






模型选择
使用最小二乘的多项式曲线拟合例子中,我们看到多项式有一个最优阶给出了最好的泛化。多项式的阶控制模型中自由参数的数量,并由此管理模型的复杂度。随着正规化最小二乘,正规化系数λ还控制模型的有效复杂度,而对于较复杂的模型,如混合分布或神经网络可能有多个参数管理复杂性。在实际应用中,我们需要确定这种参数值,并这样做的主要目的通常是要实现对新数据的最佳预测表现。此外,和找到给定模型中复杂参数的合适值一样,我们可能希望考虑一系列不同类型的模型,以找到我们具体应用中最好的一个。
我们已经看到,在最大似然方法中,由于过拟合问题,对看不见数据的预测性能没有一个很好的指标。如果数据充足,那么一种方法是只使用一些现有的数据来训练一系列模型,或复杂性参数有很大范围的给定模型,然后在独立数据(有时被称为验证集)上对他们进行比较,选择一个具有最好预测性能的模型。如果模型设计是用有限的数据集迭代许多次,那么对验证数据的过度拟合会发生,所以搁置第三组测试集是有必要的,在该测试集上选定模型的性能被最后评估(此句实在不懂,求大家提供建议)。
然而,在许多应用中训练和测试数据的供应是有限的,为了建立良好的模型,我们希望用尽可能多的可用数据来进行训练。然而,如果验证集比较小,它会给出预测性能的噪音估计。这个难题的一种解决办法是使用交叉验证,这示于图1.18。这使得可用数据的(S-1)/S部分用于训练从而充分利用了所有数据来评估性能。当数据特别少,考虑S = N是比较合适的,其中N是数据点的总数,这给出了leave-one-out技术。

交叉验证的一个主要缺点是必须执行的训练运行次数因为因子S被增加,可以证明对模型来说这是有问题的,训练本身在计算上就有很高的代价。另一个是关于方法的问题,诸如交叉验证用单独的数据来评估性能,对一个模式我们可能有多个复杂的参数(例如,可能有若干正则化参数)。在最坏的情况下,探索这种参数的组合设定可能需要大量的训练运行,参数的数量是指数形式的。显然,我们需要一个更好的方法。理想情况下,这应该只依赖于训练数据,允许多个超参数和模型类型用单个训练运行进行比较。因此,我们需要找到一种性能衡量,它只取决于训练数据并且由于过度拟合没有偏差。
历史上各种“信息标准”已经被提出来,试图加入一个惩罚项来补偿更复杂模型的过拟合从而达到纠正最大似然偏差的目第。例如,Akaike信息标准,或AIC(Akaike,1974)选择这样的模型,其中

是最大的。这里p(D | wML)是最好拟合的对数似然,并且M是模型中可调参数的数量。这个量的一个变种,称为贝叶斯信息准则,或BIC,将在第4.4.1节中讨论。这样的标准不考虑模型中参数的不确定性,但是,在实践中他们倾向于过于简单的模型。因此,我们在3.4节转到完全贝叶斯方法,那里我们将看到复杂性处罚是如何以自然和主要的方式出现的。
维数诅咒
在多项式曲线拟合的例子中,我们只有一个输入变量x。然而,在模式识别的实际应用中,我们将不得不面对包括很多输入变量的高维空间。正如我们现在讨论的,这带来了一些严重的挑战并且是影响模式识别设计的一个重要因素。
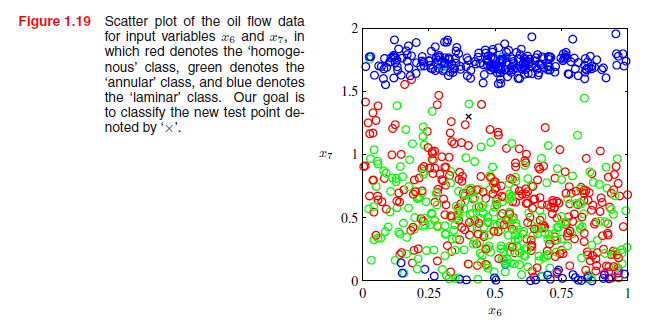
为了说明问题,我们考虑一个合成产生的数据集,该数据表示对含有油,水和煤气混合物(Bishop和James,1993年)管道进行测量。这三种材料可以用三种不同的几何构型(“均匀”,“环状”,和“层状”)中的一个来表示,并且三种材料的小部分也可以不相同。每个数据点包括一个12维输入矢量,该矢量由伽玛射线密度计的测量组成,密度计沿着狭窄的射线光束测量出伽马射线的衰减。这个数据集详细的描述在附录A中。图1.19显示了这个数据集中的100个点,这个图显示了两个测量值x6和x7(为了图示,其余十个输入值被忽略)。每个数据点标上它属于的几何类,我们的目标是用这个数据作为训练集从而对一个新的观察(x6,x7)进行分类,例如图1.19中的十字标。我们注意到,十字标被许多红点包围,因此我们可能认为它属于红色类。然而,附近也有很多绿点,所以我们可能会认为它可以属于绿色类。它属于蓝色类似乎是不大可能的。这里的直觉是十字标的身份应该根据附近的点来确定而不是距离远的点。事实上,这种直觉被证明是合理的,我们将在后面的章节中详细讨论。
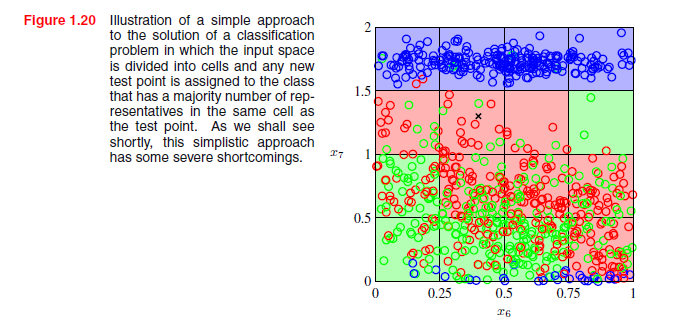
我们怎样才能把这种直觉变成学习算法呢?一个非常简单的方法是划分输入空间到规则单元,如图1.20所示。当我们给定一个测试点并希望预测它的类别时,我们首先确定它属于哪个单元格,然后我们会发现落入同一单元的所有训练数据点。预测测试点的标识就是落到测试点单元格中数量最多的训练点的类被。
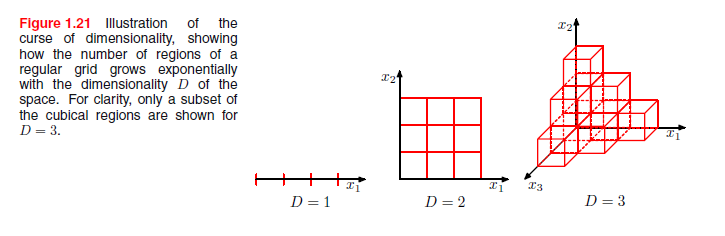
这个幼稚的做法有许多问题,当我们扩展到许多输入变量(对应于更高维的输入空间)的情况时,最严重的问题就显现出来了。问题的根源示于图1.21,这表明如果我们把空间区域分成规律的单元,那么单元的数量随着空间维数呈指数增长。指数数量的单元问题是也就是我们需要一个指数数量的训练数据来确保单元不是空的。显然,我们不希望在超过几个变量的空间上应用这样的技术,所以我们需要找到一个更加复杂的方法。
回到多项式曲线拟合的例子并考虑我们是如何扩展这种方法来处理几个变量的输入空间,我们能都对高维空间问题有更深入的见解。如果我们有D输入变量,则一般系数高达3的多项式将采取下面的形式:
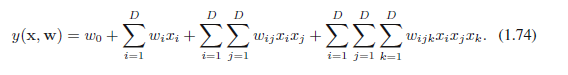
随着D的增大,独立系数(由于变量x之间的交换对称性,不是所有的系数都是独立的)成比例增长到D3。在实践中,为了捕捉到数据中复杂的依赖关系,我们可能需要使用一个高阶多项式。对于一个M阶的多项式,系数数量的增长和DM一样。虽然这是一个幂增长而不是指数增长,但它指向的方法是很笨重的并且实用性很有限。
当我们考虑更高维空间时,我们的几何直觉(由三维空间中的生活而形成的)会失效。作为一个简单的例子,考虑D维空间中半径r =1的球,并问半径r =1-e和r=1之间球体体积是多少,我们可以估计该部分体积,注意半径为r的球体积必须缩放为rD,所以我们写:

常数KD只依赖于D,因此所求的部分可以写作:
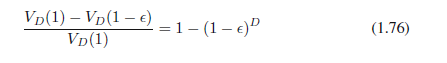
它被描绘成针对不同的D,e的一个函数,如图1.22。我们看到,对于较大的D,在e比较小时这部分就已经接近一。因此,在高维空间,大部分球体的体积集中在靠近表面的薄层上。
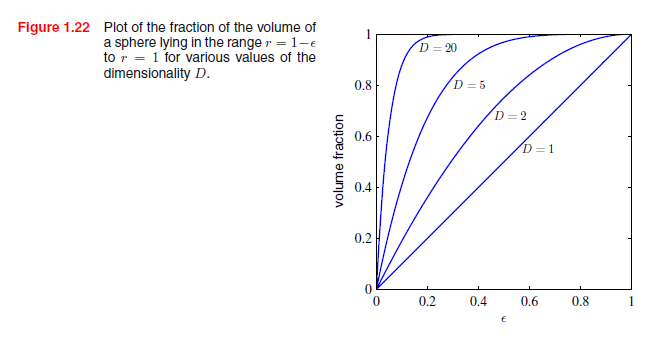
作为与模式识别直接相关的例子,考虑高维空间中高斯分布的特性。如果我们从笛卡尔变换到极坐标,然后积分方向变量,我们得到了密度ρ(r)的表达式。因此,p(r)Δr是半径r上厚度为Δr薄层的概率质量。对于不同的D值,这种分布被绘制在图1.23中,我们看到,对于较大的D,高斯概率质量集中在薄层中。
多维空间中出现的严重困难有时称为维的诅咒(Bellman,1961年)。在这本书中,我们将大量使用涉及一个或两个维度输入空间的图解实例,因为这特别易于用图形方式来说明技术。然而,警告一下读者,并非所有低维空间产生的直觉能推广到多维空间。
虽然维度诅咒确实提高了模式识别应用的重要问题,但这并不妨碍我们寻找有效的技术来适用于高维空间。这种情况的原因是双重的。首先,真实的数据通常被限制在较低维度的空间区域,尤其是目标变量中重要变量可能是非常局限的。其次,真实的数据通常会表现出某些平滑性(至少局部上),使得输入变量中大部分小变化在目标变量上会产生小的变化,所以我们可以利用局部插值技术给输入变量的新值做目标变量的预测。成功的模式识别技术利用了一个或两个属性。例如,考虑制造业中的一个应用,图像捕获传送带上相同的平面物体,目标是确定其方向。每个图像是高维空间的一个点,高维空间中的维度由像素的数目确定。因为目标可以出现在图像中的不同位置并有不同的方向,图像之间有三个可变的自由度,一组图像是嵌入到高维空间中的一个三维复平面。由于目标位置或取向与像素强度之间的复杂关系,这个复平面将是高度非线性的。如果目标是学习一个模型,该模型可以得到一个输入图像并输出目标取向(不考虑它的位置)。那么就只有一个可变的自由度是明显的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









