0.05981377 0.005238852 NA -0.06527277
Gest 0.20239201 0.05140232 0.159701523 -0.17495305 NA
Pred 0.04758438 -0.06834378 0.202462711 0.02313860 -0.20101655
Exp 0.24546836 0.12740768 0.260772984 -0.19291879 -0.19291879
Danger 0.06528387 -0.06724755 0.208883617 -0.06666498 -0.20443928
Warning message:
In cor(sleep, y, use = "pairwise.complete.obs") : 标准差为零
可以忽略矩阵中的警告信息和 NA 值,这些都是方法中人为因素所导致的。
在该矩阵中第一列,可以看出BodyWgt,Gest,Exp和NonD的缺失相关性较多,其三个变量的值越大,NonD越有可能缺失。其他列可以相似得出结果。
表中的相关系数并不特别大,表明数据是MCAR的可能性比较小,更可能为MAR。但是也有可能是非随机缺失。当缺乏强力的外部证据时,我们通常假设数据是MCAR或者MAR。
四、理解缺失数据的来由和影响
我们识别,探索的目的是要搞清楚:
- 缺失数据的比例多大?
- 缺失数据是否集中在少数几个变量上,抑或广泛存在?
- 缺失是随机产生的吗?
- 缺失数据间的相关性或与可观测数据间的相关性,是否可以表明产生缺失值的机制?
对于以上问题的解答,将会影响我们如何处理缺失值并且使用什么统计方法进行操作。
如果缺失数据集中在几个相对不太重要的变量上,那么你可以删除这些变量(列删除),然后再进行正常的数据分析。如果有一小部分数据(如小于10%)随机分布在整个数据集中(MCAR),那么你可以分析数据完整的实例(行删除),这样仍可以得到可靠且有效的结果。如果可以假定数据是MCAR或者MAR,那么你可以应用多重插补法来获得有效的结论。如果数据是NMAR,你则需要借助专门的方法,收集新数据
五、删除缺失值(行删除、列删除)
-
简单删除法用的比较多
直接删除含有缺失值的样本时最简单的方法,尤其是这些样本所占的比例非常小时,用这种方法就比较合理,但当缺失值样本比例较大时,这种缺失值处理方法误差就比较大了。在采用删除法剔除缺失值样本时,我们通常首先检查样本总体中缺失值的个数
1
六、插补法
6.1推理法
推理法是基于数据间的数学关系或者逻辑关系来进行判断填补缺失值的。
比如在 sleep 数据集中,变量 Sleep 是 Dream 和 NonD 变量的和。如果知道了其中的两个变量,那么另外一个缺失的变量就能够找出来。
又比如如果在一份问卷调查中有一个问题是是否是主管级以上职位以及直接下属的个数。如果职位那是空的,但是却填了下属的个数是大于1的,那么可以推断其是主管级以上。
6.2多重插补
在某些情况下,一些快速修复如均值替代或许是不错的办法。对于这种简单的办法,经常会给数据带来偏差。例如,均值代替法对数据的平均值不会产生变化(这是我们所希望的)。但会减小数据的方差,这不是我们所希望的。
我们可以使用mice包来进行链式方程的多元插补
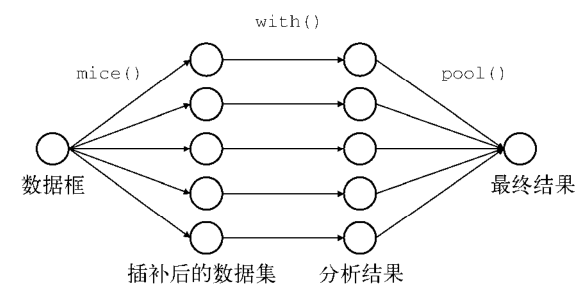
通过 mice 包应用多重插补的步骤
注意:在用mice时,一定要先把目标变量去除
利用mice包进行多元插补的步骤

- 1)首先使用mice函数将一个包含缺失值的数据集通过Gibbs抽样来进行预测插补。每个包含缺失值的变量默认可通过数据集中其他变量预测得来。对于每个变量我们可以选择预测模型的形式(基本插补法)和待选入的变量。预测的均值用来替换连续型变量中的缺失数据,而Logistic或多元Logistic回归则分别用来替换二值目标变量(两水平因子)或多值变量(多于两水平的因子)。其他基本插补法包括贝叶斯线性回归、判别分析、两水平正态插补和从观测值中随机抽样。
该过程不断迭代直到所有缺失值收敛为止。这个过程会产生多个(默认5个)被插补好的完整数据集,因为插补有随机的成分,所以这些完整数据集不一样 - 2)然后使用with函数依次对完整数据集应用统计模型
- 3) 最后使用pool函数将不同完整数据集的统计结果合并成一组结果
最终模型的标准误和p值都将准确地反映出由于缺失值和多重插补而产生的不
确定性。
下面我们通过实例来演示一下怎么用
6.2.1插补缺失值
library(mice)
data <- nhanes2
data[sample(25,5),1] <- NA
VIM::aggr(data)
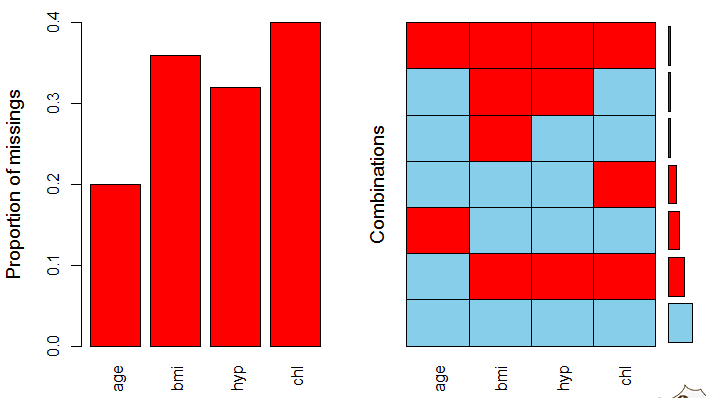
image.png
imp <- mice(data,m=5,meth="pmm",seed = 1234)
summary(imp)
Multiply imputed data set
Call:
mice(data = data, m = 5, method = "pmm", seed = 1234)
Number of multiple imputations: 5
Missing cells per column:
age bmi hyp chl
5 9 8 10
Imputation methods:
age bmi hyp chl
"pmm" "pmm" "pmm" "pmm"
VisitSequence:
age bmi hyp chl
1 2 3 4
PredictorMatrix:
age bmi hyp chl
age 0 1 1 1
bmi 1 0 1 1
hyp 1 1 0 1
chl 1 1 1 0
Random generator seed value: 1234

参数注解: 1. m=5指的是插补数据集的数量,5是默认值 2. meth='pmm'指的是插补方法。在这里,我们使用预测均值匹配(Predictive mean matching )作为插补方法。其他插补方法可以通过methods(mice)来查看。
Built-in univariate imputation methods are:
pmm any Predictive mean matching
midastouch any Weighted predictive mean matching
sample any Random sample from observed values
cart any Classification and regression trees
rf any Random forest imputations
mean numeric Unconditional mean imputation
norm numeric Bayesian linear regression
norm.nob numeric Linear regression ignoring model error
norm.boot numeric Linear regression using bootstrap
norm.predict numeric Linear regression, predicted values
quadratic numeric Imputation of quadratic terms
ri numeric Random indicator for nonignorable data
logreg binary Logistic regression
logreg.boot binary Logistic regression with bootstrap
polr ordered Proportional odds model
polyreg unordered Polytomous logistic regression
lda unordered Linear discriminant analysis
2l.norm numeric Level-1 normal heteroskedastic
2l.lmer numeric Level-1 normal homoscedastic, lmer
2l.pan numeric Level-1 normal homoscedastic, pan
2lonly.mean numeric Level-2 class mean
2lonly.norm numeric Level-2 class normal
2lonly.pmm any Level-2 class predictive mean matching
mice函数中有一个参数defaultMethod,解释为:
包含数字列的默认插补方法,包含2个级别的因子列和包含多于两个级别的(无序或有序)因子的列的三个字符串的向量。 如果没有指定,则使用以下默认值:pmm,预测平均匹配(数值数据)logreg,逻辑回归插补(二进制数据,2级因子)polyreg,无序分类数据的多重回归插补(因子> = 2级 )polr,比例赔率模型(有序,> = 2级)
从输出结果看,5个完整数据集同时被创建,预测均值(pmm)匹配法被用来处理每个缺失数据的变量。VisitSequence展示了被插补的变量,可以看到age有5个被插补,bmi9个被插补,hyp8个被插补,chl10个被插补。预测变量矩阵( PredictorMatrix )展示了进行插补过程的含有缺失数据的变量,它们利用了数据集中其他变量的信息。(在矩阵中,行代表插补变量,列代表为插补提供信息的变量,1和0分别表示使用和未使用。)
如果想看插补的数据,可以:
#通过提取 imp 对象的子成分,可以观测到实际的插补值
imp$imp$age
1 2 3 4 5
1 20-39 20-39 60-99 40-59 60-99
2 20-39 40-59 60-99 20-39 60-99
8 20-39 20-39 20-39 20-39 20-39
19 20-39 20-39 60-99 40-59 20-39
23 20-39 20-39 20-39 40-59 20-39
现在我们可以使用complete()函数来查看完整的插补数据
> complete(imp,action=1)
age bmi hyp chl
1 20-39 22.7 no 238
2 20-39 22.7 no 187
3 20-39 30.1 no 187
4 60-99 21.7 no 204
5 20-39 20.4 no 113
6 60-99 20.4 yes 184
7 20-39 22.5 no 118
8 20-39 30.1 no 187
9 40-59 22.0 no 238
10 40-59 30.1 yes 204
11 20-39 22.7 no 131
12 40-59 26.3 yes 184
13 60-99 21.7 no 206
14 40-59 28.7 yes 204
15 20-39 29.6 no 199
16 20-39 28.7 no 187
17 60-99 27.2 yes 284
18 40-59 26.3 yes 199
19 20-39 35.3 no 218
20 60-99 25.5 yes 186
21 20-39 26.3 no 238
22 20-39 33.2 no 229
23 20-39 27.5 no 131
24 60-99 24.9 no 186
25 40-59 27.4 no 186
参数action代表是刚才产生的5个插补数据集中的第几个
查看初始数据和插补数据的分布情况
library(lattice)
xyplot(imp,age~bmi+hyp+chl,pch=18,cex=1)
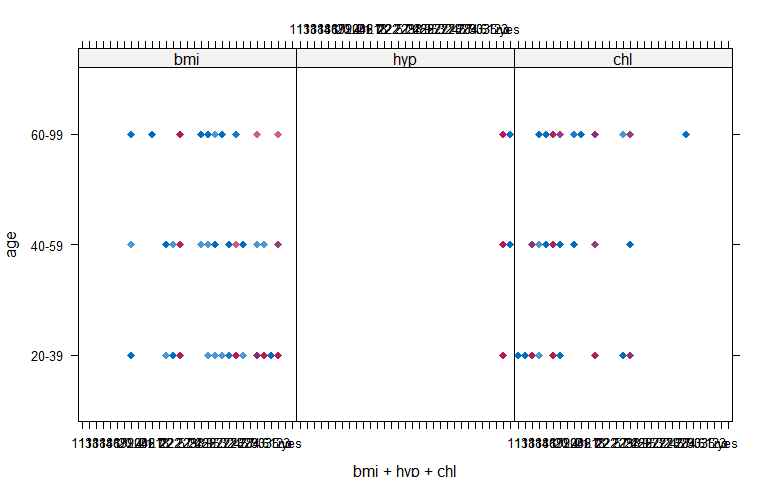
image.png
我们希望看到的是洋红点呈现出的形状(插补值)跟蓝色点(观测值)呈现出的形状是匹配的。从图中可以看到,插补的值的确是“近似于实际值”。
另一个有用的图是密度图:
densityplot(imp)
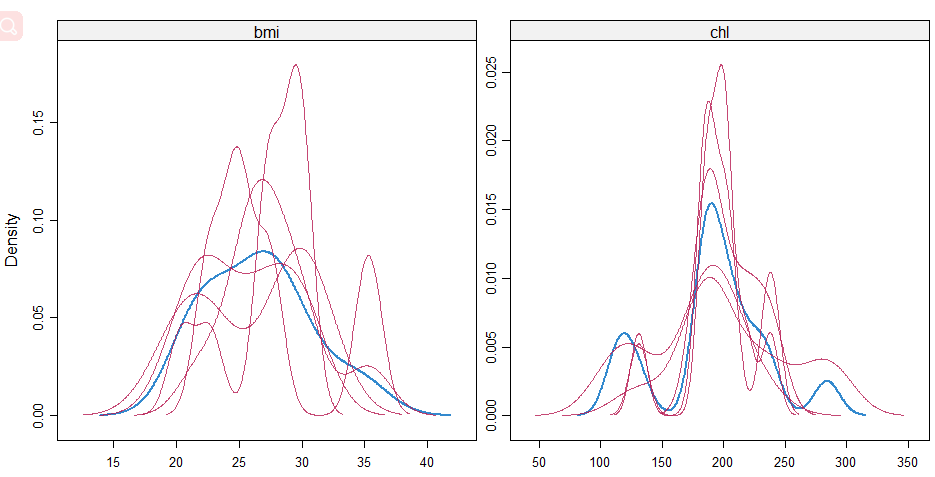
image.png
同样,我们希望看到的是洋红色的5条线(即创建出来的5个完整数据集)和蓝色线分布是相似的。洋红线是每个插补数据集的数据密度曲线,蓝色是观测值数据的密度曲线
另一个有用的可视化是由stripplot()函数得到的包含个别点的变量分布图
stripplot(imp,pch=20,cex=1.2)
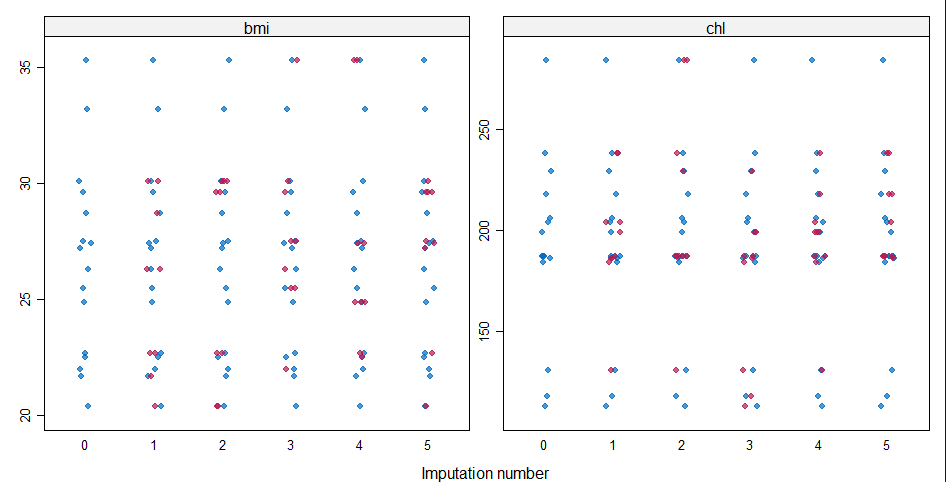
image.png
6.2.2合并
假设我们下一步的分析是对数据拟合一个线性模型。我们或许会问应该选择哪个插补数据集。mice包可以轻易的对每个数据集分别拟合一个模型,再把结果合并到一起。
fit <- with(imp,{
lm(bmi~age+hyp+chl)
})
pooled <- pool(fit)
summary(pooled)
est se t df Pr(>|t|) lo 95 hi 95 nmis fmi
(Intercept) 19.05591158 3.74955112 5.082185 15.883792 0.000113411 11.1024894 27.00933380 NA 0.1923327
age2 -3.65636382 3.05764709 -1.195810 4.375714 0.292523636 -11.8658629 4.55313522 NA 0.7103051
age3 -6.24533303 3.35922085 -1.859161 3.686536 0.142588045 -15.8932679 3.40260183 NA 0.7628207
hyp2 1.36228610 2.89278764 0.470925 5.737591 0.655062802 -5.7953290 8.51990118 NA 0.6181460
chl 0.05135278 0.02148144 2.390565 14.236578 0.031168511 0.0053514 0.09735415 10 0.2497429
lambda
(Intercept) 0.09665898
age2 0.60252591
age3 0.66160344
hyp2 0.50479575
chl 0.15126190
fit变量包含所有插补数据集的拟合结果,pool()函数将结果合并到一起。可以看到4个预测变量都不统计显著
请注意,这里除了lm()模型给出的结果外还包含其它列:fmi指的是各个变量缺失信息的比例,lambda指的是每个变量对缺失数据的贡献大小
6.3通过探索案例之间的相似性来填补缺失值
案例指的就是数据框中的行。比如说有两行数据是相似的,然后其中一行的某些变量值是缺失的,那么该缺失值很有可能与另外一行的值是相似的。那么问题来了,相似性该怎么定义呢?在很多方法中,利用欧氏距离来度量相似性是比较常见的。这个距离可以非正式的定义为两个案例的观测值之差的平方和。
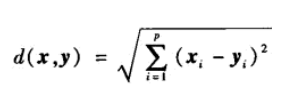
那当我们找到相似性的案例的时候,我们用什么值来代替缺失值呢?
第一种方法是简单的计算我们所指定的n个相似性案例的中位数来插补数值型数据,用n个案例的众数来插补缺失值。第二种方法是使用这些相似数据的加权均值。权重的大小随着距离待插补缺失值的个案增大而减小。用高斯核函数从距离获得权重。如果相似个案与待插补缺失值的个案的距离为d,则权重为:
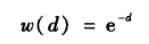
在DMwR2包中,有个knnImputation函数,他利用一个变种欧氏距离来找到k个近邻,这种欧氏距离可以同时应用于名义变量和数值变量。
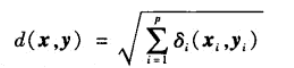

注意注意:图片中中间那个值不是C,而是0
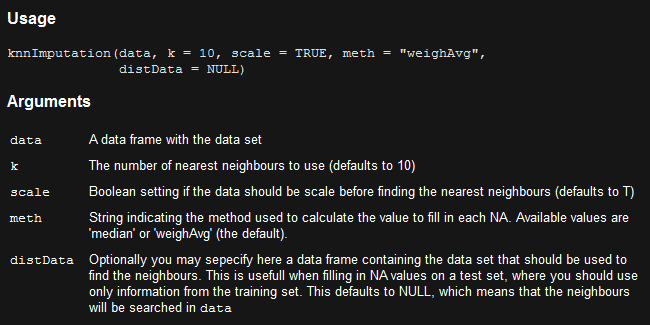
image.png
6.4均值插补

3
均值这一概念严格来讲应该是中心趋势指标,有算术平均值,几何平均值,结尾平均值,中位数,众数等。我们这里改插补什么值应该看变量的分布。如果变量是呈正态分布或者接近于正态分布,那么所有观测值都较好地聚集在平均值周围,因此平均值就就是填补该类变量缺失值的最佳选择。但是,如果变量是偏态的或者有离群点,平均值就不是代表中心趋势的最佳指标,这时候中位数反而是最好的代替者。同时,其实数据呈正态分布时,中位数和均值是相等的。所以对于数值型数据来说,我们可以用中位数来代替。而对于离散型数据来讲,众数是一个很好的选择。
- 在DMwR2包中有个centralImputation函数可以实现这个功能,但是不能进行分层插补,所以这里自己写了一个可以进行分层插补的函数
我们可以将这种方法创建一个函数,以后就可以反复调用了:
- 功能:能够进行分组插补缺失值(数值型为中位数,分类型为众数)
Calculate <- function(x,df=NULL,wt=NULL){
#####################################
#df:数据框
#wt:字符串(df中的分类变量名称)
#####################################
if(is.numeric(x)){
if(is.null(wt)){
median(x,na.rm = TRUE)
}else{
aggregate(x,by=list(df[,wt]),function(a) median(a,na.rm = TRUE))
}
}else{
x <- as.factor(x)
if(is.null(wt)){
levels(x)[which.max(table(x))]
}else{
aggregate(x,by=list(df[,wt]),function(a) levels(a)[which.max(table(a))])
}
}
}
FillMissingValue <- function(data,by=NULL){
####################################
#data:数据框
#by:字符串(分类变量名,用于分组插补缺失值)
###################################
if(is.null(by)){
for(i in seq(ncol(data))){
index <- which(is.na(data[,i]))
data[index,i] <- Calculate(data[,i])
}
}else{
for(i in seq(ncol(data))){
for(j in levels(data[,by])){
index <- which(is.na(data[,i]) & data[,by]==j)
a <- Calculate(data[,i],df=data,wt=by)
data[index,i] <- a[which(a[,1]==j),2]
}
}
}
return(data)
}
我们来测试一下:
b <- mice::nhanes2
VIM::aggr(b,prop=F,numbers=T)
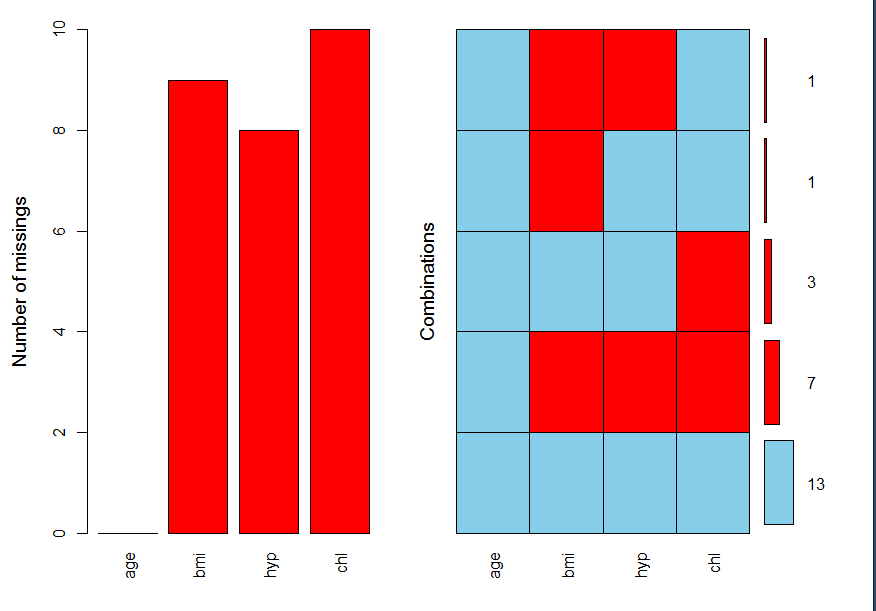
image.png
- 不分组插补
b<-FillMissingValue(b)
VIM::aggr(b,prop=F,numbers=T)
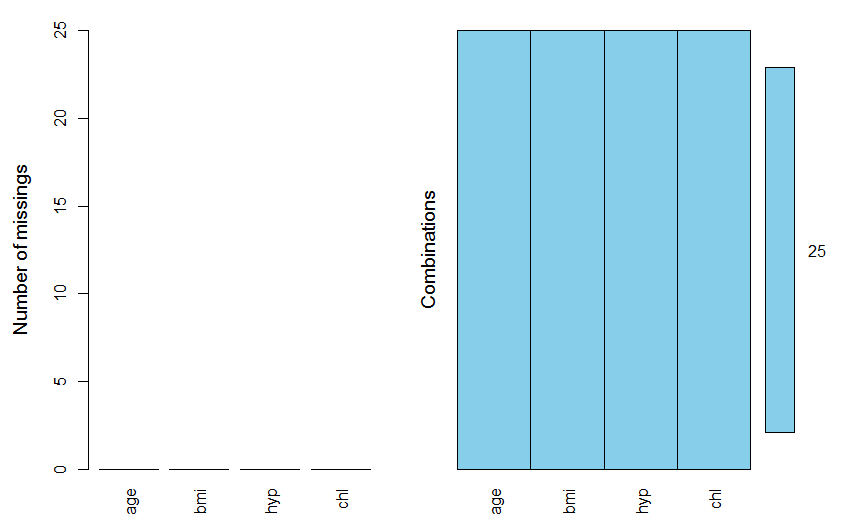
image.png
- 以age为分组变量插补缺失值
b <- mice::nhanes2
test <- FillMissingValue(b,by="age")
VIM::aggr(test,prop=F,numbers=T)
可以对比下两次的插补,值是不一样的
可以将这两个函数保存为一个R文件,要用的时候调用就行了

4
6.5极大似然估计

5
6.6 随机森林插补
z <- missForest::missForest(data)
z$ximp
age bmi hyp chl
1 20-39 29.60491 no 182.6688
2 60-99 22.70000 no 187.0000
3 20-39 29.57666 no 187.0000
4 60-99 25.42770 yes 234.1083
5 20-39 20.40000 no 113.0000
6 60-99 24.29740 no 184.0000
7 20-39 22.50000 no 118.0000
8 20-39 30.10000 no 187.0000
9 40-59 22.00000 no 238.0000
10 40-59 27.42942 yes 216.9633
11 20-39 29.60491 no 182.6688
12 40-59 27.42942 yes 216.9633
13 60-99 21.70000 no 206.0000
14 40-59 28.70000 yes 204.0000
15 20-39 29.60000 no 182.6688
16 20-39 29.60491 no 182.6688
17 60-99 27.20000 yes 284.0000
18 40-59 26.30000 yes 199.0000
19 20-39 35.30000 no 218.0000
20 60-99 25.50000 yes 234.1083
21 20-39 29.60491 no 182.6688
22 20-39 33.20000 no 229.0000
23 20-39 27.50000 no 131.0000
24 60-99 24.90000 no 188.4600
25 40-59 27.40000 no 186.0000
还有很多缺失值的处理方法,以后用到再学吧
其他方法可以参考:http://blog.csdn.net/dminer/article/details/2504091
还有mice包的多元插补可以参考:https://www.jstatsoft.org/article/view/v045i03

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









