










xgboost 分布式部署教程
xgboost是一个非常优秀的用于梯度提升学习开源工具。在多个数值算法和非数值算法的优化下(XGBoost: A Scalable Tree Boosting System),速度非常惊人。经测试用spark10小时才能train出GBDT(Gradient Boosting Decision Tree)的数据量,xgboost 使用一半的集群资源只需要10分钟。出于种种原因,我在hadoop环境上部署xgboost花了一个多月的时间,期间在xgboost issues 上提了很多问题,也替作者找过bug。今天特地写篇部署教程,方便有需要的同行。
注:
- 本教程是在集群
gcc -v< 4.8 libhdfs native目标代码不可用的情况下部署xgboost,因此可以cover掉部署过程中遇到的绝大多数问题。 - 由于未对当前的代码进行测试,本教程使用特定版本的代码。
- 本教程将运行xgboost依赖的文件都放到
xgboost-packages目录下,再次部署只需scp -r xgboost-packages到${HOME}目录下
获取特定版本的xgboost
- 从github上
git clonedmlc-core, rabit, xgboost
git clone --recursive https://github.com/dmlc/xgboost - 进入
xgboost目录,检出版本76c320e9f0db7cf4aed73593ddcb4e0be0673810
git checkout 76c320e9f0db7cf4aed73593ddcb4e0be0673810 - 进入
dmlc-core目录,检出版本706f4d477a48fc75cb46b226ea007fbac862f9c2
git checkout 706f4d477a48fc75cb46b226ea007fbac862f9c2 - 进入
rabit目录,检出版本112d866dc92354304c0891500374fe40cdf13a50
git checkout 112d866dc92354304c0891500374fe40cdf13a50 - 在
${HOME}创建xgboost-packages目录,将xgboost拷贝到xgboost-package目录下
mkdir xgboost-package
cp -r xgboost xgboost-packages/安装编译依赖的包
安装gcc-4.8.0
- 下载gcc源码包并解压
tar -jxvf gcc-4.8.2.tar.bz2 - 下载编译所需依赖库
cd gcc-4.8.2
./contrib/download_prerequisites
# 建立一个目录供编译出的文件存放
cd ..- 建立编译输出目录
mkdir gcc-build-4.8.2 - 进入此目录,执行以下命令,生成makefile文件(安装到${HOME}目录下)
cd gcc-build-4.8.2
../gcc-4.8.2/configure --enable-checking=release --enable-languages=c,c++ --disable-multilib --prefix=${HOME}- 编译
make -j21 - 安装
make install - 修改变量切换默认gcc版本
PATH=$HOME/bin:$PATH
cp -r ~/lib64 ~/xgboost-packages安装cmake
- 下载cmake-3.5.2
- 安装:
tar -zxf cmake-3.5.2.tar.gz
cd cmake-3.5.2
./bootstrap --prefix=${HOME}
gmake
make -j21
make install下载编译libhdfs*
unzip hadoop-common-cdh5-2.6.0_5.5.0.zip
cd hadoop-common-cdh5-2.6.0_5.5.0/hadoop-hdfs-project/hadoop-hdfs/src
cmake -DGENERATED_JAVAH=/opt/jdk1.8.0_60 -DJAVA_HOME=/opt/jdk1.8.0_60
make
# 拷贝编译好的目标文件到xgboost-packages中
cp -r /target/usr/local/lib ${HOME}/xgboost-packages/libhdfs安装xgboost
- 编译
cd ${HOME}/xgboost-packages/xgboost
cp make/config.mk ./
# 更改config.mk 使用HDFS配置
# whether use HDFS support during compile
USE_HDFS = 1
HADOOP_HOME = /usr/lib/hadoop
HDFS_LIB_PATH = $(HOME)/xgboost-packages/libhdfs
#编译
make -j22- 修改部分代码(env python 版本>2.7不用修改)
# 更改dmlc_yarn.py首行
#!/usr/bin/python2.7
# 更改run_hdfs_prog.py首行
#!/usr/bin/python2.7- 测试
# 添加必要参数
cd ${HOME}/xgboost-packages/xgboost/demo/distributed-training
echo -e "booster = gbtree\nobjective = binary:logistic\nsave_period = 0\neval_train = 1" > mushroom.hadoop.conf
# 测试代码 run_yarn.sh
#!/bin/bash
if [ "$#" -lt 2 ];
then
echo "Usage: <nworkers> <nthreads>"
exit -1
fi
# put the local training file to HDFS
DATA_DIR="/user/`whoami`/xgboost-dist-test"
#hadoop fs -test -d ${DATA_DIR} && hadoop fs -rm -r ${DATA_DIR}
#hadoop fs -mkdir ${DATA_DIR}
#hadoop fs -put ../data/agaricus.txt.train ${DATA_DIR}
#hadoop fs -put ../data/agaricus.txt.test ${DATA_DIR}
# necessary env
export LD_LIBRARY_PATH=${HOME}/xgboost-packages/lib64:$JAVA_HOME/jre/lib/amd64/server:/${HOME}/xgboost-packages/libhdfs:$LD_LIBRARY_PATH
export HADOOP_HOME=/usr/lib/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=/usr/lib/hadoop-hdfs
export HADOOP_MAPRED_HOME=/usr/lib/hadoop-yarn
export HADOOP_YARN_HOME=$HADOOP_MAPRED_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# running rabit, pass address in hdfs
../../dmlc-core/tracker/dmlc_yarn.py -n $1 --vcores $2\
--ship-libcxx ${HOME}/xgboost-packages/lib64 \
-q root.machinelearning \
-f ${HOME}/xgboost-packages/libhdfs/libhdfs.so.0.0.0 \
../../xgboost mushroom.hadoop.conf nthread=$2 \
data=hdfs://ss-hadoop${DATA_DIR}/agaricus.txt.train \
eval[test]=hdfs://ss-hadoop${DATA_DIR}/agaricus.txt.test \
eta=1.0 \
max_depth=3 \
num_round=3 \
model_out=hdfs://ss-hadoop/tmp/mushroom.final.model
# get the final model file
hadoop fs -get /tmp/mushroom.final.model final.model
# use dmlc-core/yarn/run_hdfs_prog.py to setup approperiate env
# output prediction task=pred
#../../xgboost.dmlc mushroom.hadoop.conf task=pred model_in=final.model test:data=../data/agaricus.txt.test
#../../dmlc-core/yarn/run_hdfs_prog.py ../../xgboost mushroom.hadoop.conf task=pred model_in=final.model test:data=../data/agaricus.txt.test
# print the boosters of final.model in dump.raw.txt
#../../xgboost.dmlc mushroom.hadoop.conf task=dump model_in=final.model name_dump=dump.raw.txt
#../../dmlc-core/yarn/run_hdfs_prog.py ../../xgboost mushroom.hadoop.conf task=dump model_in=final.model name_dump=dump.raw.txt
# use the feature map in printing for better visualization
#../../xgboost.dmlc mushroom.hadoop.conf task=dump model_in=final.model fmap=../data/featmap.txt name_dump=dump.nice.txt
../../dmlc-core/yarn/run_hdfs_prog.py ../../xgboost mushroom.hadoop.conf task=dump model_in=final.model fmap=../data/featmap.txt name_dump=dump.nice.txt
cat dump.nice.txt- 运行结果
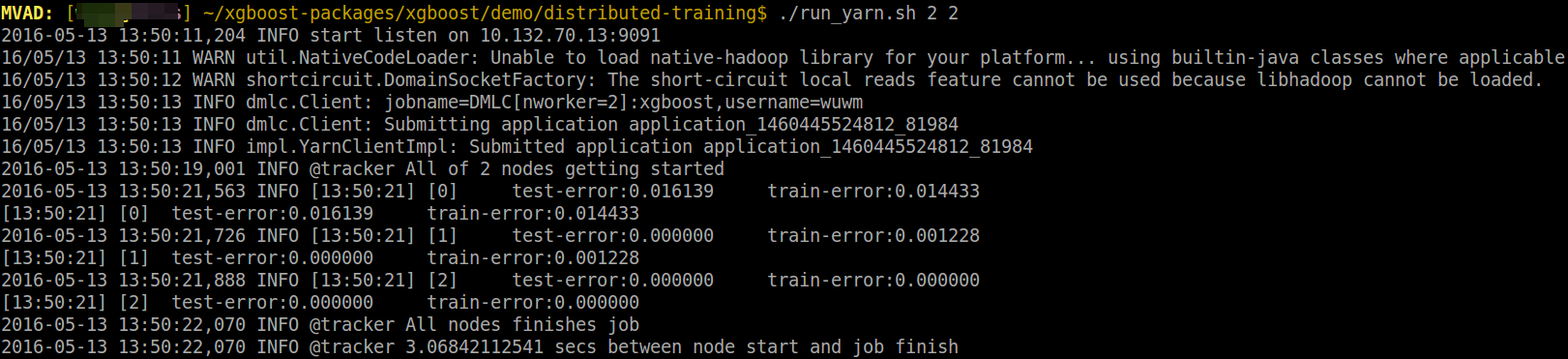
参考资料
- https://github.com/dmlc/xgboost
- https://github.com/dmlc/xgboost/issues/854
- https://github.com/dmlc/xgboost/issues/856
- https://github.com/dmlc/xgboost/issues/861
- https://github.com/dmlc/xgboost/issues/866
- https://github.com/dmlc/xgboost/issues/869
- https://github.com/dmlc/xgboost/issues/1150
- http://arxiv.org/pdf/1603.02754v1.pdf















 3708
3708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









