






目前做机器学习的好处之一是人们实际在使用它!我们在日常基础上交互的许多系统后端是通过机器学习来驱动。在大多数这种系统中,随着用户与系统进行交互,系统设计者自然而然地希望优化模型随着时间,从而改善用户体验。为了给讨论打基础,让我们考虑一个在线门户网站的例子,就是试图给用户呈现有趣的新闻。用户谈到门户网站,并且基于门户网站提供给用户的任何信息,它推荐一个(或多个)新闻故事。用户选择读或不读该故事。自然而然,门户想更好地裁剪它显示的故事以满足用户的口味,如果用户开始更频繁地点击所显示的故事就发现这个现象。
一个自然的想法是使用过去的日志并训练机器学习模型,该模型更喜欢用户点击的故事并阻止被用户避开的故事。这听起来像一个简单的分类问题,我们可以用一个现成的算法。这的确合理地做到了,离线日志表明最新的训练模型比旧的有更多的点击。新的模型被部署,之后发现它的性能并没有希望的那样好,或者说甚至比之前更差!出了什么问题?自然反应通常是:(a)机器学习算法需要改进,或(b)我们需要更好的特征,或(c)我们需要更多的数据。可惜的是,在大多数情况下,正确的答案都不是上面的答案,而是(d)。让我们通过一个简单的例子来看看为什么这是真的。
想象一个简单的世界里,我们的一些用户一些来自纽约而其他人来自西雅图。我们的一些新闻报道涉及到金融而其他的涉及到科技。让我们进一步想象基于城市和主题的新闻文章点击概率(以下CTR表示点击率)有如下分布:
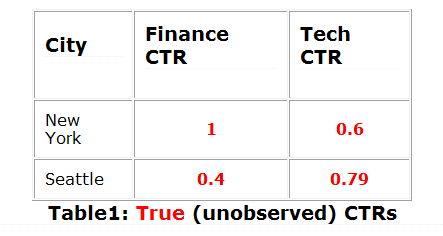
当然,我们在设计系统之前没有这个信息,所以我们的启动系统根据一些启发式规则推荐文章。试想一下,我们的用户的规则:
- 纽约用户得到科技报道,西雅图用户得到金融报道。
现在,我们根据这个系统收集点击数据。随着我们获得越来越多的数据,我们逐渐得到了科技报道CTR与纽约用户的准确估计,以及金融报道与西雅图用户的估计(0.6和0.4 )。然而,我们没有其他两个组合的信息。因此,如果我们训练机器学习算法来最小化预测CTR和观测CTR之间的平方损失,它很可能预测到其他两块观察CTR的平均值(即0.5)。在这一点上,我们的猜测是这样的:
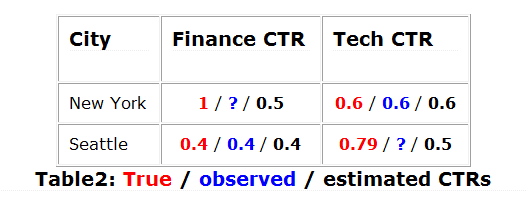
注意,即使有无限的数据和全能的学习也会出现这种情况,所以机器学习不会以任何方式出现故障。给定这些估计,我们自然知道对西雅图的用户展示金融报道是错误的做法,并切换到科技。但是科技在纽约看起来还不错,我们坚持下去。我们的新策略是:
- 纽约和西雅图都得到科技报道
运行一会新系统,我们将修复西雅图科技CTR的错误估计(即从0.5升到0.79)。但是,我们仍然没有信号表明纽约用户更喜欢财政。事实上,即使有无限的数据,该系统在这一点上将坚持这种次优的选择,我们的CTR估计会看起来像:
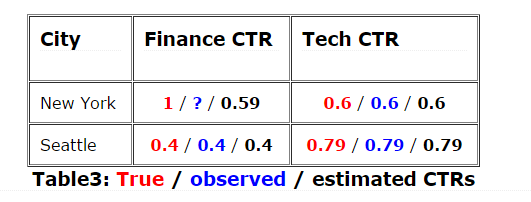
现在我们可以评估之前的主张:
1.更多的数据没有帮助:因为观测和真实的点击率匹配我们收集数据的任何地方
2.更好的学习算法没有帮助:因为预测和观察的点击率和我们收集数据的任何地方一致
3.更好的数据有帮助!我们不应该在观察列中有空白单元格
这似乎很简单修复。我们真正知道比完全忽略表格中的一个单元观测要更好。有了好的目的,我们决定收集所有单元的数据。我们选择使用以下规则:
- 西雅图用户白天得到科技报道,晚上得到金融报道
- 类似的,纽约用户白天得到科技报道,晚上得到金融报道
我们现在收集每个单元上的数据,但我们发现,我们的估计仍然带领我们到一个次优的策略。进一步的研究可能揭示了当市场是开放的时候用户更可能白天阅读金融报道。所以,当我们只在夜间显示金融报道时,我们低估了金融CTR,最终得到错误的估计。认识到我们方法的错误,我们会再次尝试解决这个问题,然后运行到另一个问题,等等。
上面我们已经发现的问题在于混杂变量。有很多精彩的工作和技术可以用来绕过实验中的混杂变量。这里,我提最简单的一个,也许是最通用的一种:随机。我们的想法是,不要根据一个修复确定性规则来推荐报道给用户,而是允许不同的文章根据某种分布呈现给用户。这种分布不必是均匀的。事实上,好的随机化可能会集中于好文章,以便不降低用户体验。但是,只要我们添加足够的随机化,我们就可以从我们的实验数据中获得批量一致的反估计。有越来越多的文献是讲如何做到这一点。一个很好的论文(其中涉及到了一些技术,并提供了经验评估)http://arxiv.org/abs/1103.4601。在计算微软上广告的情景中,一个更复杂的例子在http://leon.bottou.org/papers/bottou-jmlr-2013讨论。
to be continue…















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









