







今天 发现了Python 中有一个可以给tuple 一个名字的一个方法,叫namedtuple
from collections import namedtuple
# encoding: utf-8
from collections import namedtuple
person =('name','age','sex','mail')
Person = namedtuple('Person',person,verbose=True)
p = Person('changyubiao',18,"male",'931367095@qq.com')
print type(p)
print p.name ,p.age,p.sex,p.mail发现是可以 打印出结果的
<class '__main__.Person'>
changyubiao 18 male 931367095@qq.com
觉得这不错, 可以属性名,来访问元祖而不用小标,这样还是比较好,如果特别的属性,就可以通过这种方式。后来看一下,它的官方文档。
namedtuple() factory function for creating tuple subclasses with named fields ,就是 返回一个子类tuple 用给出 那些字段 ,name ,age ,sex ,mail 等。
collections.namedtuple(typename, field_names[, verbose=False][, rename=False])
Returns a new tuple subclass named typename. The new subclass is used to create tuple-like objects that have fields accessible by attribute lookup as well as being indexable and iterable. Instances of the subclass also have a helpful docstring (with typename and field_names) and a helpful __repr__() method which lists the tuple contents in a name=value format.
The field_names are a sequence of strings such as ['x', 'y']. Alternatively, field_names can be a single string with each fieldname separated by whitespace and/or commas, for example 'x y' or 'x, y'.
Any valid Python identifier may be used for a fieldname except for names starting with an underscore. Valid identifiers consist of letters, digits, and underscores but do not start with a digit or underscore and cannot be a keyword such as class, for, return, global, pass, print, or raise.
If rename is true, invalid fieldnames are automatically replaced with positional names. For example, ['abc', 'def', 'ghi', 'abc'] is converted to ['abc', '_1', 'ghi', '_3'], eliminating the keyword def and the duplicate fieldname abc.
If verbose is true, the class definition is printed just before being built.
Named tuple instances do not have per-instance dictionaries, so they are lightweight and require no more memory than regular tuples.
'''
返回一个名为typename的新的元组子类。新的子类用于创建具有可通过属性查找访问的字段的元组对象,以及可索引和可迭代的对象。子类的实例也有一个有用的docstring(带有typename和field_names)和一个有用的__repr __()方法,它以一个name = value格式列出元组内容。
field_names是一串字符串,如['x','y']。或者,field_names可以是单个字符串,每个字段名用空格和/或逗号分隔,例如'x y'或'x,y'。
除了以下划线开头的名称以外,任何有效的Python标识符都可以用于字段名。有效的标识符由字母,数字和下划线组成,但不以数字或下划线开头,不能是关键字,例如class,for,return,global,pass,print或raise。
如果重命名为true,则无效的字段名会自动替换为位置名称。例如,['abc','def','ghi','abc']被转换为['abc','_1','ghi','_3'],消除了关键字def和重复的字段名abc 。
如果verbose为true,则在构建之前打印类定义。
命名的元组实例没有每个实例的字典,所以它们是轻量级的,不需要比常规元组更多的内存。person =('name','age','sex','mail')
Person = namedtuple('Person',person)
对于第二句话,为什么 要有一个‘Person’ 呢? 这个 有什么用呢,之后 我看了实现。 其实官方文档 也说了, namedtuple() 会根据这个typename , 创建一个子类 类名 就是typename , 返回出去,之后赋值给Person ,后面 字段就是属性了,会根据这个这个元祖来生成 类的属性。当然 这些属性必须要满足变量名称的定义规则,不能是关键字,不能以数字开头,等等。否则 会报错的。 有这个参数 verbose=True 就可以看到类的生成过程。让我们来一起看下。
person =('name','age','sex','mail')
Person = namedtuple('Person',person,verbose=True)
class Person(tuple):
'Person(name, age, sex, mail)'
__slots__ = ()
_fields = ('name', 'age', 'sex', 'mail')
def __new__(_cls, name, age, sex, mail):
'Create new instance of Person(name, age, sex, mail)'
return _tuple.__new__(_cls, (name, age, sex, mail))
@classmethod
def _make(cls, iterable, new=tuple.__new__, len=len):
'Make a new Person object from a sequence or iterable'
result = new(cls, iterable)
if len(result) != 4:
raise TypeError('Expected 4 arguments, got %d' % len(result))
return result
def __repr__(self):
'Return a nicely formatted representation string'
return 'Person(name=%r, age=%r, sex=%r, mail=%r)' % self
def _asdict(self):
'Return a new OrderedDict which maps field names to their values'
return OrderedDict(zip(self._fields, self))
def _replace(_self, **kwds):
'Return a new Person object replacing specified fields with new values'
result = _self._make(map(kwds.pop, ('name', 'age', 'sex', 'mail'), _self))
if kwds:
raise ValueError('Got unexpected field names: %r' % kwds.keys())
return result
def __getnewargs__(self):
'Return self as a plain tuple. Used by copy and pickle.'
return tuple(self)
__dict__ = _property(_asdict)
def __getstate__(self):
'Exclude the OrderedDict from pickling'
pass
name = _property(_itemgetter(0), doc='Alias for field number 0')
age = _property(_itemgetter(1), doc='Alias for field number 1')
sex = _property(_itemgetter(2), doc='Alias for field number 2')
mail = _property(_itemgetter(3), doc='Alias for field number 3')从这里可以看出整个类的构造过程, 也会对namedtuple 有更好的理解。 其实namedtuple 并没有破坏用下标访问
# encoding: utf-8
from collections import namedtuple
person =('name','age','sex','mail')
Person = namedtuple('Person',person,verbose=False)
p = Person('changyubiao',18,"male",'931367095@qq.com')
print p.name ,p.age,p.mail,p.sex
for i in range(0,4):
print p[i]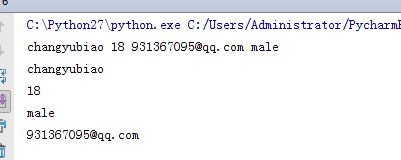
没有任何问题, 还是 可以正常访问的。
还有一个 namedtuple 一个参数 rename 这个就是 如果的 属性 设置不能作为变量名 , 会直接报错。 如果用rename=True, Python 会自动重新帮你命名,来符合变量的命名规范。来看一个例子
我把Person 的属性 mail 改成了 5mail 肯定不符合规范, Python 构建 子类的时候, 就会报错。
person =('name','age','sex','5mail')
Person = namedtuple('Person',person,verbose=True,)
p = Person('changyubiao',18,"male",'931367095@qq.com')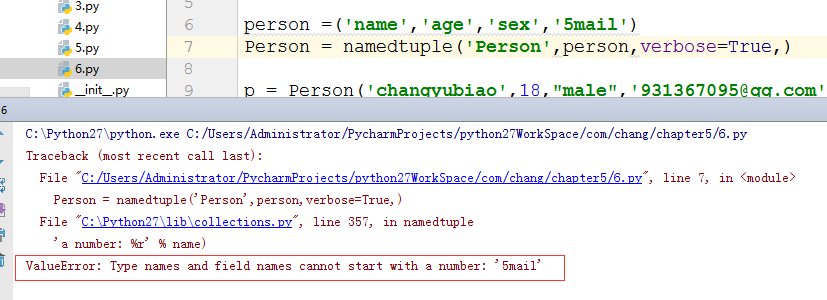
如果 构造namedtuple 的时候 ,加上 rename=True, 来看下结果
person =('name','age','sex','5mail')
Person = namedtuple('Person',person,verbose=True,rename=True)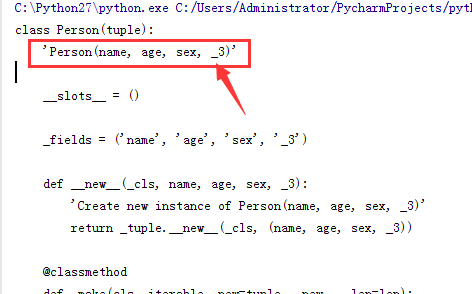
这里明显可以看出 第四个字段,变成了 _3 名称,python 自己重新的命名。
访问下 属性
print p.name ,p.age,p._3,p.sex
for i in range(0,4):
print (p[i])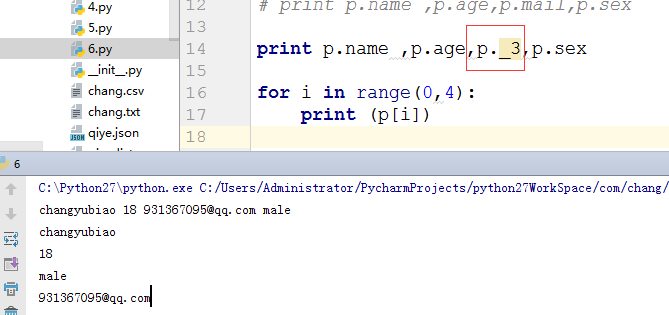
成功的 访问到了邮箱了,这就是rename 的作用。
总结: 对于这种namedtuple 有什么好处,显而易见 就是方便 访问,不需要记住下标,可以访问元素,元祖 的元素比较多的时候,用这个还是不错的。
但是 问题来了, 为什么不用字典呢? 和namedtuple 有什么区别呢?
以下是我的这个拙见:
namedtuple 是只读的,第一 不能修改元祖,它还是元祖,第二 它是有序的。第三, 查找速度man, 它的优点呢? 占用内存小(和字典相比)
字典的特点 , 第一 ,value 的值是可以更改的,第二 ,查找速度快, 第三 字典 占用内存是比较大的。第四 ,字典是无序的, 这点和tuple 是完全不一样的。
分享快乐,留住感动。 Mon Nov 06 16:25:57 2017 ---biaoge















 3264
3264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









