




 本文探讨了Torch框架中两个常见的问题:一是Tensor在网络层传递过程中的引用赋值与深拷贝区别;二是getParameters()函数使用不当导致的参数共享丢失问题。文章通过实验对比了不同操作顺序对网络参数的影响。
本文探讨了Torch框架中两个常见的问题:一是Tensor在网络层传递过程中的引用赋值与深拷贝区别;二是getParameters()函数使用不当导致的参数共享丢失问题。文章通过实验对比了不同操作顺序对网络参数的影响。
Preface
这段时间一直在苦练 Torch,我是把 Torch 当作深度学习里面的 Matlab 来用了。但最近碰到个两个坑,把我坑的蛮惨。
一个是关于 Torch 中赋值引用、深拷贝的问题,另一个是关于 getParameters() 获取参数引发的问题。
所以这部分就不放在之前的博文 Code Zoo - Lua & Torch 中了,单独拎出来。
第一个坑: Torch 中的引用赋值 以及 深拷贝
第一个坑是,Torch 中的输入 Tensor,经过一个网络层之后,输出的结果,其 Size 会随着之后输入数据 Size 的变化而变化。这个问题,我在知乎上提问了:https://www.zhihu.com/question/48986099。中科院自动化所的博士@feanfrog 给我做了解答。在这里,我再总结一下。
输入一个数据,比如说随机生成:
x1 = torch.randn(3, 128, 128))经过一网络 convNet,如卷积层:
convNet = nn.SpatialConvolution(3,64, 3,3, 1,1, 1,1))进行 forward 之后,其输出结果为 y1,其 Size:
64×128×128
.
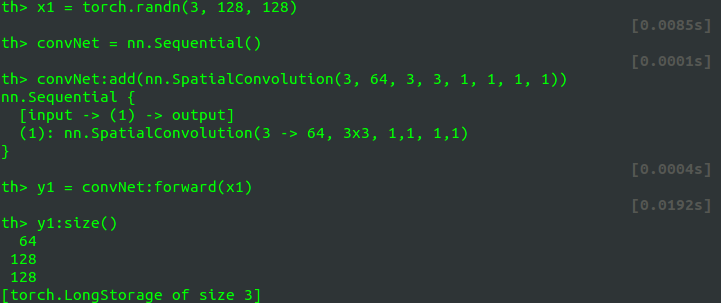
但输出的这个 Size 大小,会随着之后的输入数据的 Size 的变化而变化!这是诡异的地方……
如又输入:
x2 = torch.randn(5, 3, 128, 128) 这个 x2 经过 convNet:forward:
>y2 = convNet:forward(x2)
>y2:size()
5
64
128
128
[torch.LongStorage of size 4]这个 y2 的 size 为
5×64×128×128
,这是应该的。
但是请看 y1:size():
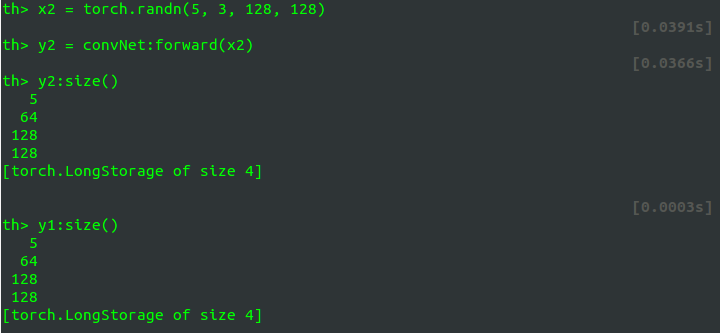
y1 的 size 也变成了
5×64×128×128
!
我百思不得其解,想了两天,都没找出愿意(太渣了……),实在没有办法,就到知乎上提问了,结果真有大神 @beanfrog 给我解答了:
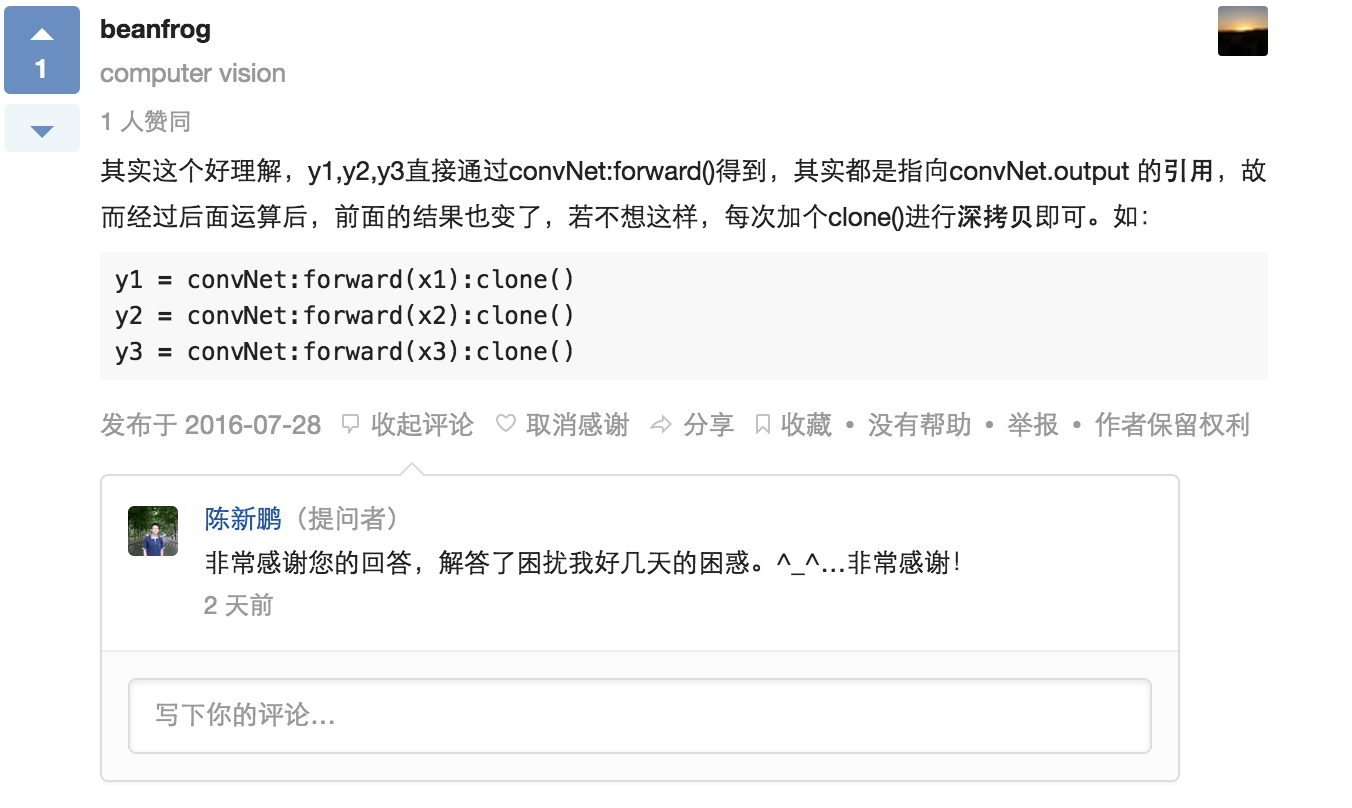
原来 Torch 中为了提高速度,model:forward() 操作之后赋予的变量是不给这个变量开盘新的存储空间的,而是 引用。就相当于 起了个别名。
不光这里,torch里面向量或是矩阵的赋值是指向同一内存的,这种策略不同于 Matlab。如果想不想引用,可以用 clone() 进行 深拷贝,如下的例子:
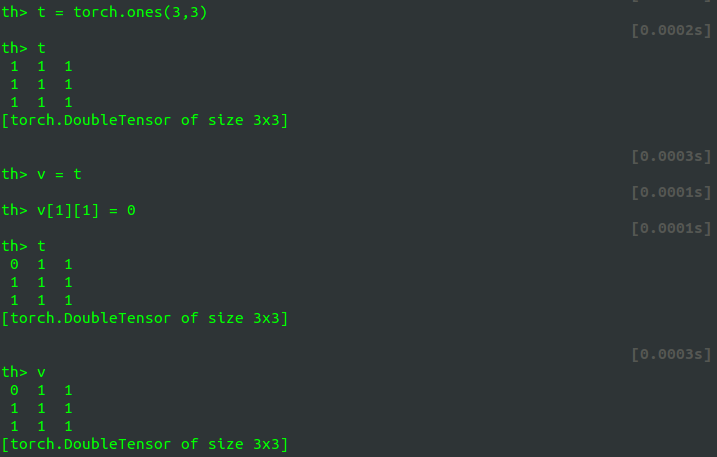
当改变变量
v 的第一个元素的值时,变量
t 也随之变化。
第二个坑: Torch 中 getParameters 获取参数引起的疑惑
当有如下的代码:
require 'nn'
local convNet = nn.Sequential()
convNet:add(nn.Linear(2, 3))
convNet:add(nn.Tanh())
local convNet2 = convNet:clone('weight', 'bias', 'gradWeight', 'gradBias')
local params, gradParams = convNet:getParameters()
params:fill(0)
print(convNet2:get(1).weight)此时的输出为:
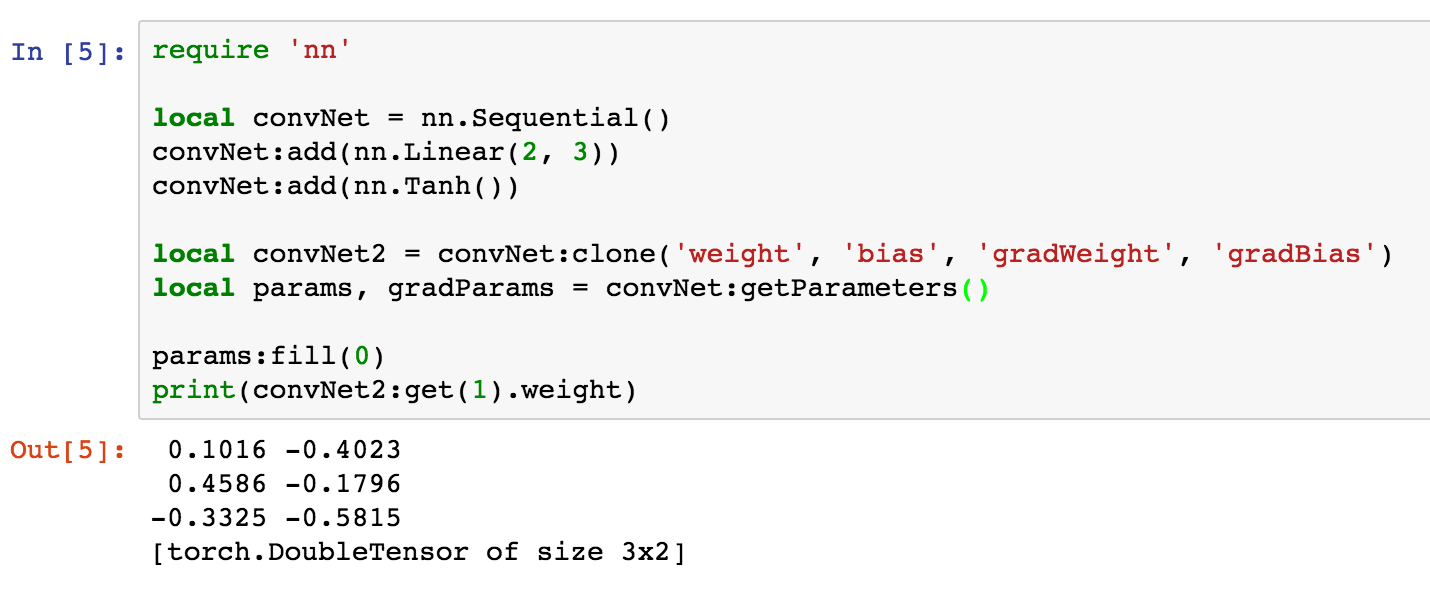
感觉输出结果很显然的样子。但当将上述的代码做一下微调:
require 'nn'
local convNet = nn.Sequential()
convNet:add(nn.Linear(2, 3))
convNet:add(nn.Tanh())
local params, gradParams = convNet:getParameters()
local convNet2 = convNet:clone('weight', 'bias', 'gradWeight', 'gradBias')
params:fill(0)
print(convNet2:get(1).weight)输出的结果为:

仅仅将代码中下面的两行做了对调:
local convNet2 = convNet:clone('weight', 'bias', 'gradWeight', 'gradBias')
local params, gradParams = convNet:getParameters()结果就是两种不同的结果。
看一下别人的解释:
This is not really a bug though.
getParameters()is a bit subtle, and should be documented properly.It gets and flattens all the parameters of any given module, and insures that the set of parameters, as well as all the sharing in place within that module, remains consistent.
In the example you show, you’re grabbing the parameters of ‘convNet’, but
getParameters()doesn’t know about the external convNet2. So sharing will be lost.
我自己的理解是:
在第一段代码中,顺序是:
local convNet2 = convNet:clone('weight', 'bias', 'gradWeight', 'gradBias')
local params, gradParams = convNet:getParameters()是先进行的拷贝 clone(),是 深拷贝。convNet2 与 convNet 并不是同一个存储。之后再 getParameters(要所有的参数 拉平) 的时候,已经不关 convNet2 的事了。
这时候再通过 params:fill(0) 赋值的时候(因为 getParameters() 得到的只是参数的引用,与原先参数指向的同一块内存,所以可以通过 params:fill(0) 这种方式给 convNet 网络赋值),对 convNet2 已经没有影响了。所以 convNet2 保持原先的值。
而第二段代码,顺序是:
local params, gradParams = convNet:getParameters()
local convNet2 = convNet:clone('weight', 'bias', 'gradWeight', 'gradBias')注意这时候,convNet 中的存储结构,已经被 getParameters() 函数给 拉平 了,相当于是 convNet 的结构已经被破坏了。
因为在官方的 Module 文档中的 getParameters() 函数这块,有这么一句话:
This function will go over all the weights and gradWeights and make them view into a single tensor (one for weights and one for gradWeights). Since the storage of every weight and gradWeight is changed, this function should be called only once on a given network.
下面 convNet2 再 clone('weight',...) 这样拷贝,已经失效了。所以,实际上,这时候 convNet2 进行的所谓的 深拷贝,并不是真正的 深拷贝,而是 失效的深拷贝 。
下面我们可以通过加一句话验证一下,上面的深拷贝是失效的:
require 'nn'
local convNet = nn.Sequential()
convNet:add(nn.Linear(2, 3))
convNet:add(nn.Tanh())
local params, gradParams = convNet:getParameters()
local convNet2 = convNet:clone('weight', 'bias', 'gradWeight', 'gradBias')
-- 加上下面这一句, 这一句的拷贝不指定拷贝的参数, 如 weight, bias 这些
-- 而是默认的进行深拷贝
local convNet3 = convNet:clone()
params:fill(0)
print(convNet2:get(1).weight)
print('------------------------')
print(convNet3:get(1).weight)我们在中间加了一句:local convNet3 = convNet:clone(),自动的进行深拷贝,而不是指定参数。看输出结果:

看到了吗?!
convNet3 的参数与 convNet 不是同一块存储地址,深拷贝成功。而 convNet2 的深拷贝失效,所以当 params:fill(0) 的时候,convNet2 的参数也变了。但 convNet3 的深拷贝成功!
总结一下:
实验证明,我的猜想是成功的。由于 getParameters() 获取参数使得 convNet 的网络参数被 拉平 了,所以 convNet2 的深拷贝方式就已经失效了,convNet2 本质上跟 convNet 还是共用的一块内存地址:
local convNet2 = convNet:clone('weight', 'bias', 'gradWeight', 'gradBias')反而不指定参数的 convNet3 的深拷贝方式,反而保持有效:
local convNet3 = convNet:clone()Reference
- 推荐一个博客,我在这个博客中也找到了 Torch 里这个坑的叙述,写的也不错:http://blog.csdn.net/hungryof?viewmode=contents,以及 学习Torch框架的该看的资料汇总(不断更新)
- Torch 的 Github Issues 版块上的讨论:Problem with getParameters?
- Google groups 中 Torch 板块的一篇讨论贴: Triplet Net, Parallel table and weights sharing
- 最后,
nn Modules的官方文档还是得多读读:https://github.com/torch/nn/blob/master/doc/module.md

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









