






对Alpha-zero很感兴趣,所以耐心阅读了mastering the game of go without human knowledge
Deepmind 官网的介绍:AlphaGo Zero: Learning from scratch
在阅读的过程中,对蒙特卡洛树搜索算法不甚了解,下面翻译了youtube上一位英国教授的网络课程视频。
蒙特卡洛树搜索(MCTS)算法
MCTS算法是一种决策算法,每次模拟(simulation)分为4步:
1. Tree traversal:
UCB1(Si)=Vi¯¯¯+clogNni−−−−√,c=2
其中,
Vi¯¯¯
表示
Si
状态的平均value(下面会进一步解释)
2. Node expansion
3. Rollout (random simulation)
4. Backpropagation
步骤1,2的流程图如下:
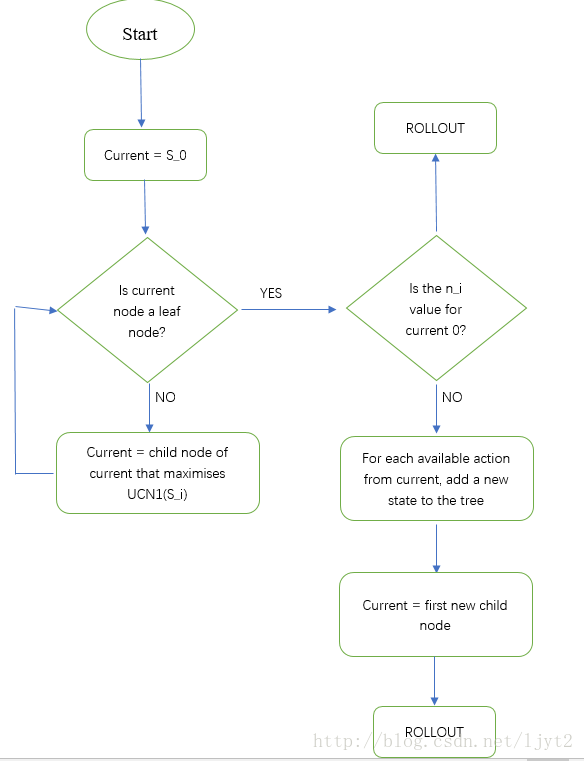
步骤3 Rollout 的细节:
- 1
- 2
- 3
- 4
- 5
- 6
讲一个具体的例子:
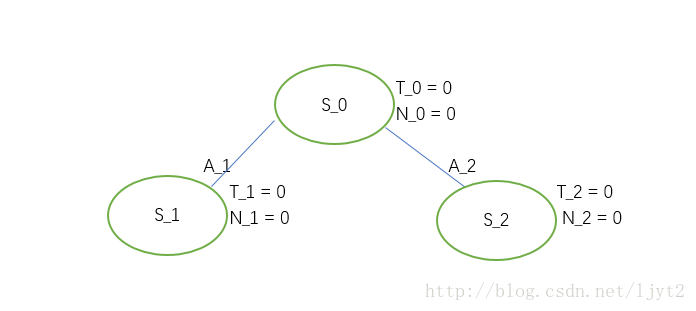
- 树的初始状态:
T 表示总的 value, N 表示被访问的次数(visit count)。A表示动作(action).
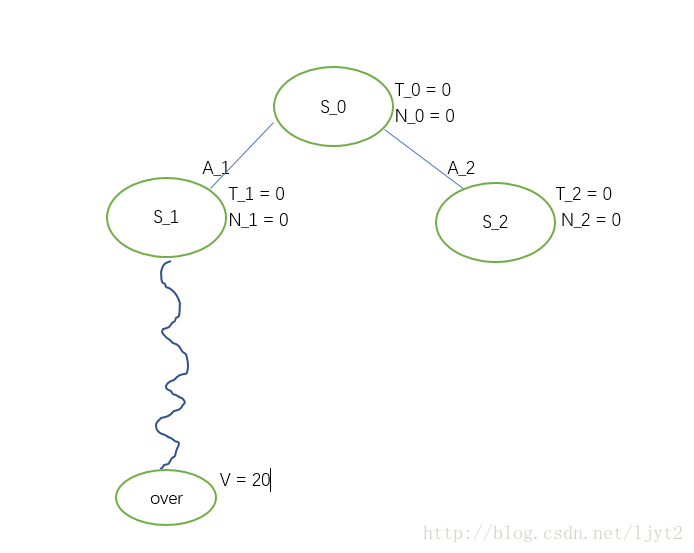
第一次迭代(iteration):
从状态 S0 开始,要在下面两个动作中进行选择(假设只有两个动作可选),选择的标准就是 UCB1(Si) 值。显然可算得:
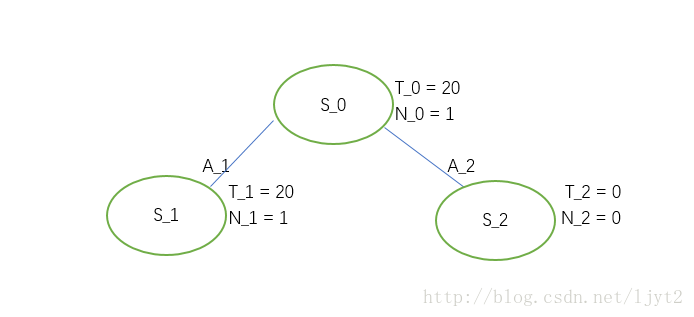
这种情况下,我们就按顺序取第一个,即 A1 。从而,达到状态 S1 。
按照步骤1,2的流程图,我们现在需要判断目前的结点 S1 (current node)是不是叶节点,这里叶节点是指其没有被展开(expansion)过。显然,此结点没有被展开过,所以是叶节点。接下来,按照流程图,需要判断结点 S1 被访问的系数是否为0。是0,所以要进行Rollout。
Rollout其实就是在接下来的步骤中每一步都随机采取动作,直到停止点(围棋中的对局结束),得到一个最终的value。
假设Rollout最终值为20.
接下来,进行步骤4 Backpropagation,即利用Rollout最终得到的value来更新路径上每个结点的T,N值。
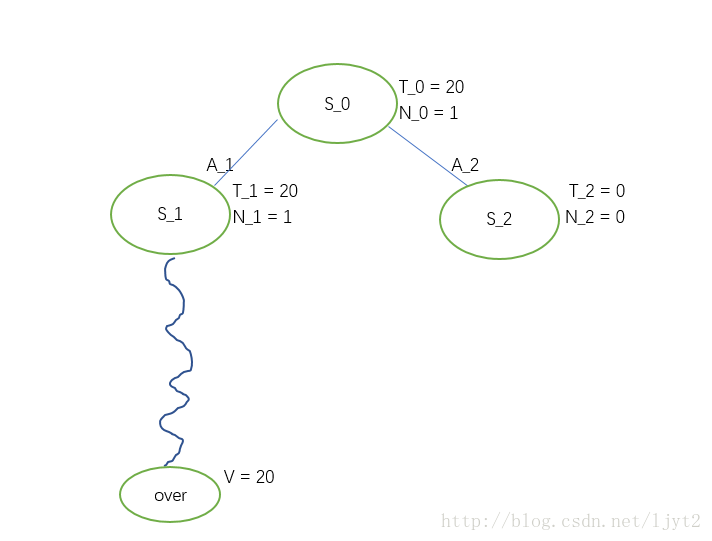
之后把Rollout的结果删除:
MCTS的想法就是要从 S0 出发不断的进行迭代,不断更新结点值,直到达到一定的迭代次数或者时间。
第二次迭代:
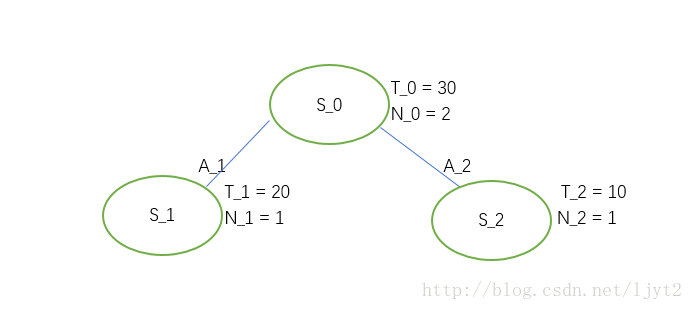
我们从 S0 出发进行第二次迭代(iteration):
首先,计算下面两个结点
S1,S2
的
UCB1
值:
所以,选动作 A2 ,从而达到状态 S2 。
同上,现在要判断结点 S2 是否是叶结点。是,所以继续判断其被访问的次数。是0,所以进入Rollout, 假设Rollout最终值为10.
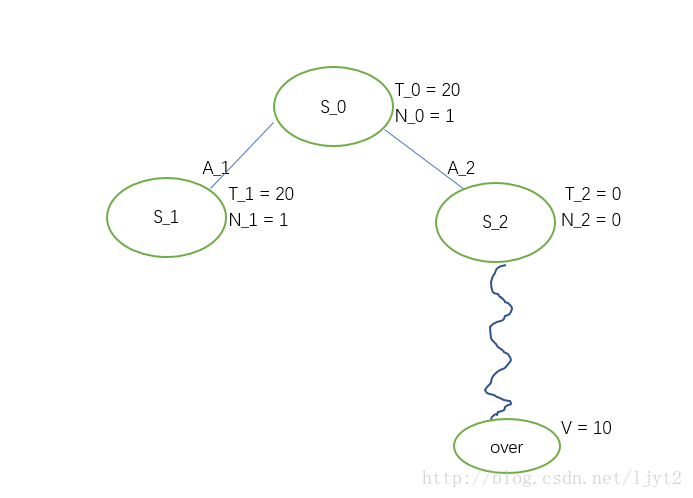
之后进行Backpropogation:
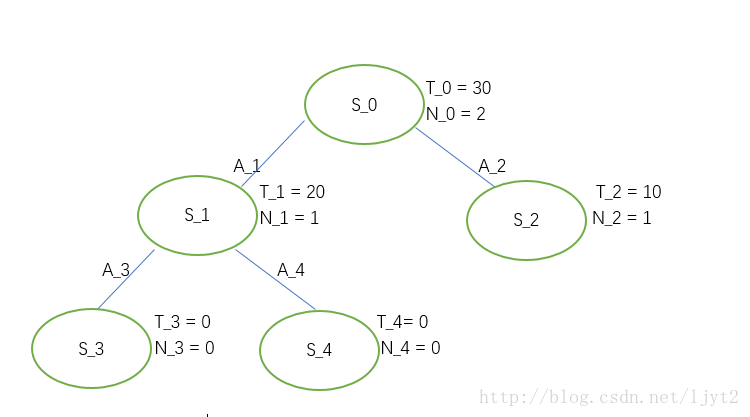
第三次迭代:
首先,计算UCB1值:
执行动作
A1
,进入状态
S1
。
是否是叶节点? 是。
被访问次数是否为0?否。
按照流程图所示,现在进入Node expansion步骤。同样假设只有两个动作可选。
选择 S3 进行 Rollout,假设Rollout最终值为0.
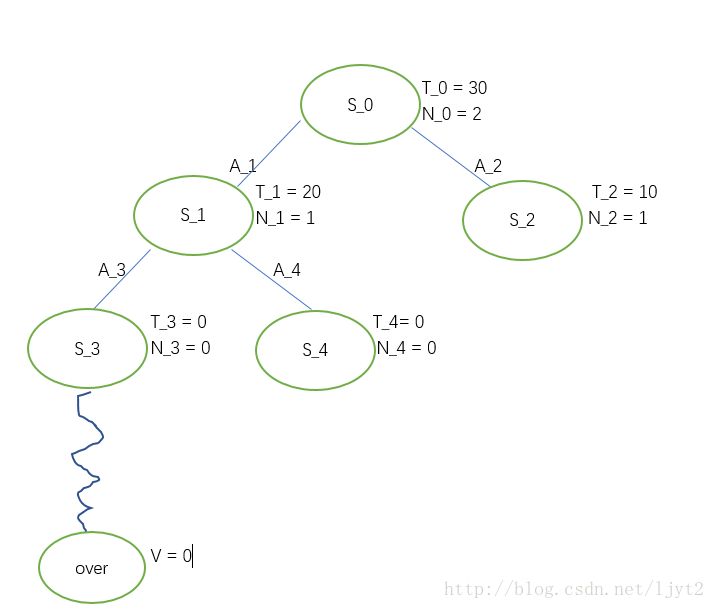
更新路径上每个结点的值,之后删除Rollout的值:
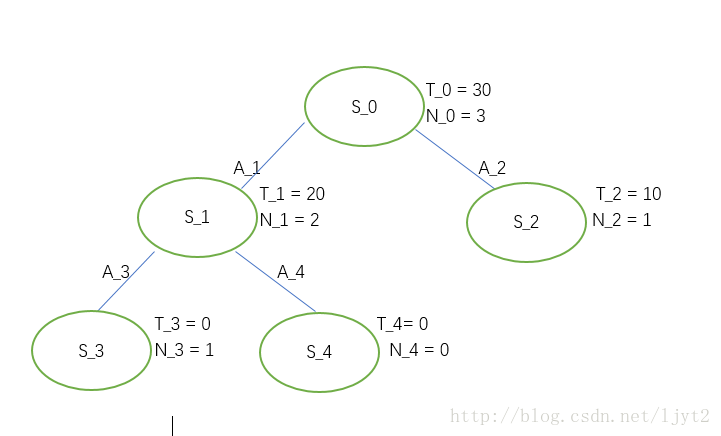
第四次迭代:
首先,计算UCB1值:
选择 A2 ,进入状态 S2 , 接下来和第三次迭代一样的步骤:
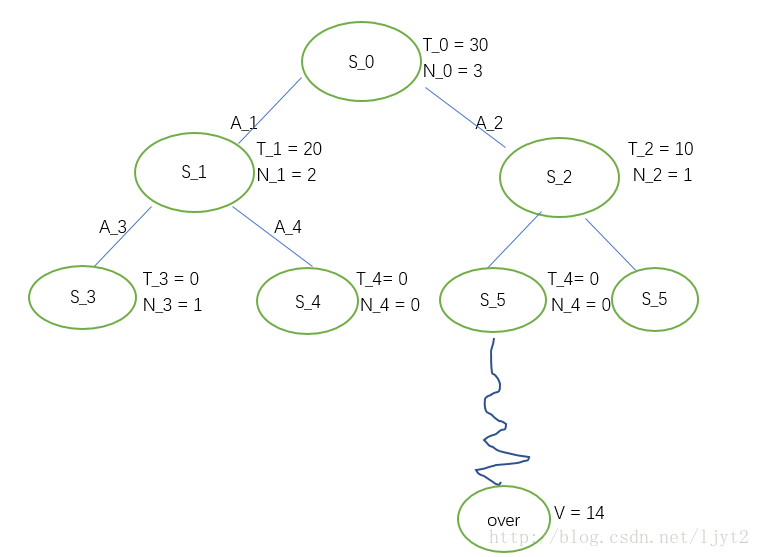
更新路径上的结点:
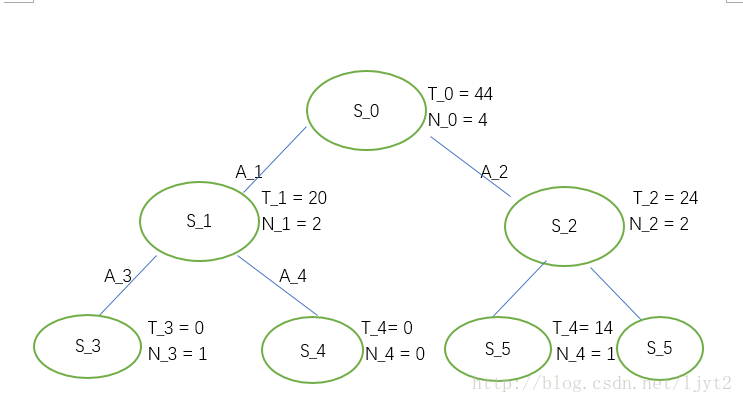
假设我们设定最大迭代次数为4,则我们的迭代完毕。这时,利用得到的树来决定在 S0 处应该选择哪个动作。根据UCB1值,显然我们要选择动作 A2 .
以上就是MCTS的过程,是翻译自youtube.。
以上内容如有错误,皆由博主负责,与youtube上教授无关。
以上是最简单的蒙特卡洛树,关于alpha的改进主要有几点。
1、在expand的时候使用概率进行选择
2、得到value的值的时候,使用两个神经网络分别得到,都是人类的知识。
3、为了并行计算,将选择过的路径值+3.进行锁住















 4592
4592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









