






1介绍
**搜索数据中模式的问题是基本的并且具有长久和成功的历史。例如,在16世纪Tycho Brache的大量天文观测让开普勒发现了行星运动的经验法则,这为经典力学的发展提供了一个跳板。同样,原子光谱规律的发现对20世纪早期的量子物理学的发展和验证起到了关键作用。模式识别领域通过计算算法的使用从数据中自动发掘规律并使用这些规律采取行动,如将数据分类成不同的类别。
考虑识别手写体数字的例子,如图1.1。每个数字对应一个28×28像素的图像,因此可以用一个矢量x(由784个实数组成)来表示。我们的目标是建立一个机器,它将这样的向量x作为输入,并且产生数字0到9作为输出。由于手写广泛的可变性,这不是一个平凡问题。可以通过基于笔画形状来区分数字的手工规则或启发式信息得到解决,但在实践中这种方法导致规则和特例扩散等问题,总是给出了差的结果。*
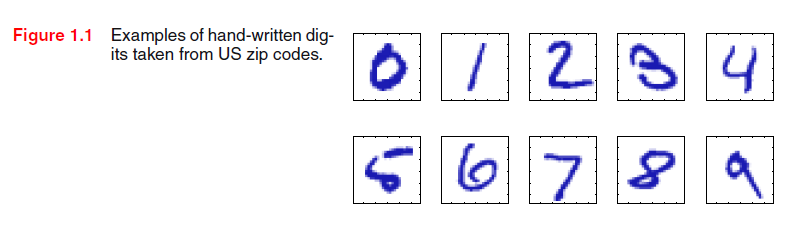
通过采用机器学习方法可以得到更好的结果,这种方法用一大组N个数字{X1,, ,XN}(叫做训练集)来调节自适应模型的参数。训练集中数字的类别预先已知,典型地通过单个地检查并手工标记他们。我们可以使用目标向量t来表达数字的类别,该向量代表对应数字的身份。向量形式来代表类别的合适技术将在稍后讨论。请注意,对于每个数字图像x都有这样的一个目标向量。
运行机器学习算法的结果可以用一个函数y(x)来表示,它接受一个新的数字图像x作为输入,并产生一个输出向量y,编码方式和目标矢量一样。在训练数据的基础上,函数y(x)的具体形式在训练阶段被确定下来,也被称为学习阶段。一旦模型经过训练,它就可以确定新数字图像的身份,新图像组成一个测试集。分类新例子(不同于训练例子)的能力被称为泛化。在实际应用中,输入向量的可变性将是这样的,训练数据可以包含所有可能输入向量的一小部分,所以泛化是模式识别的中心目标。
在大多数实际应用中,原始输入变量通常被预处理,转化他们到新的变量空间,希望在这个空间中模式识别问题将更容易解决。例如,在数字识别问题上,数字的图像通常被翻译和缩放,使得每数字被包含在一个固定大小的盒子中。这大大减少了每类数字的变异,因为所有数字的位置和规模现在是一样的,这使得随后的模式识别算法更容易区分不同的类。这个预处理阶段有时也被称为特征提取。请注意,新的测试数据必须用与训练数据相同的步骤进行预处理。
执行预处理也可能是为了加快计算速度。例如,如果目标是高分辨率视频流中的实时人脸检测,那么计算机必须每秒处理数量巨大的像素,并且直接呈现这些到一个复杂的模式识别算法在计算上是不可行的。相反,我们的目标是要找到有用的特征,这些特征能快速的计算但依然保存有用的差别信息,该信息能使够区分出是否是脸。随后这些特征作为模式识别算法的输入。例如,一个矩形子区域上图像强度的平均值可以被非常有效的估计出来(Viola和Jones,2004),和一组这样的特征可以证明在快速人脸检测上是非常有效的。因为这种特征的数量比像素的数量少,所以这种前处理代表维数降低的一种形式。预处理期间必须小心,因为信息经常被丢弃,并且如果该信息对这个问题的解决方案很重要,那么系统的整体精度可能受损。
在监督学习问题的应用中,训练数据由输入向量和其相应的目标向量实例组成。例如数字识别,其目的是给每个输入向量分配一个有限数目的离散类别,它被称为分类问题。如果所需的输出由一个或多个连续变量组成,那么任务被称为回归。回归问题的一个例子是预测化学制造过程的产出,该过程中输入包括反应物的浓度,温度和压力。
在其它模式识别问题中,训练数据由一组输入的向量X组成,但他们没有任何相应的目标值。这种无监督学习问题的目标可能是发现数据中类似的几组实例,称为聚类,或是为了确定输入空间中的数据分布,称为密度估计,或是为了可视化的目的,将数据空间从高维映射到两维或三维。
最后,强化学习(1998年Sutton和Barto)的技术关注的问题是寻找合适的行动,为了最大化奖励接受给定的情况。这里的学习算法没有给出最佳输出的实例,相比监督学习,它必须通过反复试验的过程来发现他们。通常有一个状态和动作序列,在该序列中学习算法与它的环境进行相互。在许多情况下,目前的行动不仅影响了即时奖励,也在所有随后的步骤上影响了奖励。例如,通过使用适当的强化学习技术,神经网络可以学习双路器游戏到一个高水平(Tesauro,1994年)。这里的网络必须学会接受一个板位置作为输入,跟随一个骰子抛出的结果,产生举动作为输出。通过让网络和自身的副本做游戏是可以做到了。一个主要的挑战是,双陆棋可能涉及数十个移动,但它仅在游戏结束时才得到胜利的奖励。然后奖励必须适当地归因到所有导致它的移动,即使有些好有些不好。这是一个信用分配问题的例子。强化学习的一般特征是探索(系统试图尝试各种新的行动来看看他们是多么有效)和开发(系统充分利用产生高奖励的动作)之间的折衷。太过于专注勘探或开发会产生糟糕的结果。强化学习仍然是机器学习研究的活跃领域。然而,细节的处理超出了本书的范围。
虽然这些任务都需要自己的工具和技术,但支撑他们的许多关键思想对所有这些问题是很普遍的。本章的主要目标之一是用一个相对非正式的方式介绍几个最重要的概念,并用简单的例子来说明它们。在这本书的后面,我们将看到这些相同的想法重新出现在更复杂的模型中,这些模型适用于现实世界的模式识别应用。本章还提供了三个重要工具的独立介绍,这些工具将贯穿全书,即概率论,决定论和信息论。虽然这些听起来似乎是令人望而生畏的话题,实际上他们是简单的,如果机器学习要被更好地应用于实际中那么对他们有一个清晰的认识是非常重要的。
to be continue















 1100
1100
评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








