







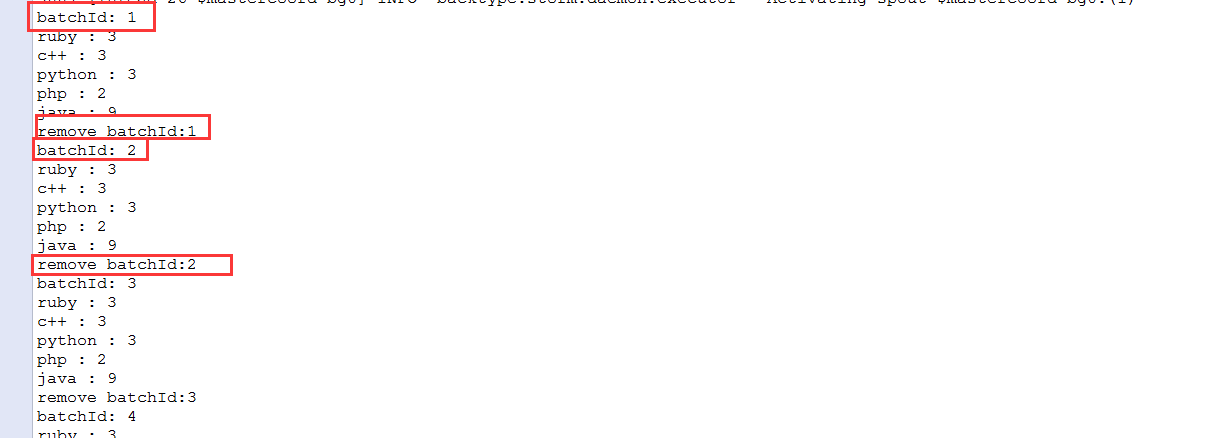
在该例子中,使用IBatchSpout接口实例化一个spout,重写emitBatch方法,方法中将根据batchId将数据batchesMap中(batchesMap其实就是一个批的概念,这批数据可以自己指定,我这里就是指定了4批的数据,也就是DATA_MAP里面的数据,由于在emitBatch会指定一个batchId,所以这个batchId就和这一批数据进行挂钩。如果以后有事务,那么这批数据其中一个数据处理失败了,那么这批数据将会进行一次重发。),再将发射出去。最终处理完毕之后回调ack方法,再根据batchId将batchesMap中的数据删除。该方法并未实现事务属于non-tranctional spout.
其中WordCountTopology类:
public class WordCountTopology {
public static StormTopology buildTopology() {
TridentTopology topology = new TridentTopology();
//使用IBatchSpout接口实例化一个spout
SubjectsSpout spout = new SubjectsSpout(4);
//指定输入源spout
Stream inputStream = topology.newStream("spout", spout);
/**
* 要实现流sqout - bolt的模式 在trident里是使用each来做的
* each方法参数:
* 1.输入数据源参数名称:subjects
* 2.需要流转执行的function对象(也就是bolt对象):new Split()
* 3.指定function对象里的输出参数名称:subject
*/
//设置随机分组
inputStream.shuffle()
.each(new Fields("subjects"), new SplitFunction(), new Fields("sub"))
//进行分组操作:参数为分组字段subject,比较类似于我们之前所接触的FieldsGroup
.groupBy(new Fields("sub"))
//对分组之后的结果进行聚合操作:参数1为聚合方法为count函数,输出字段名称为count
.aggregate(new Count(), new Fields("count"))
//继续使用each调用下一个function(bolt)输入参数为subject和count,第二个参数为new Result() 也就是执行函数,第三个参数为没有输出
.each(new Fields("sub", "count"), new ResultFunction(), new Fields())
.parallelismHint(1);
return topology.build(); //利用这种方式,我们返回一个StormTopology对象,进行提交
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
//设置batch最大处理
conf.setNumWorkers(2);
conf.setMaxSpoutPending(20);
if(args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident-wordcount", conf, buildTopology());
Thread.sleep(10000);
cluster.shutdown();
} else {
StormSubmitter.submitTopology(args[0], conf, buildTopology());
}
}
}
SubjectsSpout类实现了IBatchSpout接口实现批量发送。
public class SubjectsSpout implements IBatchSpout {
/** serialVersionUID */
private static final long serialVersionUID = 1L;
//批处理大小
private int batchSize;
//容器
private HashMap<Long, List<List<Object>>> batchesMap = new HashMap<Long, List<List<Object>>>();
public SubjectsSpout(int batchSize){
this.batchSize = batchSize;
}
private static final Map<Integer, String> DATA_MAP = new HashMap<Integer, String>();
static {
DATA_MAP.put(0, "java java php ruby c++");
DATA_MAP.put(1, "java python python python c++");
DATA_MAP.put(2, "java java java java ruby");
DATA_MAP.put(3, "c++ java ruby php java");
}
@Override
public void open(Map conf, TopologyContext context) {
// TODO Auto-generated method stub
}
@Override
public void emitBatch(long batchId, TridentCollector collector) {
List<List<Object>> batches = new ArrayList<List<Object>>();
for (int i= 0; i < this.batchSize; i++) {
batches.add(new Values(DATA_MAP.get(i)));
}
System.out.println("batchId: " + batchId);
this.batchesMap.put(batchId, batches);
for(List<Object> list : batches){
collector.emit(list);
}
}
@Override
public Fields getOutputFields() {
return new Fields("subjects");
}
@Override
public void ack(long batchId) {
System.out.println("remove batchId:" + batchId);
this.batchesMap.remove(batchId);
}
@Override
public Map getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
@Override
public void close() {
// TODO Auto-generated method stub
}
}















 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









