







logistic回归的主要思想是根据现有的数据对分类边界线建立回归公式,以此进行分类。主要在流行病学中应用较多,比较常用的情形是探索某疾病的危险因素,根据危险因素预测某疾病发生的概率等等。logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,所以实际中最为常用的就是二分类的logistic回归。
今天我们就二分类进行分析,我们在回归分析中需要一个函数可以接受所有的输入然后预测出类别,假定用0和1分别表示两个类别,logistic函数曲线很像S型,故此我们可以联系sigmoid函数:σ = 1/(1/(1+e-z))。为了实现logistic回归分类器,我们可以在每个特征上乘以一个回归系数,将所有的乘积相加,将和值代入sigmoid函数中,得到一个范围为0-1之间的数,如果该数值大于0.5则被归入1类,否则被归为0类。
基于之前的分析,需要找到回归系数,首先我们可以将sigmoid函数的输入形式记为:z = w0x0 + w1x1 +...+wnxn,其中x为输入数据,相应的w就是我们要求的系数,为了求得最佳系数,结合最优化理论,我们可以选取梯度上升法优化算法。梯度上升法的基本思想是:要找到函数的最大值,最好的方法是沿着该函数的梯度方向寻找。
Cost函数
Andrew Ng在课程中直接给出了Cost函数及J(θ)函数如式(5)和(6),但是并没有给出具体的解释,只是说明了这个函数来衡量h函数预测的好坏是合理的。
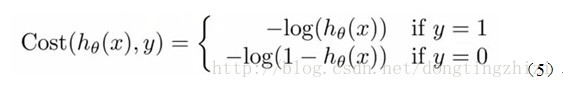
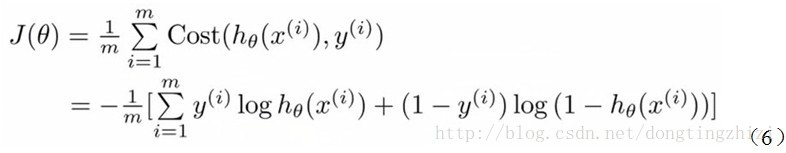
实际上这里的Cost函数和J(θ)函数是基于最大似然估计推导得到的。下面详细说明推导的过程。(4)式综合起来可以写成:
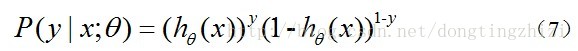
取似然函数为:
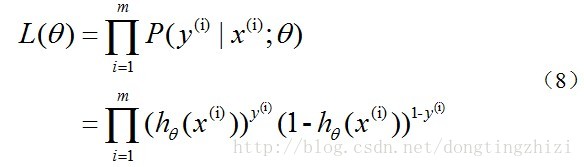
对数似然函数为:
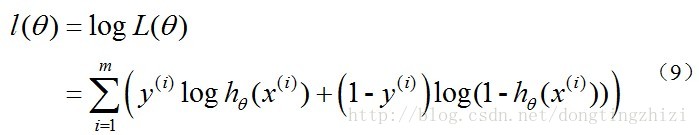
最大似然估计就是要求得使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。但是,在Andrew Ng的课程中将J(θ)取为(6)式,即:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4234
4234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









