







Paper Reading Note
URL: https://arxiv.org/pdf/1912.10664.pdf
TL;DR
论文提出了一个新的benchmark, TinyPerson, 其中包含了很多小的人体目标,另外,作者通过实验发现,在检测任务中,pre-training和detector训练数据之间的mismatch会导致检测器性能下降,因此提出了一种Scale Match手段来align两部分的数据集以提升检测器性能
Dataset/Algorithm/Model/Experiment Detail
首先是TinyPerson的介绍,主要针对的是小目标的人体检测,作者称这是第一个远距离且含有大量背景的人体检测benchmark,如图1上半部分和图2所示,该数据集中的人体非常小,也显示出对于小目标人体检测的困难。如图1下半部分所示,与其他benchmark相比,TinyPerson中的小尺度人体分布比例明显更高



如表1所示,TinyPerson中的aspect ratio具有较高的方差,这个检测任务带来了更多挑战。另外,作者还提到TinyPerson中含有较多密集的case(200个目标以上)

目前检测任务中,通常会使用额外的数据预训练模型,然后再使用针对某一任务的数据集进行fine-tune,这样做能够对模型效果有一定提升。然而,当这些额外数据的domain与实际任务的domain相差较大时(比如两者的scale差距较大),提升效果就比较有限了。
为了解决该问题,作者提出一种方法,来保持额外的数据与task-specific的训练数据(TinyPerson)的一致性,通过一个变换
T
T
T ,使得两个数据集目标大小的分布变得一致,如公式(3)所示,其中额外的数据记为E, TinyPerson记为D
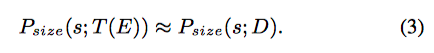
具体的scale match过程如图4所示,具体的算法如算法1所示,概括如下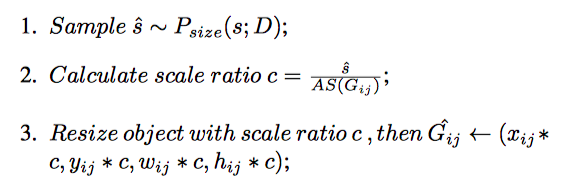
其中
G
i
j
G_{ij}
Gij 表示第
i
i
i 个image中的第
j
j
j 个gt,
A
S
AS
AS 表示绝对大小,


scale matching的结果如图5所示,从结果上看效果还是比较好的,尽管如此,目前的scale matching策略可能导致错序的问题:一个很小的目标可能在算法中sample到很大的目标,反之亦然,因此,作者又提出了单调的scale matching策略,如图6所示,使用一个单调函数
f
f
f 对数据集
E
E
E 中大小为
s
s
s 的目标映射到
s
^
\hat{s}
s^ ,如公式(6)所示:
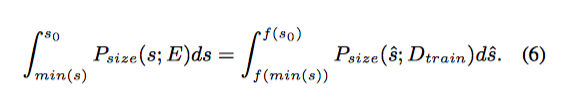


采用两种策略下的结果如表7和表8所示,对于Miss Rate和Average Precison都带来了提升

Thoughts
文章的主要卖点是数据集以及scale matching的方式,后者对于工业界实际的一些业务可能会带来帮助















 6758
6758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









