







前段时间,带大家搞了两台云服务器:
很多小伙伴问:到底能干什么?
于是猴哥继续肝了几篇分享:
- 手把手搭建微信机器人,帮你雇一个24小时在线的个人 AI 助理(上)
- 手把手搭建微信机器人,帮你雇一个24小时在线的个人 AI 助理(下)
- OneAPI-接口管理和分发神器:所有大模型一键封装成OpenAI协议
- FastGPT:给 GPT 插上知识库的翅膀!0基础搭建本地私有知识库
今天继续给大家分享一个有趣的开源项目:免费的人脸检测/识别服务,无需任何机器学习基础,即可集成到任意应用中。
1. 项目简介
CompreFace 是一个免费的开源人脸识别系统,支持 Docker 部署,同时具备网页客户端
和 RESTful API 服务。支持的功能包括:人脸识别、人脸验证、人脸检测、人脸关键点检测、面具检测、头部姿势检测、年龄和性别识别等。
相比市面上已有的人脸识别解决方案,CompreFace 的优势在:
- 完全免费开源
- 支持 CPU, 无需昂贵的 GPU 资源
- docker 一键部署,云端和本地都支持
- 基于最领先的人脸算法
- 自托管,确保隐私数据安全
接下来,我们一起来实操一下~
2. 服务部署
CompreFace 提供了 docker-compose 一键部署。
首先下载配置文件:
mkdir compreface
cd compreface
wget -O tmp.zip 'https://github.com/exadel-inc/CompreFace/releases/download/v1.2.0/CompreFace_1.2.0.zip' && unzip tmp.zip && rm tmp.zip
如果国内下载失败,可参考:一行命令实现 Github 国内下载加速
然后,一键启动:
docker-compose up -d
如果镜像拉取失败,需要配置镜像加速器。
服务启动后,可以打开宝塔面板进行查看:
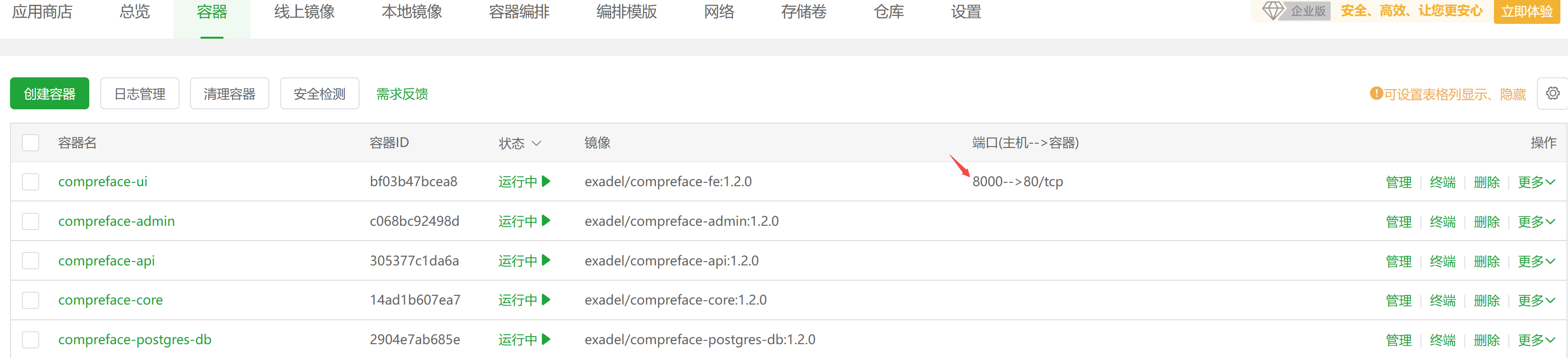
状态是运行中,意味着服务已经正常启动,web 界面的端口号是8000。
浏览器中打开:http://IP:8000,例如:http://101.33.210.xxx:8000/。
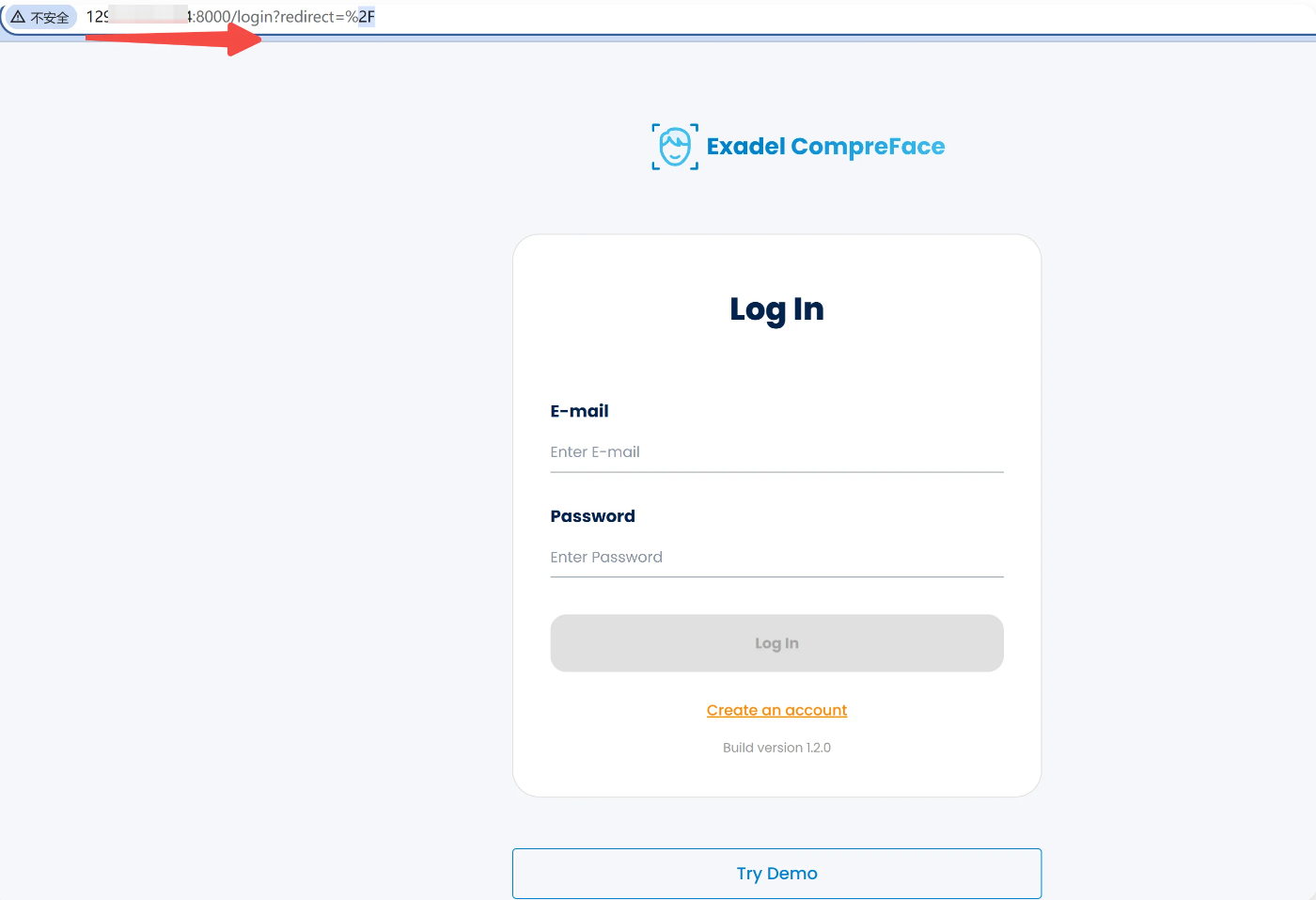
注册一个账号并进行登录,开始试玩吧。
3. 服务测试
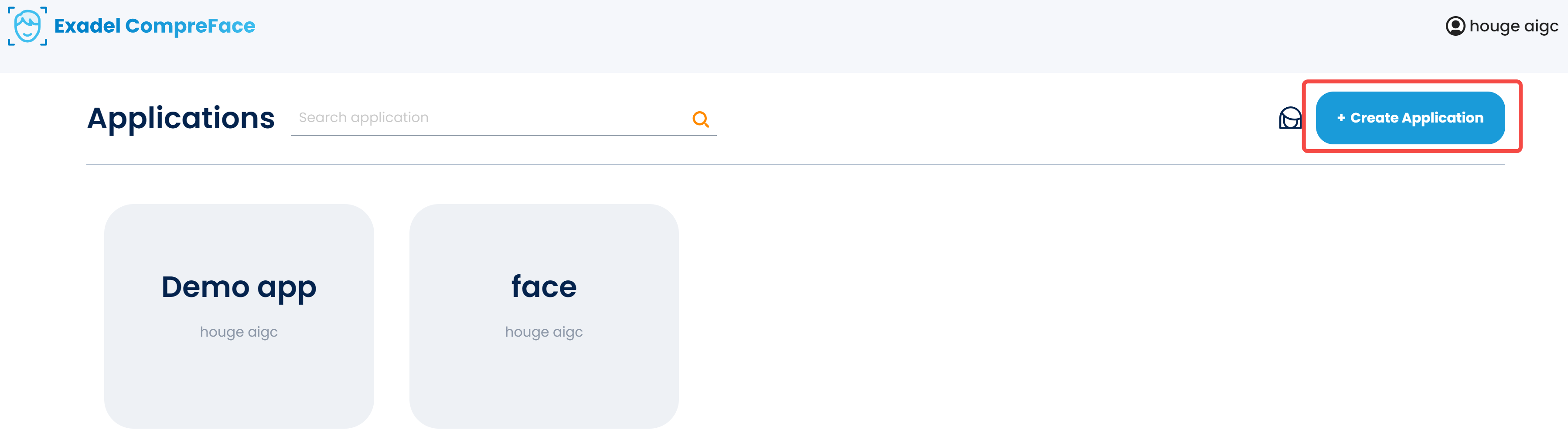
进来以后,首先是创建一个应用。
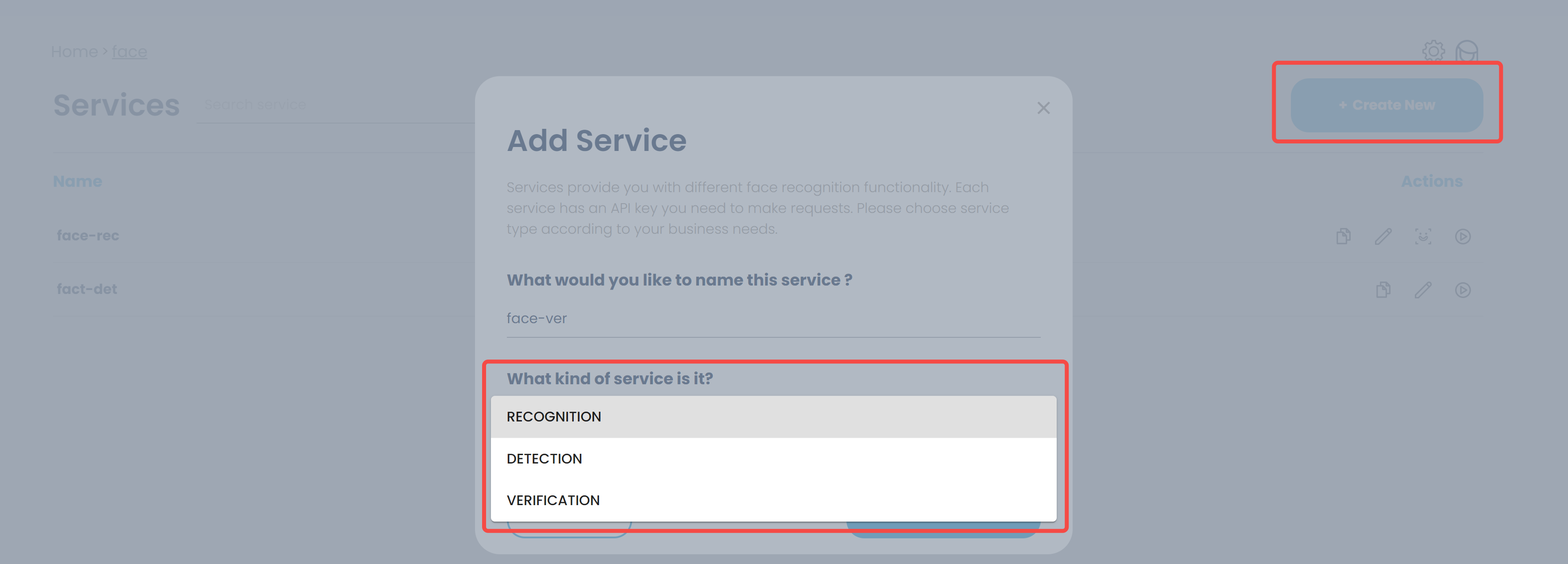
然后,在应用中创建服务,服务类型包括三个:
- 人脸检测
- 人脸识别
- 人脸验证
3.1 Web 端测试
创建好服务后,最右侧红色方框中,点击进行服务测试。

人脸识别服务测试:
首先需要采集人脸 - Face Collection。
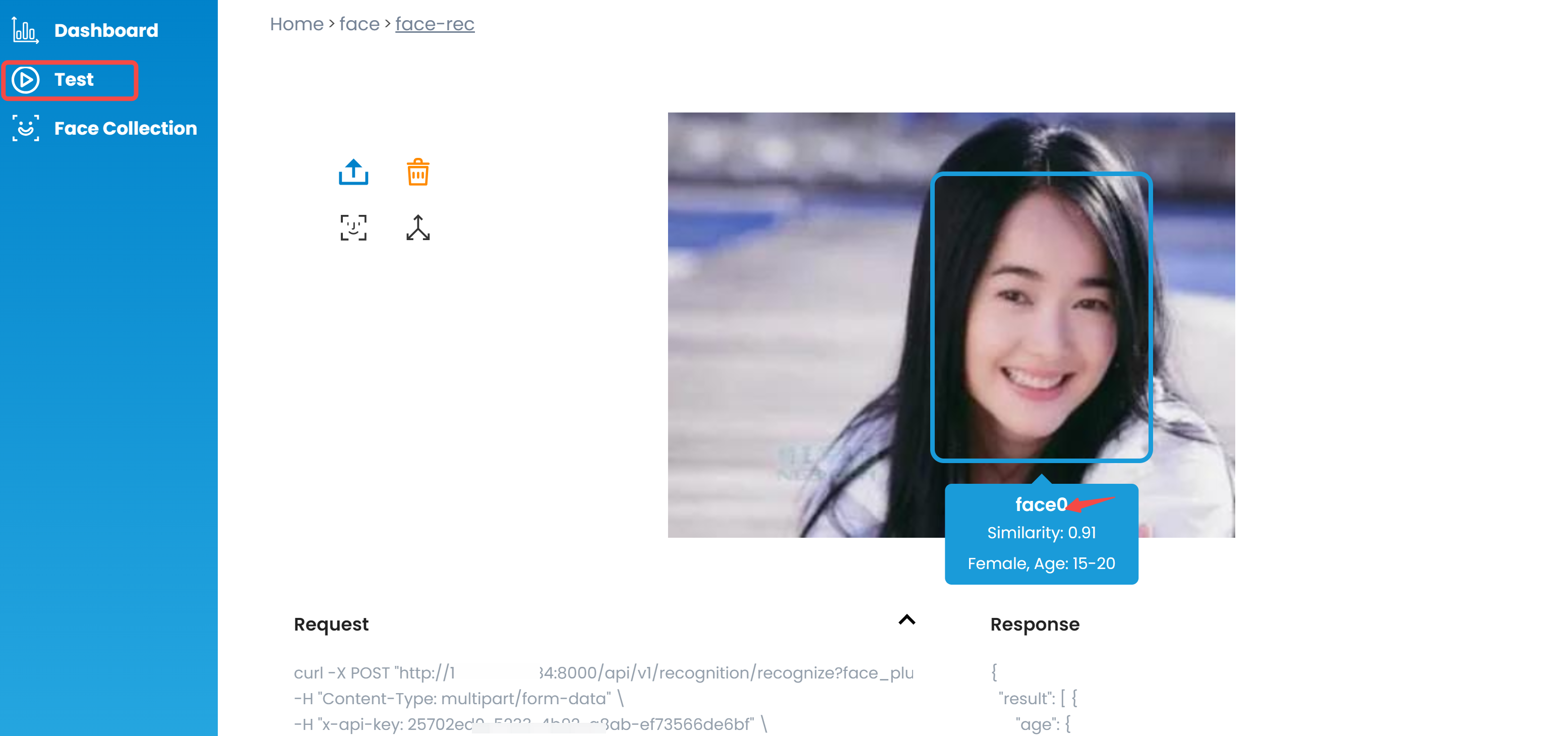
上传你需要识别的人脸 ID,比如我这里新建一个 ID = face0,然后上传一张/多张人脸图片。

接下来,我们来测试一下,上传另一张图片,可以看到模型以 0.91 的相似度,成功命中 face0。
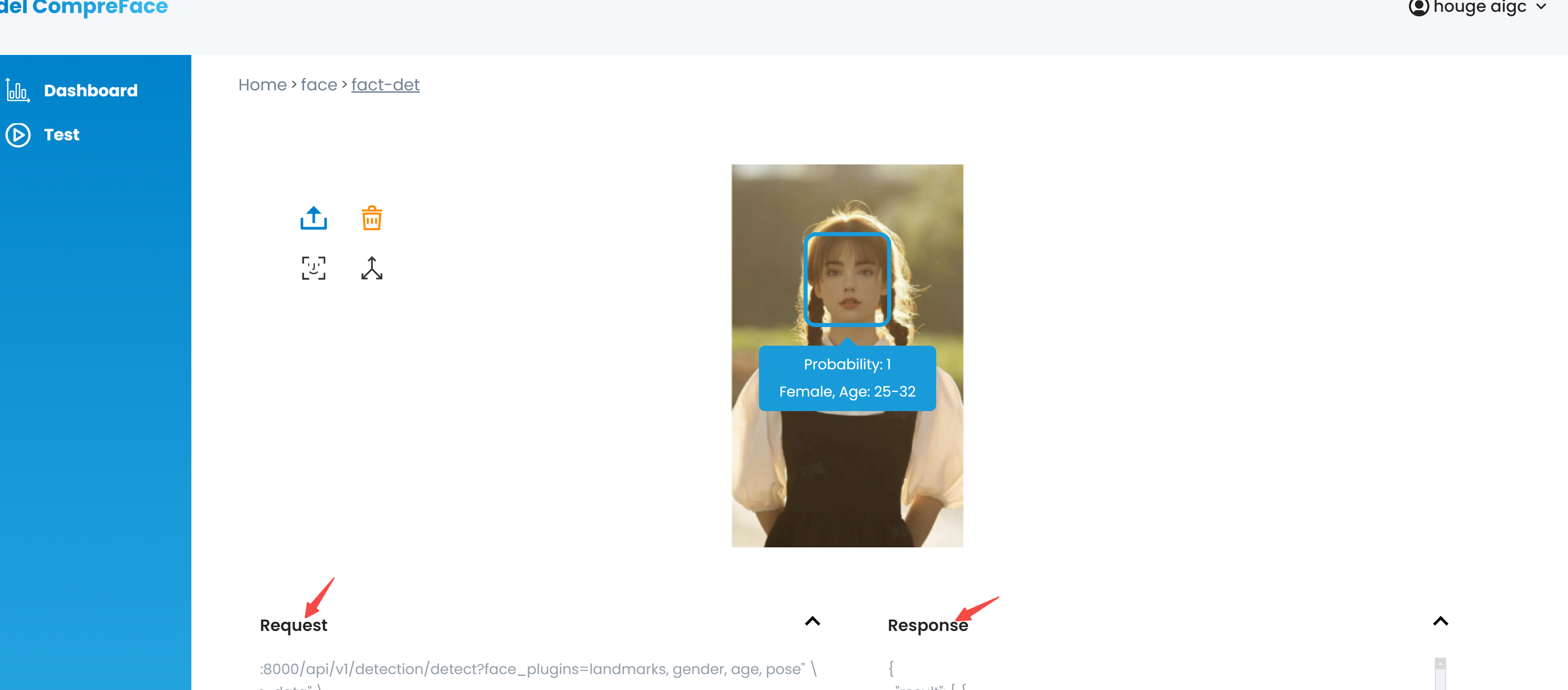
人脸检测服务测试:
只需上传一张人脸图像:
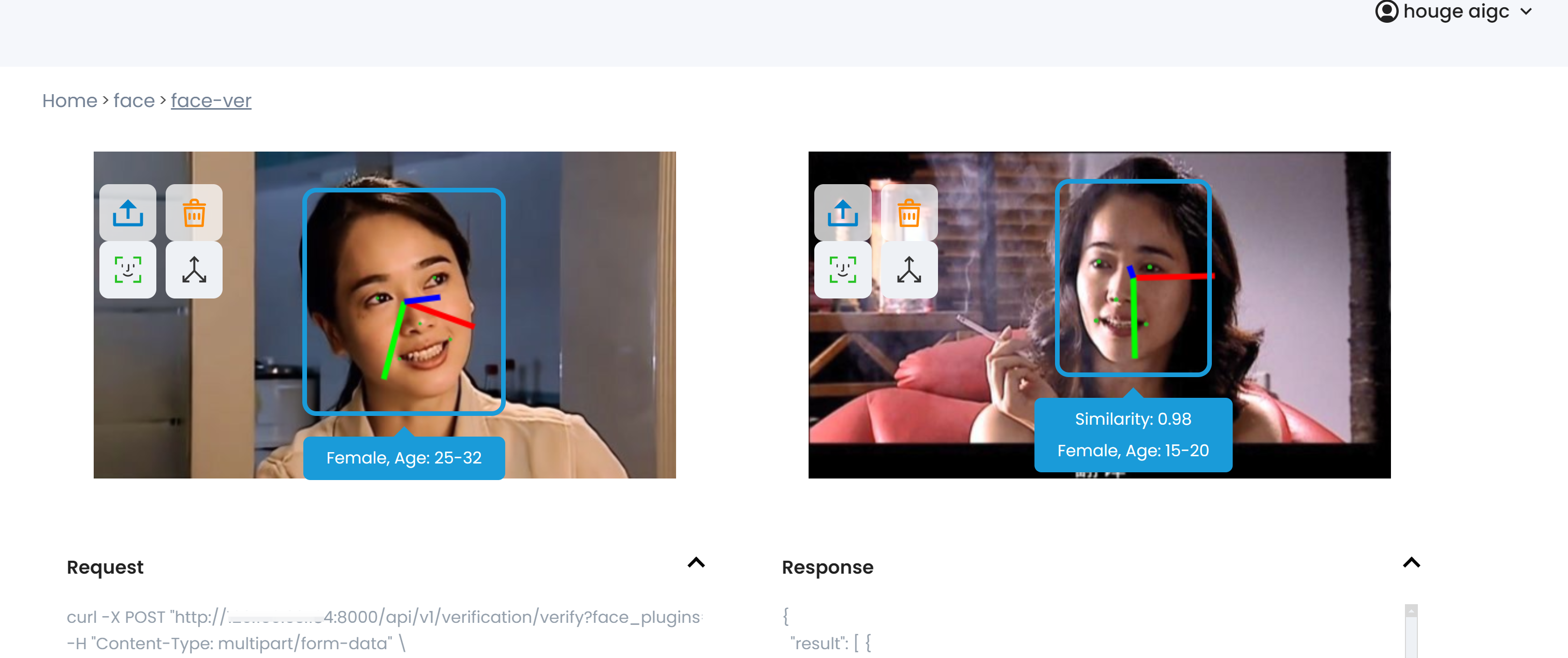
人脸验证服务测试:
人脸验证:分别上传两张图像,验证是否是同一个人,如下图所示。
3.2 API 测试
API 文档:https://github.com/exadel-inc/CompreFace/blob/master/docs/Rest-API-description.md
细心的小伙伴,在 Web 端测试时,已经看到了每种服务的请求详细信息。
这里我们后端采用 Python 给大家展示一下,如何调用服务的 API,方便大家嵌入到自己的应用中。
人脸检测的 API 测试示例代码:
import request
def face_detect():
# 定义 API 的 URL
url = "http://129.150.63.xxx:8000/api/v1/detection/detect/"
# 定义请求头
headers = {
# "Content-Type": "multipart/form-data",
"x-api-key": "4e4b89b7-df58-4e45-b7c0-9a0003878a24" # 替换为实际的服务 API 密钥
}
# 定义请求的参数
params = {
"face_plugins": "landmarks, gender, age, pose", # 是否返回额外信息
"det_prob_threshold": "0.5" # 人脸检测阈值
}
# 定义请求的数据
files = {'file': open('1.jpg', 'rb')}
# 发送 POST 请求
response = requests.post(url, headers=headers, params=params, files=files)
if response.status_code == 200:
print(response.json())
else:
print(response.status_code)
人脸验证的 API 测试示例代码:
def face_verify():
# 定义 API 的 URL
url = "http://129.150.63.184:8000/api/v1/verification/verify"
# 定义请求头
headers = {
# "Content-Type": "multipart/form-data",
"x-api-key": "435764a0-b581-45d2-8a9e-ab841b2afedf" # 替换为实际的服务 API 密钥
}
# 定义请求的参数
params = {
"face_plugins": "landmarks, gender, age, pose", # 是否返回额外信息
"det_prob_threshold": "0.5" # 人脸检测阈值
}
# 定义请求的数据
files = {
"source_image": open("1.jpg", "rb"),
"target_image": open("2.jpg", "rb")
}
# 发送 POST 请求
response = requests.post(url, headers=headers, params=params, files=files)
print(response.json())
特别注意:headers 中不要加 'Content-Type': 'multipart/form-data',这是因为 requests 库会自动根据传递的文件数据创建适当的multipart请求,如果你在请求头中显式设置'Content-Type': 'multipart/form-data',可能会导致请求出现问题。
篇幅有限,我们这里只展示两个例子。更多功能,大家可参考上方的 API 调用文档。
当然,如果你觉得在你的应用中写这么多代码略显麻烦,官方还贴心地提供了 python-sdk,感兴趣的小伙伴可前往查看:
写在最后
本文介绍了如何使用 CompreFace,一个免费的开源人脸识别系统,进行简单易用的服务部署和测试。非常适合没有任何机器学习基础的用户,搭建自己的人脸识别服务。
如果本文对你有帮助,欢迎点赞收藏备用!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









