






卷积神经网络
ConvNets用来处理有多个阵列形式的数据,例如彩色图象由三个二维阵列组成,包含三个颜色通道上的像素强度。许多数据形态都是多个阵列的形式:一维信号和序列,包括语言; 二维图像或音频频谱图;三维视频或立体图像。ConvNets有四个关键的想法,它利用了自然信号的性质:局部连接,共享权重,池和多层。
一个典型ConvNet(图2)架构被构造为一系列阶段。前几个阶段由两个类型的层组成:卷积层和池化层。卷积层的单元用特征图来组织,其中每个单元通过一组称为滤波器组的权值连接到前一层特征图的局部斑块上。然后这个局部加权和的结果非线性传递如ReLU。特征图中所有单元共享相同的滤波器组。同一层中不同的特征图使用不同的滤波器组。这样设计架构的理由是双重的。首先,在阵列数据中(如图像)局部
值通常是高度相关的,他们形成了鲜明地很容易被检测的局部图案。第二,图像和其他信号的局部统计信息对于位置而言是不变的。换句话说,如果一个图案可以出现在图像中,那么它可以出现在任何地方,因此,我们得出了这个想法,即不同位置的单元共享相同权重并且在阵列的不同位置检测出相同的图案。从数学方面讲,在特征图上执行的滤波操作就是离散卷积,它因此而得名。
虽然卷积层的作用是检测前一层特征的局部连接,但池化层的作用是合并语义上相似的特征。因为形成图案特征的相对位置可以有所不同,通过粗粒化每个特征的位置可以得到可靠的检测图案。一个典型的池化单元计算一个特征图(或几个特征图)中一个局部小块(patch)单元的最大值。移位小块(patch)多行或列得到的小块(patch)作为邻近池化单元的输入,从而降低了表示的维数并创建了小移位和变形的不变性(invariance to small shifts and distortions)。两层或三层的卷积,非线性和池化被堆叠起来,随后是卷积和全连接层。通过ConvNet的反向传播梯度与通过规则的深层网络一样简单,允许训练所有滤波器组的所有权值。
深层神经网络利用了许多自然信号是复合层次结构的属性,其中高层特征通过合成较低层特征得到。在图像中,边缘的局部组合形成图案(modifs),图案装配成部件(parts),部件形成对象(objects)。类似的层次结构也存在来自电话的声音,音素,音节,单词和句子的语音和文本。当前一层元素的位置和外观有变化时,池化允许表示有很小的变化。
ConvNets中卷积层和池化层的灵感来自于视觉神经中简单细胞和复杂细胞的经典概念,整体结构是视觉皮层腹侧通路中LGN-V1-V2-V4-IT层次的回忆(reminiscent)。当给ConvNet模型和猴子展示相同图像时,ConvNet中高层单元的激活说明了猴子颞下皮质160个神经元的一半方差。ConvNets来源于新认知机,其结构有些相似,但没有一个端至端的监督学习算法,如反向传播。原始的一维ConvNet称为延时神经网络,它用于音素和简单词汇的识别。
卷积网络的多种应用可以追溯到上世纪90年代初,最开始是用于识别语音和文档阅读的延时神经网络。文档阅读系统使用实现语言限制的概率模型来训练ConvNet。到20世纪90年代末该系统读取了美国超过10%的支票。一些基于ConvNet的光学字符识别和手写识别系统之后由微软开发。 在上世纪90年代初ConvNets也在自然图像的目标检测方面进行了实验,包括脸和手的检测以及人脸识别。
深层卷积网络理解的图像
自本世纪初,ConvNets已经非常成功地应用于图像中目标和区域的检测,分割以及识别。这些任务中标记的数据都相对比较丰富,如交通标志识别,生物图像特别是connectomics的分割以及自然图像中人脸,文字,行人的检测。最近ConvNets的一个主要成功实践是人脸识别。
重要的是,图像可以在像素级上标记,这将有技术上的应用,包括自动移动机器人和自动驾驶汽车。如Mobileye和NVIDIA公司都用在他们即将推出的汽车视觉系统中都使用了基于ConvNet的方法。其他越来越重要的应用涉及到自然语言理解和语音识别。
尽管取得了这些成就,ConvNets在很大程度上被主流计算机视觉和机器学习社区所抛弃,直到2012年ImageNet比赛。当深层卷积网络被应用到含有1000种不同类别的将近一百万张图片的数据集上时,他们取得了瞩目的结果,相对于最好竞争方法,它降低了一半的误差率。这一成功来自于GPU的的有效利用,ReLUs,一个新的正则化方法名为dropout,通过变形现有的训练样例产生更多的样例。这一成功给计算机视觉带来了一次革命;现在ConvNets几乎在所有的识别和检测任务上占据了主导地位,在一些任务上接近于人的表现。最近的一个惊人示范结合了ConvNets和递归网络来生成图像说明(图3)。
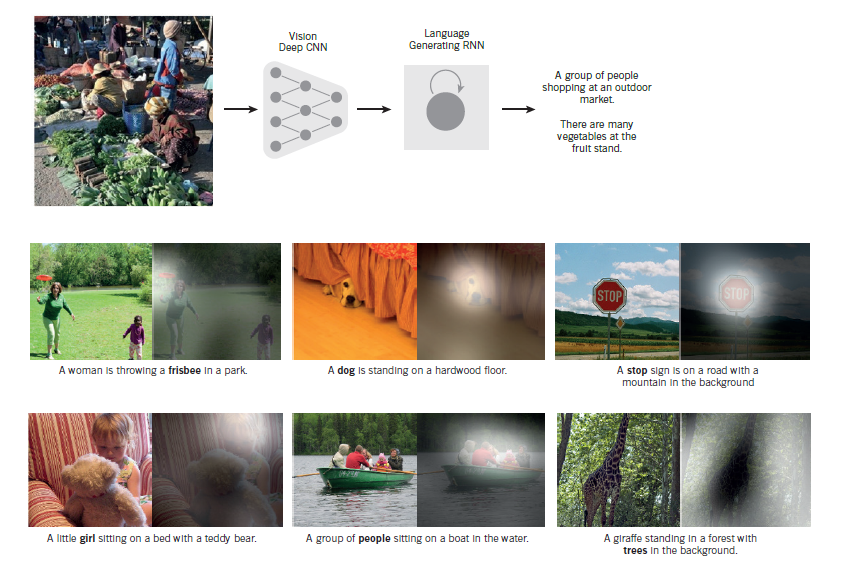
图3 |从图像到文字。由递归神经网络(RNN)生成的标题,通过卷积神经网络(CNN)从一幅测试图像中提取表示,RNN将图像的高层表示“翻译”成文字(顶部)。当RNN赋予了给出输入图像中不同位置(中间和底部;比较亮的区域被赋予了更大的关注)的聚焦能力时,如它产生的每个字(粗体),我们发现它能更好的将图像“翻译”成字幕。
最近ConvNet架构有10至20层的ReLUs,在单元之间有数以亿计的权重和数以千亿的连接。而训练这样的大型网络在两年前需要两周,随着硬件,软件和算法的并行进步,培训时间已经减少到几个小时。
基于ConvNet的视觉系统性能造就了大多数主要的科技公司,包括谷歌,Facebook,微软,IBM,雅虎,Twitter和Adobe,以及越来越多的initiate research,研发项目和部署基于ConvNet的图像理解产品和服务的创业企业。
ConvNets很容易服从于芯片或现场可编程门阵列上的高效硬件实现。许多公司如NVIDIA,Mobileye,英特尔,高通和三星都在开发ConvNet芯片来实现智能手机,照相机,机器人和自动驾驶汽车上的实时视觉应用。
分布式表示和语言处理
深度学习理论表明,深层网络对没有使用分布式表示的经典算法有两个不同的指数优势。这两种优势都出现于组合的幂,并依赖于基础的生成数据分布,该分布具有适当的成分结构。首先,在训练期间学习分布式表示可以对那些未见过特征值的组合产生泛化(例如,n个二进制特征可能有2^n种组合)。其次,组成深度网络的表示层对另一个指数优势(深度上的指数)带来了潜力。
多层神经网络的隐层用更容易预测网络目标输出的方式来表示网络的输入。用训练多层神经网络来预测一个序列中下一个词的实例可以很好的解释这一点。上下文中的每个词作为N维向量中的一个输入到网络,即一个成分为1而其余的为0。在第一层,每个词产生一个不同的激活图案或词向量(图4)。在一个语言模型中,网络的其他层将输入词向量转换成输出词向量来预测下一个词,它可用于预测下一个可能出现的任何单词的概率。该网络学习到的单词向量含有许多激活成分,每个激活成分可以解释为词的一个独立特征,学习符号的分布式表示也是这样。这些语义特征不能明确地表示输入,通过将输入和输出符号之间的结构关系分解成多个“微规则”的学习过程可以发掘出语义特征。当单词序列来自一个大型真正文本的语料库并且微规则不可靠时,学习单词向量效果也是非常好的。当用新的故事来训练产生下一个词时,例如,周二和周三的词向量非常相似,瑞典和挪威也是,这样的表示被称为分布式表示,因为它们的元素(特征)并不相互排斥,它们的许多配置对应于观测数据中看到的变化。这些词向量不是由专家提前确定的特征而是神经网络自动发现的特征组成的。也就是说,从文本中学到的向量表示现在被广泛地应用于自然语言应用。
表示的问题在于启发逻辑(logic-inspired)和启发神经网络(neural-network-inspired)之间的认知范式。在启发逻辑范式中,一个符号实例唯一的属性是与其他符号实例要么相同要么不同。它没有与它使用相关的内部结构;为了解释符号,它们必须用明智的推断选择规则将其绑定到变量上。相比之下,神经网络只用大的激活向量,权值大的矩阵和非线性标量来执行快速“直观”推论,该推论支持容易的常识推理。
在引入神经语言模型之前,语言统计建模的标准方法没有开发出分布表示:它是基于长度为N(称为N-gram)的短符号序列中发生的频率。N-gram可能的数目大约是VN,其中V是词汇大小,所以对少量的词汇计数需要非常大的训练语料库。N-gram把每个词看做一个原子单元,因此它们不能对语义相关的序列进行概括,而神经语言模型可以,因为他们将每个词与实际值特征向量关联起来,在向量空间中语义上相关的词最终靠在一起(图4)。
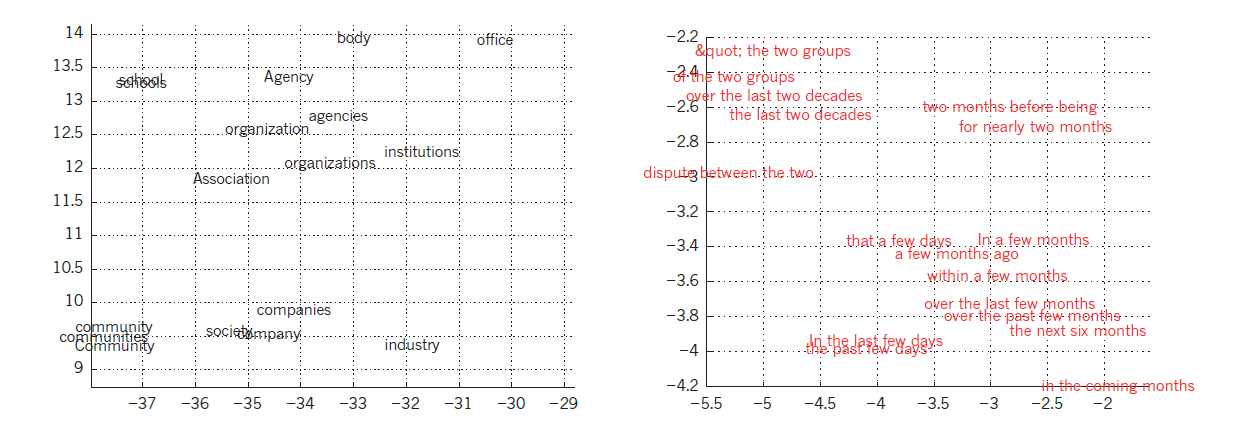
图4|可视化学到的词向量。左边是从建模语言中学到的词表示,为了可视化使用t-SNE算法非线性的映射到2D。右边是一个2D短语表示,该短语从英语到法语的编码器-解码器递归神经网络中学习到。可以看到语义相似的词或单词序列映射到邻近的表示。词的分布式表示通过使用反向传播到共同学习每个字和特征表示获得,其中特征预测目标数量如一个序列的下个单词(语言模型)或整个序列的翻译(机器翻译)。
递归神经网络
当反向传播被第一次进入时,其最令人兴奋的使用是训练递归神经网络(RNNs)。对于涉及连续输入的任务,如语音和语言,使用RNNs(图5)效果是比较好的。 RNNs对于输入的序列一次处理一个元素,在他们的隐层保留一个’状态向量’,它含蓄地包含所有过去元素的历史信息。当我们考虑不同离散时间步骤上的隐层输出时(犹如他们是深度多层网络(图5,右)里不同神经元的输出),我们如何运用反向传播来训练RNNs就会变得非常清晰。
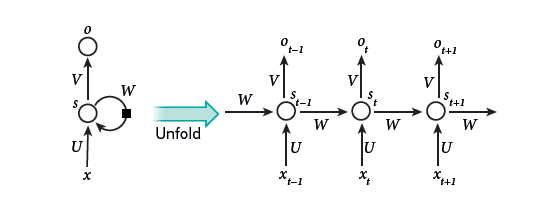
图5 |递归神经网络和参与前向计算的及时展开。人工神经元(例如,聚集在s下面的隐元,且时间为t是节点s的值为st)从其它神经元的先前时间步(如左侧,用黑色正方形表示,代表一个时间步的延迟)得到。以这种方式,递归神经网络可以映射输入序列(元素为xt)到一个输出系列(元素为ot),每个ot依赖于先前的xt’(t’≤t)。相同的参数(矩阵U,V,W)用于每个时间步。许多其他结构是可能的,考虑一个变形,其中,网络可以产生输出序列(例如,词),每个都被用作下一时间步的输入。在BP算法(图1)中可直接应用右侧展开网络的计算图,来计算总误差对于所有状态st和参数的导数(例如,产生右侧输出序列的对数概率)。
RNNs是非常强大的动态系统,但是训练他们确是有问题的,因为反向传播的梯度在每一步也可能增长也可能收缩,所以很多时候,他们通常激增或消失。
由于架构和训练方式的进步,RNNs在预测文本下一个字符或序列中下一个词时效果非常好,但它们也可用于更复杂的任务。例如,在一个词一个词的读完一个英文句子后,可以训练一个英语’编码’网络,使得其隐层的最终状态向量是真个句子所表达思想的表示。这种思想向量(thought vector)可以用来作为(或作为额外输入)法语“解码器”网络的初始隐状态,该网络输出法语翻译的第一个词的概率分布。如果特定的第一个词从这个分布中选到并作为解码器网络的输入,然后它将输出第二个词翻译的概率分布,一直这样直到结束。总体而言,根据英语句子的概率分布,这个过程产生了一个法语词的系列。这个相当朴素的机器翻译方式已经迅速成为国家最先进的竞争力对手,这引起了人们严重怀疑,理解一个句子是否需要像内部符号表达之类的东西,其中表达式通过推理规则控制。它与日常推理涉及许多同时类比(这些类比有助于作出结论)的观点是兼容的。
相反,翻译法国成英语,可以学习“翻译”图像的意思成英语(图3)。这里的编码器是一个深层的ConvNet,它将像素转换成最后隐层的激活向量。解码器是一个RNN类似于机器翻译和神经语言模型。最近一些人对这样的系统产生了兴趣。
RNNs(图5),可以看作是非常深层的前馈网络,其中所有层共享相同的权重。虽然它们的主要目的是学习长期依赖,理论和经验证据表明,长时间学习存储信息是困难的。
为了校正这一点,人们的想法是用一个外显存储来增大网络。这种类型的第一个建议是长短期存储(long short-term memory,LSTM)网络,该网络使用特殊的隐层,其自然行为是长时间记录输入。一个称为存储单元(cell)的特殊单元像一个蓄电池或门控漏水神经元(gated leaky neuron):在下一时间步骤它连接到自身,所以它复制自身的实值状态并积聚外部信号,但这种自连接和另一单元是封闭的(this self-connecton is multiplicatively gated by another unit,是在不懂,求指教),其学习决定何时清除内存的内容。
LSTM网络随后被证明比常规RNNs更有效,尤其是当它们在每个时间步骤上有几层的时候,使整个语音识别系统成为可能,该系统从声学到字符序列转录完全一致。LSTM网络或相关形式的门控单元目前也用于编码器和解码器网络,该网络在机器翻译中执行效果非常好。
在过去的一年中,几位学者提出了不同的建议来加强有内存模块的RNNs。这些建议包括神经图灵机(在该机器中,网络由一个“带状”(tap-like)内存来增强,RNN可以选择往该内存里读或者写),存储网络(在该网络中,网络由一种联合的内存来增强)。存储网络在标准答疑基准(standard question-answering benchmarks)上取得了很好的性能。该存储用于记录网络回答问题的内容。
除了简单的记忆,神经图灵机和存储网络正被用于通常需要推理和符号操纵的任务。神经图灵机可以教“算法”。在其他事项中,当他们的输入包括一个未排序的序列(其中每个符号伴随着一个真实值,该真实值表示在列表中的优先级)时,他们可以学习输出符号的排序列表。存储网络可以在类似于文本冒险游戏的环境中跟踪世界的状态,读完一个故事后,他们可以回答需要复杂推论才能得出的问题。在一个测试实例中,给网络展示指环王的15句版本(15-sentence version,不知道表达的什么意思,qu求指教),它能正确地回答诸如“Frodo现在在哪里?”的问题。
深度学习的未来
无监督学习对复兴深度学习起到了催化的作用,但已经被纯粹监督学习的成功遮盖。尽管在这个回顾中我们没有专注于它,但我们预计从长远来看,无监督学习会变得更为重要。人类和动物学习主要是无监督的:我们通过观察世界来发现世界的结构,而不是被告知每个对象的名字。
人的视觉是活动进程,它用一个智能的,特定任务的方式来顺序采样光学阵列。人的视网膜由中间小但高分辨率的凹带及周围环绕的大但低分辨率的部分组成。我们预计未来视觉发展将来自这个系统,它进行端到端的训练并结合带有RNNs的ConvNets(使用强化学习决定看哪里)。结合深度学习和强化学习的系统还处于起步阶段,但是他们已经胜过分类任务中的被动视觉系统,并在学习玩不同的视频游戏中产生了令人印象深刻的结果。
在未来几年,深度学习有望产生很大影响的另一个领域是自然语言理解。我们预计使用RNNs来理解句子或整个文件的系统如果在一个时间内选择专注一部分时,效果会更好。
最终,实现了结合学习表示与复杂推理的系统后,人工智能方面会产生重大的进展。虽然深度学习和简单推理已经用于语音和手写识别很长一段时间了,但新的范式需要大型向量上的运算取代基于规则的符号表达式操作。















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









