







Student's t 分布
学生 t 分布(Student's t-distribution)是一种概率分布,常用于统计学中对样本均值的假设检验和置信区间估计。它是由William Sealy Gosset(化名Student)于1908年引入的,用于处理小样本情况下的统计推断。
概率密度函数(PDF):
对于 n-维随机向量 X=(X1,X2,…,Xn),它的多元学生 t 分布的概率密度函数为:
其中:
- μ 是均值向量,
- Σ 是协方差矩阵,
- ν 是自由度参数,
- Γ 是伽玛函数,
- ∣Σ∣ 是协方差矩阵的行列式。
性质和应用:
-
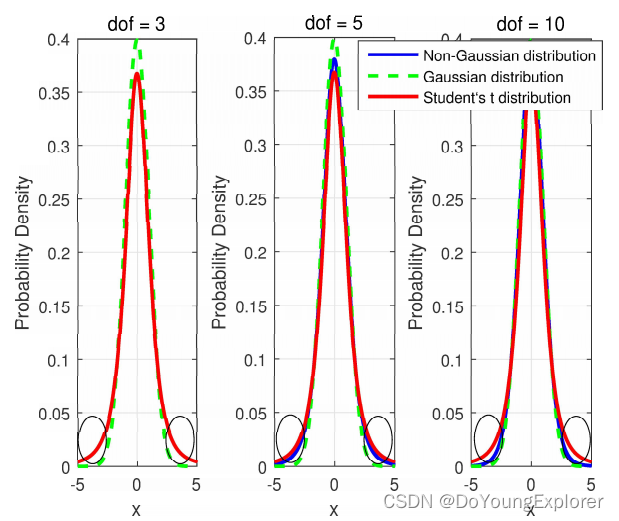
尾部厚重: 多元学生 t 分布在尾部比多元正态分布更厚重,对离群值更具鲁棒性,因此在处理可能存在异常值的数据时较为适用。
-
自由度: 自由度参数 ν 控制了分布的尾部厚重程度,当 ν 较大时,多元学生 t 分布趋近于多元正态分布。
-
小样本: 多元学生 t 分布对于小样本情况的建模效果较好,当样本量较小时,通常优于多元正态分布。
Heavy-tailed特性
学生 t 分布因其具有"重尾"(heavy-tailed)的特性,对于一些异常值(离群值)具有较好的鲁棒性,这使得它在鲁棒滤波算法中得到广泛应用。以下是学生 t 分布适用于鲁棒滤波算法的一些原因:
-
对异常值的鲁棒性: 学生 t 分布在自由度较小(即尾部较重)的情况下,对于离群值的容忍性较高。这使得在存在异常值的情况下,t 分布更能保持估计的稳定性。
-
非正态性假设: 学生 t 分布不要求数据必须满足正态分布的假设,因此适用于一些实际数据中可能存在的非正态性情况。
-
参数的估计: 学生 t 分布的参数(均值、标准差、自由度)可以通过最大似然估计等方法来估计,从而使模型更具灵活性,更适应不同数据的分布特点。
-
异常值对估计的影响较小: 由于学生 t 分布的重尾性,异常值对估计的影响相对较小。这使得滤波算法在数据中存在一些离群值时能够更稳健地估计模型参数。
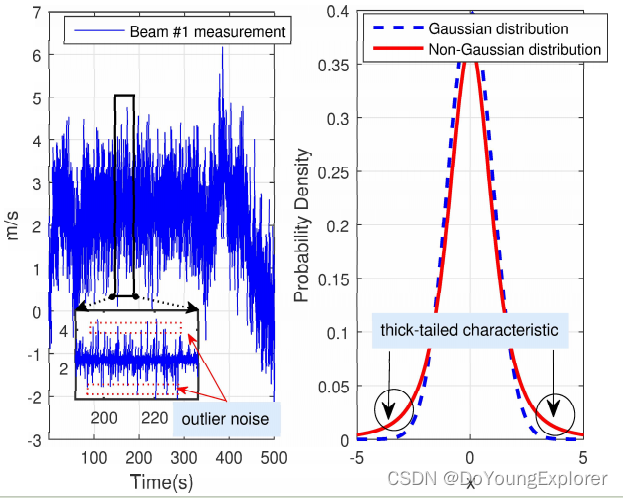
在鲁棒滤波算法中,特别是对于一些实际应用中可能出现异常值的情况,学生 t 分布的使用有助于提高模型的鲁棒性,减小异常值对估计结果的影响。然而,需要根据具体问题和数据特性进行选择,并注意调整分布参数,以使其更好地适应实际情况。
基于学生t分布的变分贝叶斯鲁棒滤波
基于学生 t 分布的变分贝叶斯鲁棒滤波算法的关键在于结合了贝叶斯框架、变分推断和学生 t 分布的鲁棒性,以更适应数据中存在离群值或异常值的情况。这样的算法通常用于状态估计、滤波和机器学习中,特别是在存在噪声、离群值或数据不确定性较大的情况下。
关键要素包括:
-
贝叶斯框架: 使用贝叶斯框架对参数进行建模,通过先验分布和似然函数更新后验分布。这提供了一种灵活的方式来处理不确定性,并使得算法能够适应不同的观测和先验信息。
-
变分推断: 变分推断是一种近似推断的方法,通过最小化两个分布之间的差异来近似后验分布(最小化KLD距离)。在基于学生 t 分布的算法中,变分推断允许通过学生 t 分布来近似真实的后验分布,这对于更好地处理离群值和数据分布的偏差至关重要。
-
学生 t 分布的鲁棒性: 学生 t 分布是一种重尾分布,相对于正态分布更能适应存在离群值或异常值的数据。在变分贝叶斯中,使用学生 t 分布作为后验分布的近似,使得算法更鲁棒,对于数据中的不确定性更具有稳健性。
-
异常值检测和鲁棒滤波: 基于学生 t 分布的变分贝叶斯算法可以有效地检测和处理异常值。学生 t 分布的重尾性质使得它在建模数据中的异常值时更具敏感性,从而能够更准确地估计真实的数据分布。
-
参数调整: 针对具体应用,需要合适地调整学生 t 分布的参数,如自由度等,以平衡对异常值的鲁棒性和对数据整体分布的拟合性能。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











