







前段时间,搞了个微信 AI 小助理-小爱(AI),爸妈玩的不亦乐乎。
不仅可以智能问答,文生图的能力也接了进来:
有朋友问:既然可以文生图,能否文生视频呢?
今天就来盘它!
相比文生图,文生视频更为复杂。你要知道,OpenAI 的 Sora 至今还停留在宣传片里。
不过,国产 Sora 已经遍地开花,从快手的可灵、智谱的清影,再到字节即将开放的PixelDance,但这些模型都是闭源的。
要问开源界有没有能打的?
其实,猴哥之前有分享过:
384x672 分辨率的模型,大约需要 11.5G 显存,效果嘛,也差点意思。
最近, 智谱AI开源了视频生成大模型 CogVideoX。
今日分享,就带大家实操:本地部署 CogVideoX,并将文生视频的能力接入小爱,邀你免费体验。
当前,CogVideoX 分为商业版和开源版,前者需要付费,后者可私有化部署。
1. CogVideoX 商业版
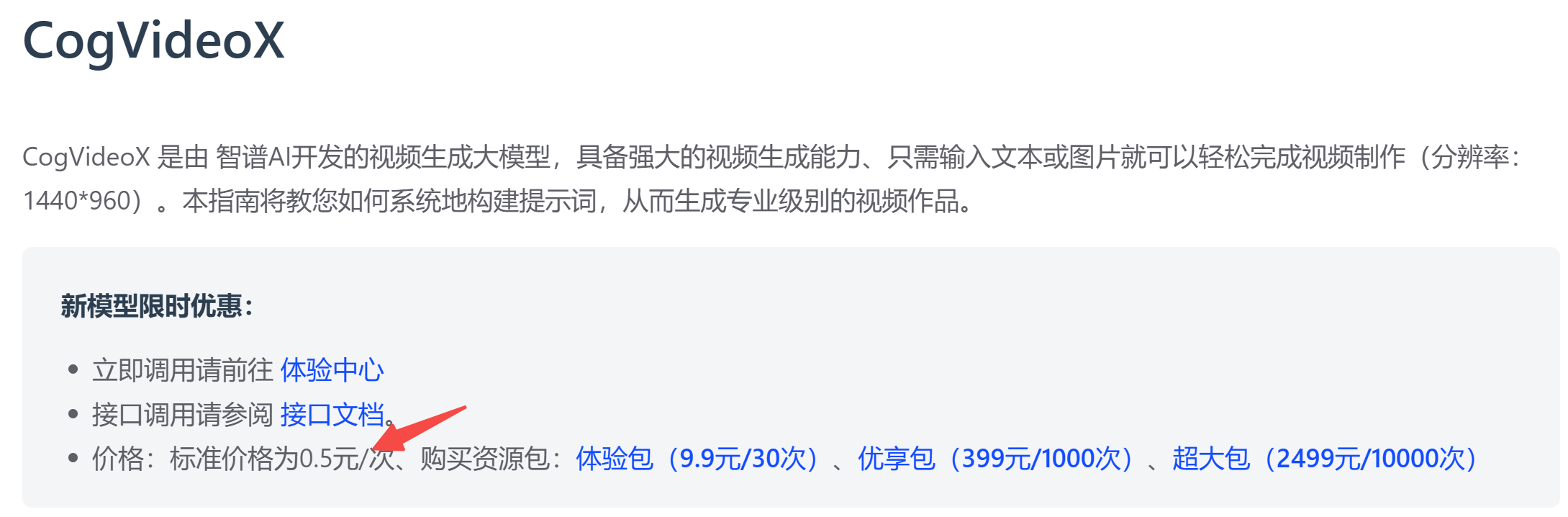
商业版提供了 API 接口,0.5 元/张,支持文生视频和图生视频,目前没看到有免费额度。
不过,新用户注册,可免费获得 GLM-4-Air 2000万Tokens。👉注册地址
下面实操带大家玩转 CogVideoX 开源版👇
2. CogVideoX 开源版
项目开源协议:Apache,因此可以随便商业化哦。
官方称 CogVideoX 是清影同源的开源版本视频生成模型。共分为三个版本:
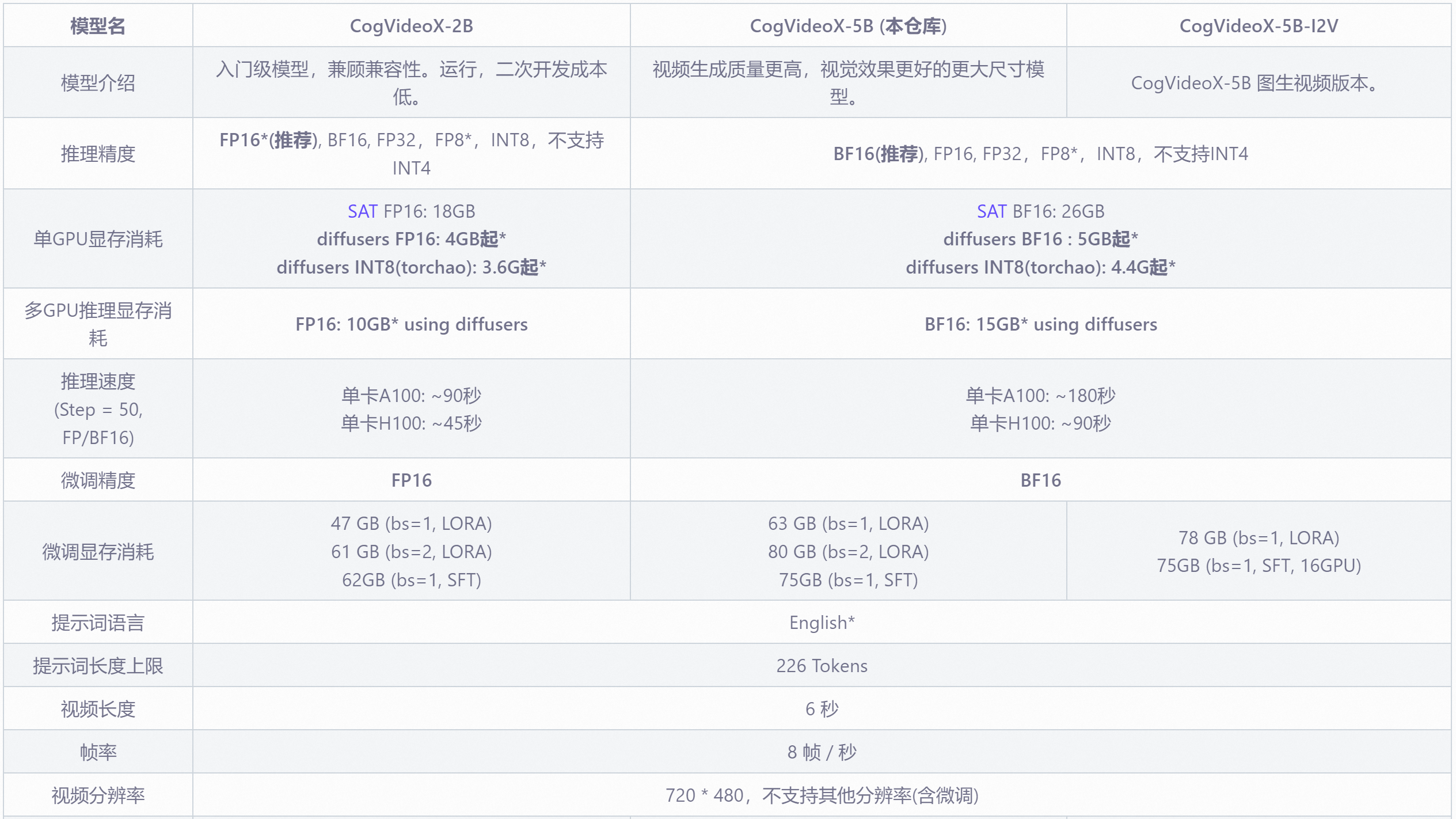
CogVideoX-2B 小杯模型:
- 显存需求:4GB 起,推荐 FP16 推理;
CogVideoX-5B 大杯模型:
- 显存需求:5GB 起,推荐 BF16 推理;
- 大杯更出色!就是速度要慢一拍。
注:一个月前,玩 CogVideoX 需要 18G 显存,这门槛,怕是挡住了不少 AI 爱好者吧。
2.1 在线体验
国内直达体验地址:https://modelscope.cn/studios/ZhipuAI/CogVideoX-5b-demo
5B 模型已上线魔搭社区,感兴趣的小伙伴可以在线体验。
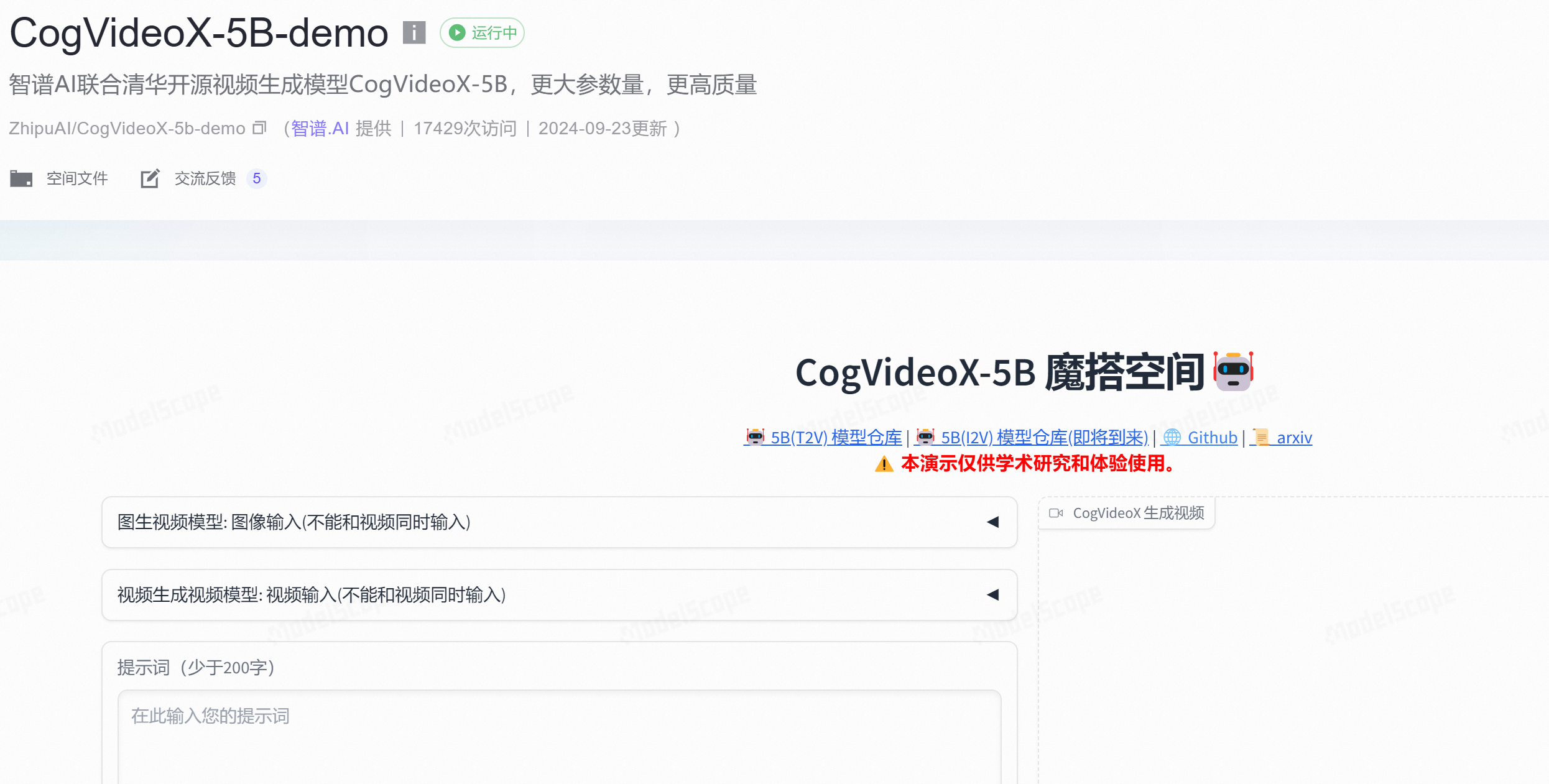
当然,如果要嵌入到自己应用中,就得自己部署了。
2.2 本地跑通
首先需要将模型 down 到本地。
模型参数量比较大,推荐大家使用 modelscope 命令行下载:
pip install modelscope
modelscope download --model ZhipuAI/CogVideoX-2b
模型文件默认保存在:
~/.cache/modelscope/hub/ZhipuAI/CogVideoX-2b
如果采用原生 diffusers 库进行测试,实测峰值 4G 显存就够:
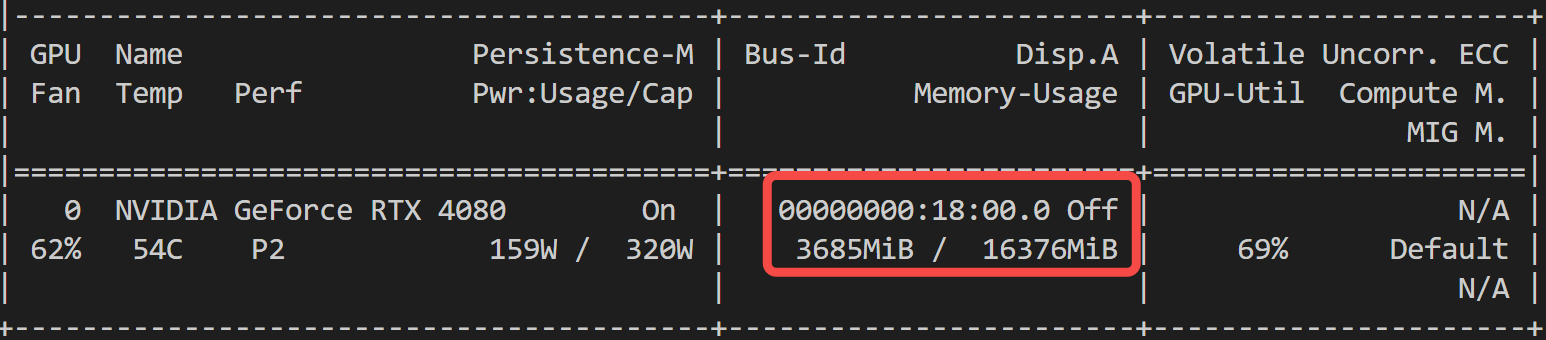
480 x 720 分辨率的 6 秒视频(fps=8),Diffusion 部分推理耗时 03:25
100%|█| 50/50 [03:25<00:00, 4.11s/it]
如果关闭 vae 部分的优化,峰值GPU需要 12G 显存:
# pipe.vae.enable_slicing()
# pipe.vae.enable_tiling()
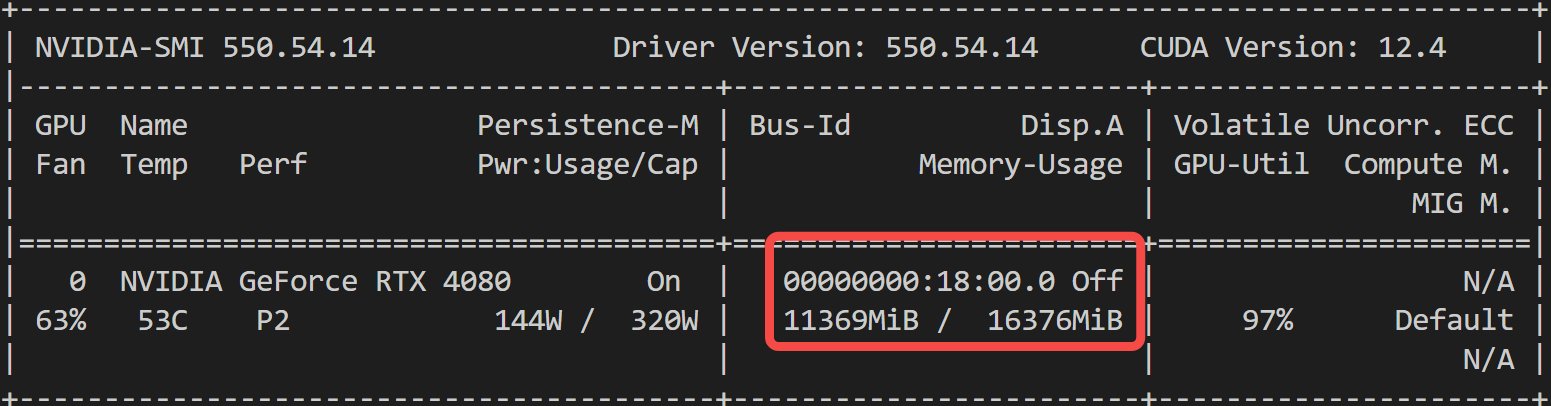
这里,也可以采用官方推荐的 PytorchAO 库,来进行量化加速,降低 CogVideoX 的内存需求。
先把 torchao 装上:
pip install torchao
采用 torchao,会将每个模型量化后,再执行推理:
text_encoder = T5EncoderModel.from_pretrained(model_path, subfolder="text_encoder", torch_dtype=torch.float16)
quantize_(text_encoder, fpx_weight_only(3, 2))
transformer = CogVideoXTransformer3DModel.from_pretrained(model_path, subfolder="transformer", torch_dtype=torch.float16)
quantize_(transformer, fpx_weight_only(3, 2))
vae = AutoencoderKLCogVideoX.from_pretrained(model_path, subfolder="vae", torch_dtype=torch.float16)
quantize_(vae, fpx_weight_only(3, 2))
我们来看下,显存占用情况和推理耗时:
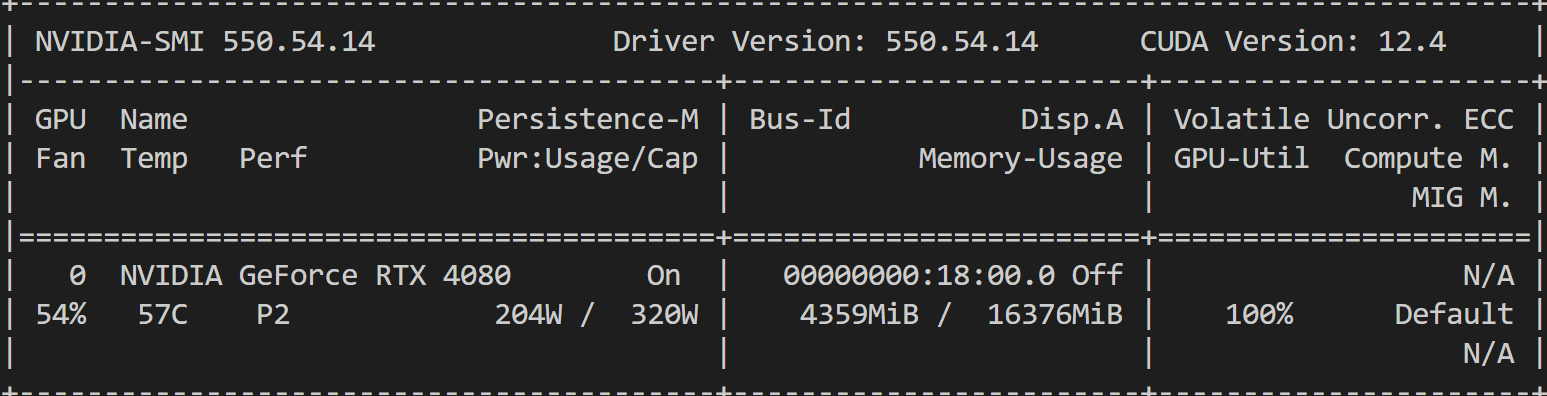
Diffusion 部分推理耗时 02:35,减少了近 1 分钟,赞!
100%|█| 50/50 [02:35<00:00, 3.36s/it]
此外,如果你觉得本地装环境实在太麻烦,推荐了解下 CogVideoX-Fun 这个项目。基于 CogVideoX 结构重构了 pipeline,支持更多分辨率。
重点是提供了 docker 方式安装,方便快速部署体验,不好用,直接删库跑路。而且提供的是阿里云镜像,国内下载无压力。
sudo docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun
这里也跑一个测试用例给大家看看:2B 模型 11G 显存,GPU 利用率打满:
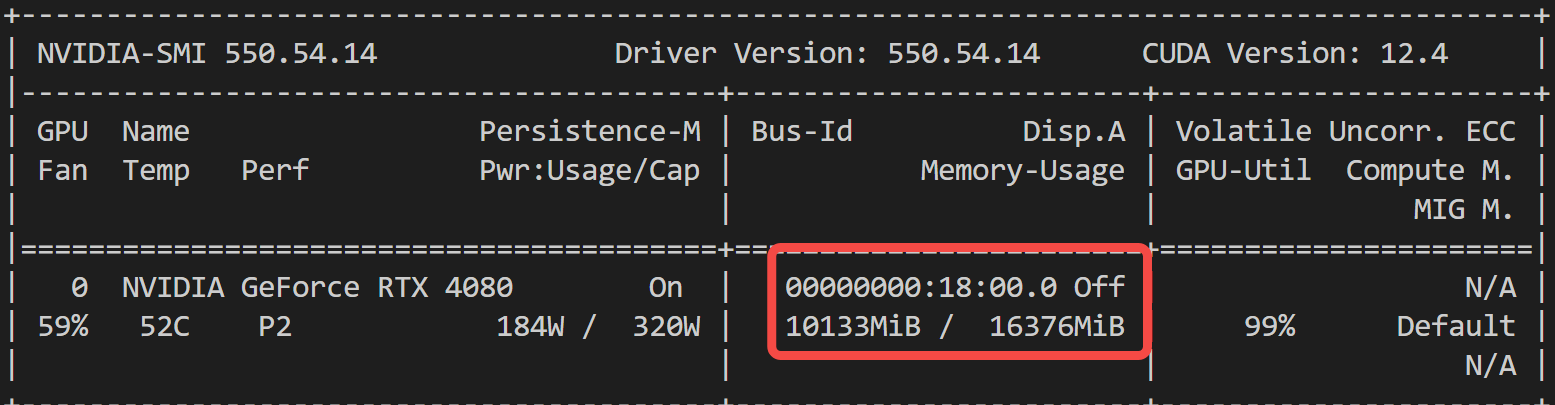
384 x 672分辨率的 6 秒视频(fps=8),耗时 02:32:
100%|█| 50/50 [02:32<00:00, 3.04s/it]
最后,给大家放两个生成 demo 感受下:
a panda
a cat
2.3 服务部署
本地测试成功,我们封装成一个 fastapi 后端服务,之前的教程中多次提到过,这里就不再赘述了。
请求体定义如下:只要把文生视频的 prompt 和 帧数 传进来就好了。
app = FastAPI()
class VideoRequest(BaseModel):
prompt: str
num_frames: int = 49
3 接入小爱
我们先来新增一个意图类别:视频生成,判断用户是否需要小爱调用视频生成服务。
至此,小爱可以识别的意图共有 8 个:
['天气', '步行规划', '骑行规划', '驾车规划', '公交规划', '地点推荐', '图片生成', '视频生成']
因为 CogVideoX 只支持英文,如果要让用户输入英文提示词,估计头都大了。
所以,触发视频生成后,小爱需要根据用户输入,自动生成给 CogVideoX 的英文提示词。
这步其实不难,完全可以交给大模型来做,比如可以撰写提示词:
sys_video_gen = '''
用户请求视频生成,请从这段聊天记录中找到和视频生成相关的关键词,最终生成给视频生成模型的英文提示词,只回答英文提示词内容,无需回答其它任何内容。
要求:
1.提示词的关键组成部分包括:(镜头语言 +景别角度+ 光影) + 主体 (主体描述) + 主体运动 +场景 (场景描述) + (氛围)
2.提示词中不要出现中文,只使用英文。
'''
最后,我们来看看测试效果吧:
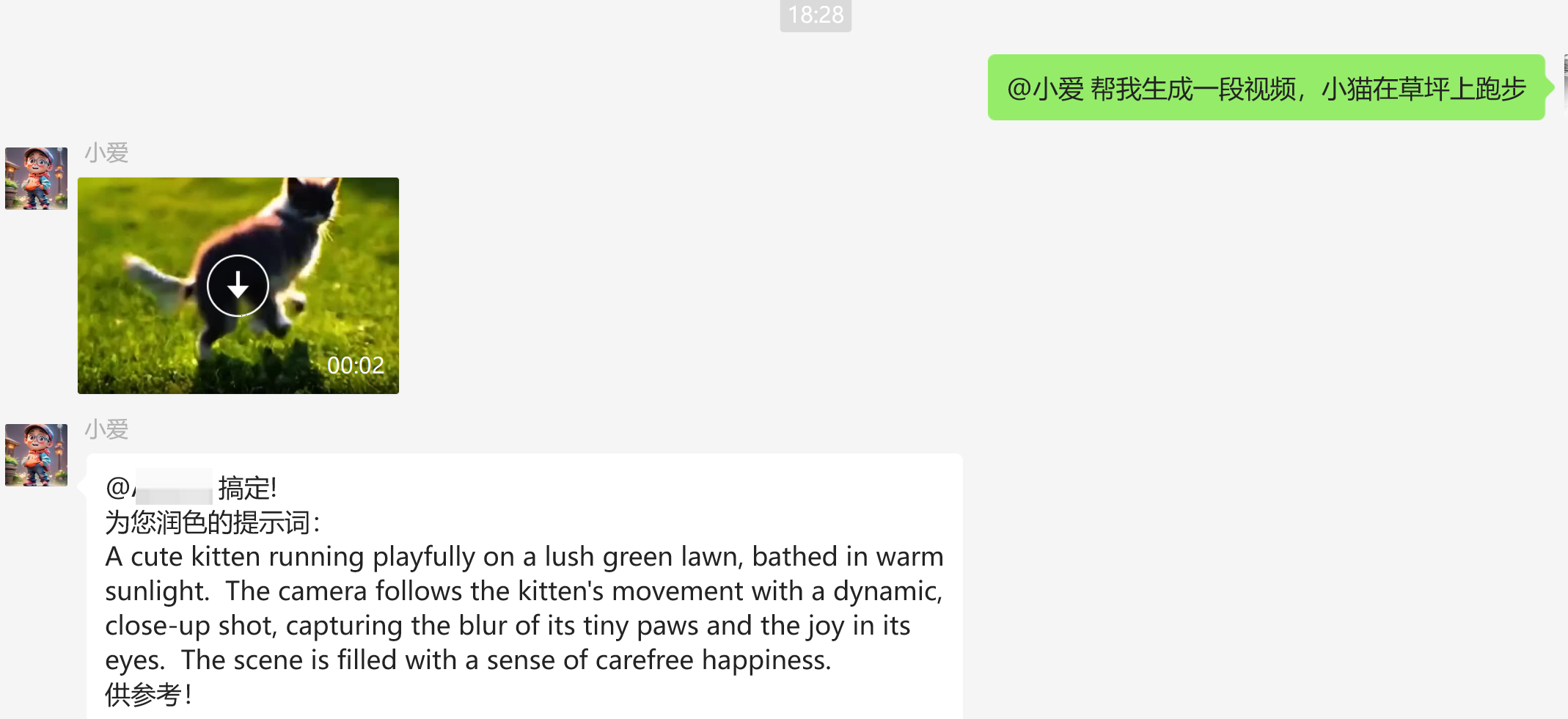
写在最后
本文通过本地部署 CogVideoX,成功为小爱接入了文生视频能力。
如果对你有帮助,不妨点赞 收藏备用。
大家有更好的想法,欢迎来聊👇
为方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
小爱也在群里,公众号后台「联系我」,拉你进群。
猴哥的文章一直秉承分享干货 真诚利他的原则,最近陆续有几篇分享免费资源的文章被CSDN下架,申诉无效,也懒得费口舌了,欢迎大家关注下方公众号,同步更新中。

















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









