






创新实训周报2024.6.2
本周使用从百科和wiki上爬取的数据,以及使用模型提取的实体关系文件建立格式化数据,并导入neo4j数据库,提供后端进行查询调用。
在构造数据时对图谱的数据进行了进一步的数据清洗和过滤,同时对某些节点进行了合并和删除等操作使图谱匹配更加精确。
1.实体-关系图谱的存储
1.1大模型提取实体关系的文本数据格式化
原保存格式
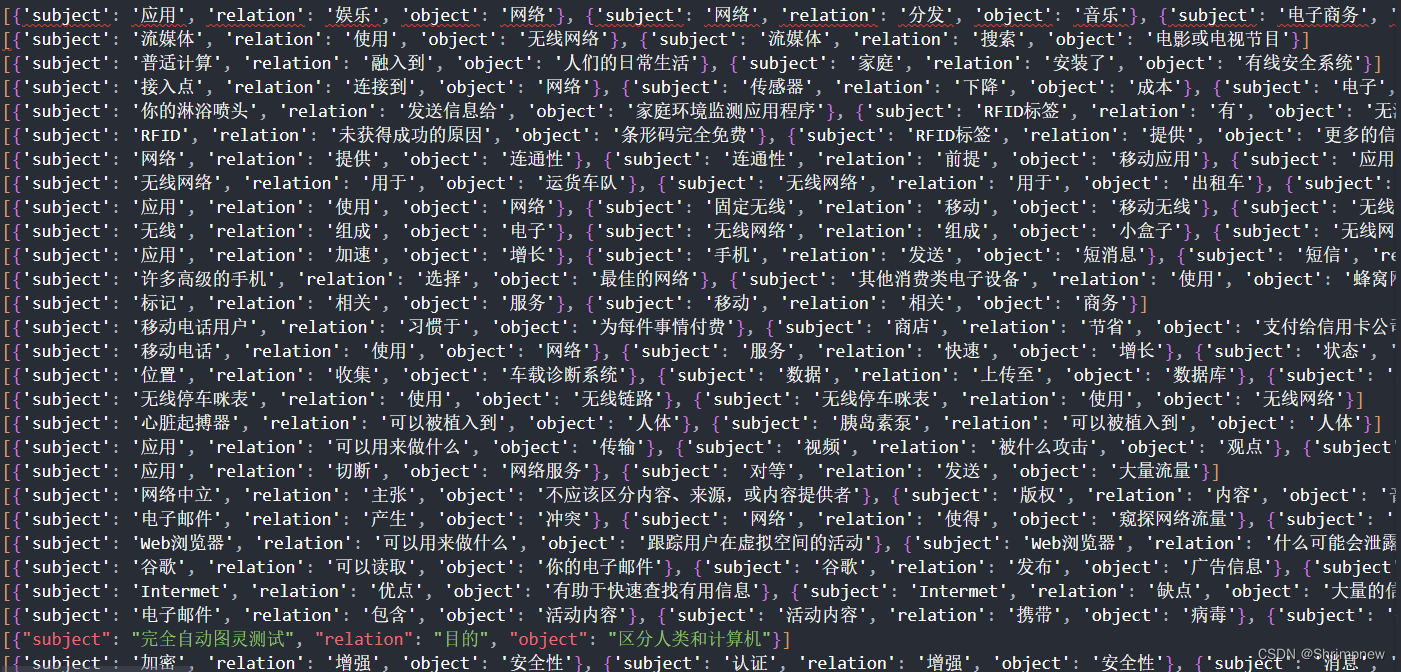
清洗后的格式

1.2使用python读取json文件并导入数据库
1.2.1. 读取 JSON 文件
代码首先从文件路径 ./datasets/cn_kg_re.json 中读取 JSON 数据。每一行 JSON 数据包含一个三元组(subject, relation, object),这些数据表示实体及其关系。
1.2.2. 解析 JSON 数据
读取的每一行 JSON 数据会被解析成 Python 列表,并将所有解析后的三元组存储在 triplets 列表中。
1.2.3. 连接到 Neo4j 数据库
代码使用 Neo4j 的 Python 驱动连接到本地 Neo4j 数据库,连接 URI 是 bolt://localhost:7687,认证信息是用户名 neo4j 和密码 11111111。
1.2.4. 定义关闭数据库连接函数
定义了一个 close 函数用于关闭数据库连接。
1.2.5. 创建节点和关系
定义了一个 create_nodes_and_relationships 函数,用于在 Neo4j 数据库中创建节点和关系。该函数接受一个三元组列表作为参数,并使用 Cypher 查询在数据库中创建节点和关系。
主要功能:
- MERGE (a{name: $subject}): 如果一个名为
subject的节点不存在,则创建它。 - MERGE (b{name: $object}): 如果一个名为
object的节点不存在,则创建它。 - MERGE (a)-[r{type: $relation}]->(b): 创建一个从
a到b的关系relation,如果该关系不存在。
1.2.6. 存储所有三元组数据到 Neo4j
调用 create_nodes_and_relationships 函数,将所有三元组数据存储到 Neo4j 数据库中。
1.2.7. 关闭数据库连接
调用 close 函数,关闭数据库连接。
import json
from neo4j import GraphDatabase
# 读取JSON文件
with open('./datasets/cn_kg_re.json', 'r', encoding='utf-8') as file:
data = file.read().splitlines()
# 将每行的JSON数据解析成Python列表
triplets = []
for line in data:
print(line)
triplets.extend(json.loads(line))
# 连接到Neo4j数据库
uri = "bolt://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j", "11111111"))
def close():
driver.close()
def create_nodes_and_relationships(triplet):
with driver.session() as session:
for item in triplet:
subject = item['subject']
relation = item['relation']
obj = item['object']
# 使用Cypher查询创建节点和关系
query = """
MERGE (a:Entity {name: $subject})
MERGE (b:Entity {name: $object})
MERGE (a)-[r:RELATION {type: $relation}]->(b)
"""
session.run(query, subject=subject, relation=relation, object=obj)
# 将所有三元组数据存储到Neo4j中
create_nodes_and_relationships(triplets)
# 关闭数据库连接
close()
1.3导入数据库效果
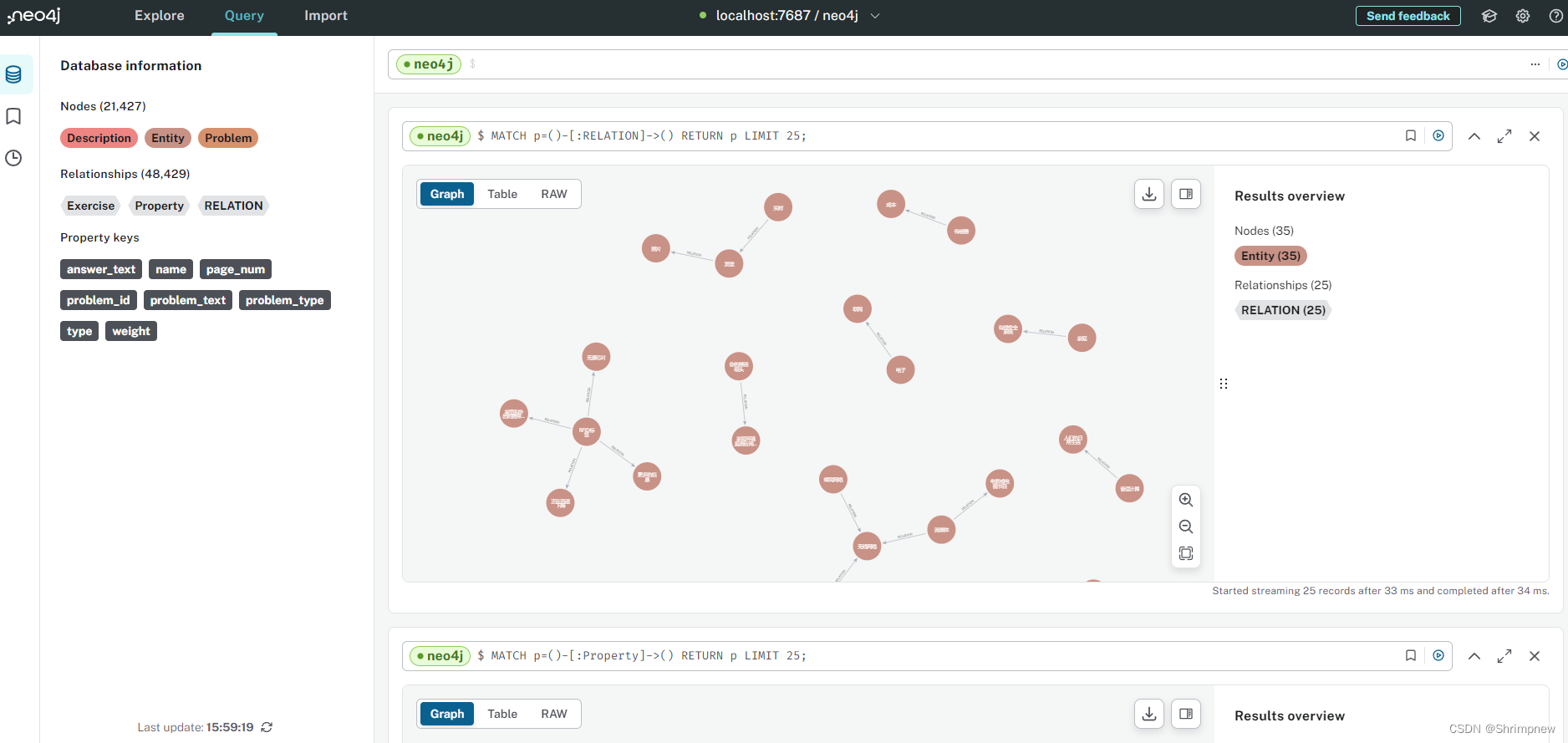
2.实体相关描述的存储
2.1数据清洗
首先使用大模型从材料中提取得到的相关实体描述格式是不严格的,比如存在以下问题
2.1.1 json格式不正确

2.1.2 json不闭合
 2.1.3 json数组一行变多行
2.1.3 json数组一行变多行

2.1.4 存在非格式化文本

import re
import json
data = '''{"entity": "系统", "description": "现在已被许多操作系统广泛应用于Intermet程序设计中,尤其是基于UNIX的系统,Windows系统也有一个套接字风格的API,称为“winsock”.", "relation": "存在"}
]
[{'entity': '传输层', 'description': '为它分配相应的表空间', 'relation': '分配'}, {'entity': '分配', 'description': '在传输实体中', 'relation': '位置'}, ... '''
pattern = re.compile(r'\[.*?\]', re.DOTALL)
matches = pattern.findall(data)
for match in matches:
match = match.replace("'", '"')
try:
json_array = json.loads(match)
print(json.dumps(json_array, ensure_ascii=False, indent=2))
except json.JSONDecodeError as e:
print(f"JSON 解析错误: {e}")
2.1.5 清洗后数据样例

2.2 导入neo4j数据库
2.2.1. 数据读取与解析
2.2.1.1 读取JSON文件
代码从文件路径./datasets/cn_kg_prop_filted_with_page.json中逐行读取JSON数据,并解析成Python列表。每行JSON数据表示一个实体及其相关描述信息。
2.2.1.2 解析JSON数据
将每行JSON数据解析成Python列表,并将解析后的数据存储在triplets列表中。
2.2.2. 数据处理
2.2.2.1 构建实体-关系描述字典
构建一个字典prop_dict,该字典的键是实体名,值是另一个字典,其中存储了实体的关系及其对应的描述信息和页码。
2.2.3. 数据导入Neo4j数据库
2.2.3.1 连接到Neo4j数据库
使用Neo4j的Python驱动连接到本地Neo4j数据库。
2.2.3.2 创建节点和关系
定义create_nodes_and_relationships函数,该函数遍历prop_dict字典,并使用Cypher查询将实体及其描述信息导入到Neo4j数据库中。
2.2.3.3 清理已有描述信息
定义clear_description函数,用于清理数据库中已有的描述信息,以避免重复导入。
2.2.4. 执行数据导入流程
2.2.4.1 清理已有数据
调用clear_description函数,清理Neo4j数据库中已有的描述信息。
2.2.4.2 导入新数据
调用create_nodes_and_relationships函数,将处理后的实体描述数据导入Neo4j数据库。
2.2.4.3 关闭数据库连接
调用close函数,关闭数据库连接。
import json
from neo4j import GraphDatabase
with open('./datasets/cn_kg_prop_filted_with_page.json', 'r', encoding='utf-8') as file:
data = file.read().splitlines()
triplets = []
for line in data:
# print(line)
triplets.extend(json.loads(line))
prop_dict = {}
for item in triplets:
if item['entity'] not in prop_dict.keys():
prop_dict[item['entity']] = {}
if item['relation'] not in prop_dict[item['entity']].keys():
prop_dict[item['entity']][item['relation']] = []
prop_dict[item['entity']][item['relation']].append({"description": item['description'], "page_num": item['page_num']})
for k in prop_dict.keys():
dict = prop_dict[k]
# if(len(dict) > 10):
# print(k, len(dict))
total_len = 0
for r in dict:
props = dict[r]
# total_len += len(';'.join(props))
# if(len(props) > 10):
# print(k, r, len(props), len(';'.join(props)))
# if(total_len > 1000):
# print(total_len)
uri = "bolt://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j", "11111111"))
def close():
driver.close()
def create_nodes_and_relationships(prop_dict):
with driver.session() as session:
now_progress = 0
for k in prop_dict.keys():
print("key", k, str(now_progress) + '/' + str(len(prop_dict)))
now_progress += 1
dict = prop_dict[k]
entity = k
for r in dict:
if len(r) < 2 and r != "是":
continue
props = dict[r]
property = r
description = ""
id = 1
for s in props:
if len(description) + len(s) <= 1000:
if len(description) > 0:
description += '\n'
description += s['description']
id += 1
else:
break
if len(description) > 500:
print(entity, property, description)
# 使用Cypher查询创建节点和关系
for s in props:
if len(s['description']) <= 5:
continue
query = """
MERGE (a:Entity {name: $entity})
MERGE (b:Description {name: $description, page_num: $page_num})
MERGE (a)-[r:Property {type: $property}]->(b)
"""
session.run(query, entity=entity, property=property, description=s['description'], page_num=s['page_num'])
def clear_description():
with driver.session() as session:
query = """
MATCH ()-[p:Property]->()
DELETE p
"""
session.run(query)
query = """
MATCH (d:Discription)
DELETE d
"""
session.run(query)
query = """
MATCH (d:Description)
DELETE d
"""
session.run(query)
clear_description()
# 将所有三元组数据存储到Neo4j中
create_nodes_and_relationships(prop_dict)
# 关闭数据库连接
close()
2.3 实体描述导入数据库效果
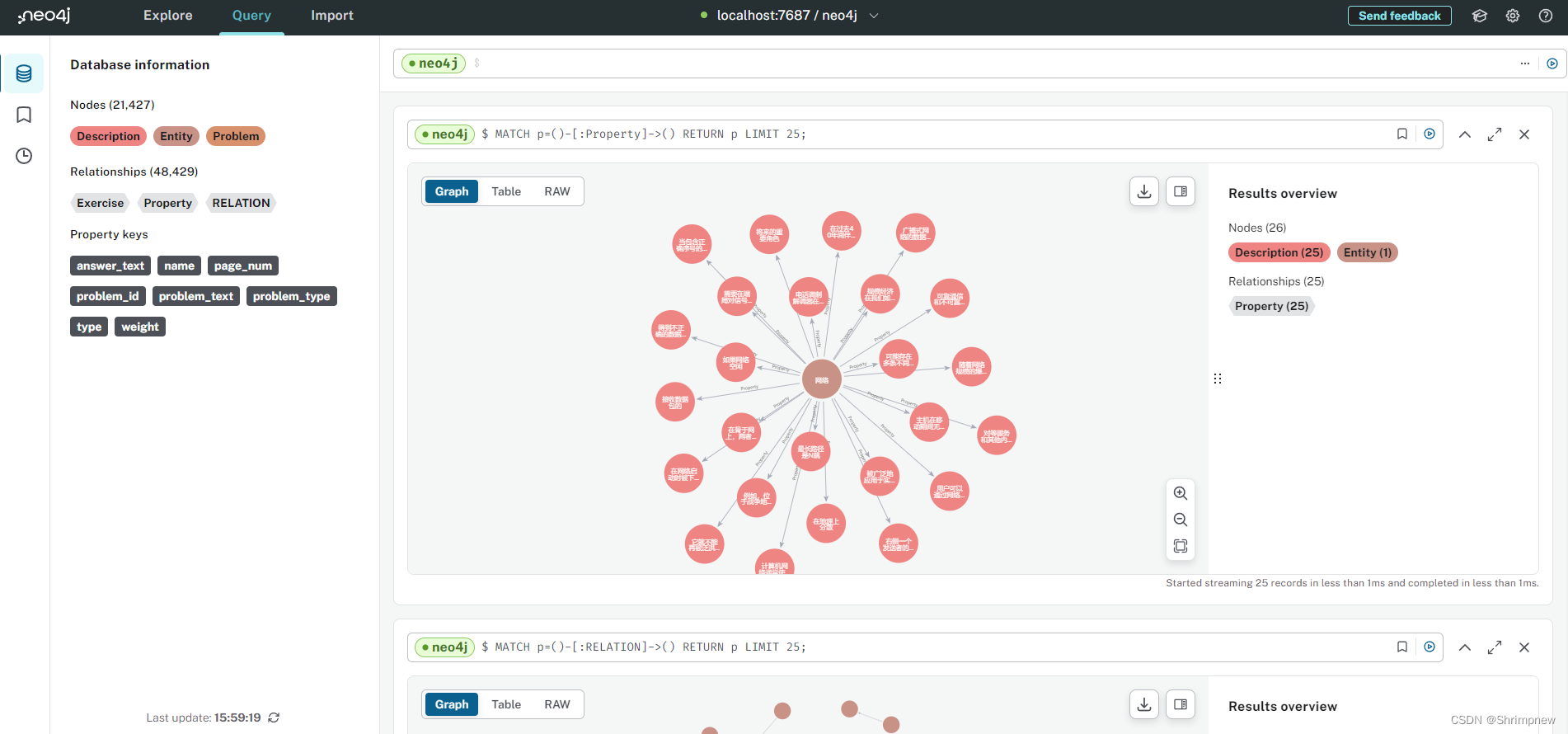
3.题目导入数据库
3.1 题目文本格式化处理
我们从网上爬取收集的题目主要为文本数据,形如
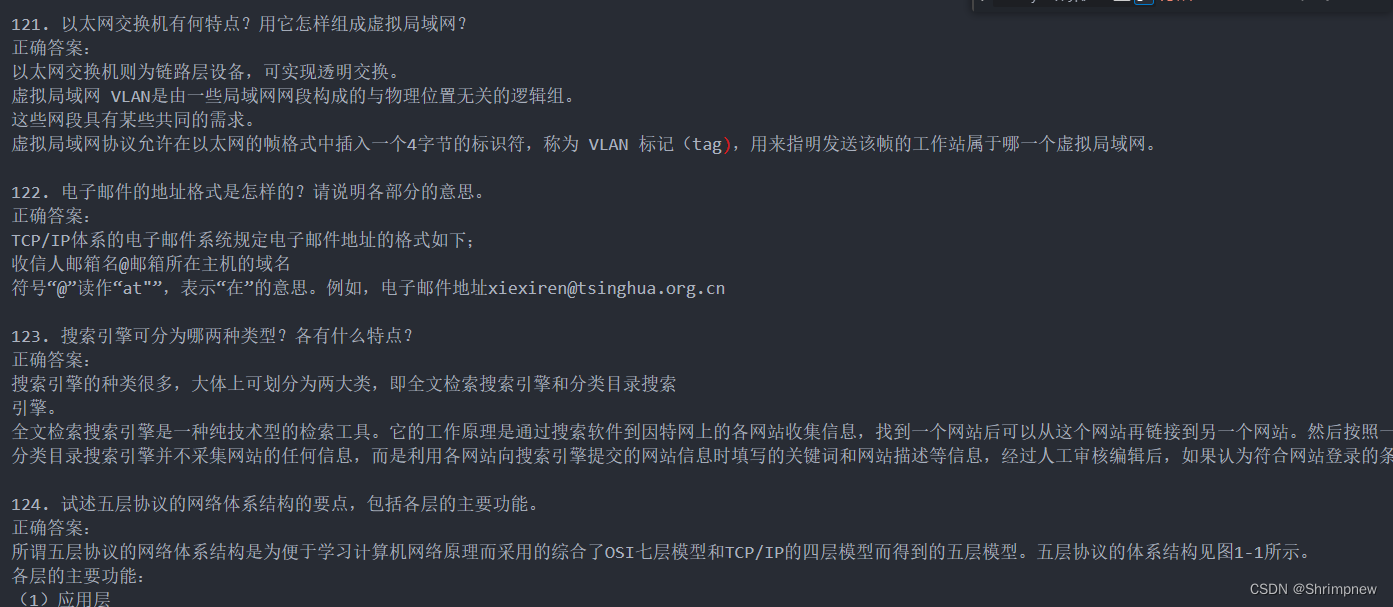
导入数据库之前需要经过以下步骤
3.1.1 将文本格式化,进行清洗,转为json格式
- 打开文件:以只读模式打开
./datasets/problems/answer.txt文件,编码为utf-8。 - 初始化变量:
problems列表,用于存储所有题目信息。problem_text和answer_text字符串,分别用于暂存题目和答案文本。is_answer布尔值,用于标识当前行是否为答案部分。
- 逐行读取文件:
- 遇到空行,表示一个题目的结束,将题目和答案添加到
problems列表中,并重置变量。 - 遇到包含“正确答案:”的行,设置
is_answer为True。 - 根据
is_answer的值,将当前行文本分别添加到answer_text或problem_text中。
- 遇到空行,表示一个题目的结束,将题目和答案添加到
- 打印结果:输出提取到的题目列表。
- 保存为JSON:将
problems列表以JSON格式写入./datasets/problems/answer.json文件中。
import json
def solve_choice():
f_in = open("./datasets/problems/choice.txt", "r", encoding="utf-8")
problems = []
problem_text = ""
answer_text = ""
for line in f_in:
if "正确答案:" in line:
problems.append({
"problem_text": problem_text.strip(),
"answer_text": line.strip(),
"problem_type": "choice"
})
problem_text = ""
answer_text = ""
else:
problem_text += line
print(problems)
out_f = open("./datasets/problems/choice.json", "w", encoding="utf-8")
out_f.write(json.dumps(problems, ensure_ascii=False))
def solve_judge():
f_in = open("./datasets/problems/judge.txt", "r", encoding="utf-8")
problems = []
problem_text = ""
answer_text = ""
for line in f_in:
if "正确答案:" in line:
pos = line.find("正确答案:")
problem_text = line[:pos]
answer_text = line[pos:]
problems.append({
"problem_text": problem_text.strip(),
"answer_text": answer_text.strip(),
"problem_type": "judge"
})
problem_text = ""
answer_text = ""
print(problems)
out_f = open("./datasets/problems/judge.json", "w", encoding="utf-8")
out_f.write(json.dumps(problems, ensure_ascii=False))
def solve_answer():
f_in = open("./datasets/problems/answer.txt", "r", encoding="utf-8")
problems = []
problem_text = ""
answer_text = ""
is_answer = False
for line in f_in:
if len(line.strip()) == 0:
problems.append({
"problem_text": problem_text.strip(),
"answer_text": answer_text.strip(),
"problem_type": "answer"
})
problem_text = ""
answer_text = ""
is_answer = False
elif "正确答案:" in line:
is_answer = True
if is_answer:
answer_text += line
else:
problem_text += line
print(problems)
out_f = open("./datasets/problems/answer.json", "w", encoding="utf-8")
out_f.write(json.dumps(problems, ensure_ascii=False))
solve_answer()格式化效果

3.1.2 将json题目进行汇总,为题目编号,统计题目与图谱节点的关系
读取实体和题目数据,将题目与包含的实体进行关联,统计每个实体在各个题目中的出现次数,并最终将这些数据保存为JSON格式。
1. 数据读取
步骤
- 读取实体数据:
- 打开
./datasets/entities.json文件,并使用json.load加载JSON数据,存储在entities变量中。
- 打开
- 初始化题目列表:
- 定义一个题目文件路径
problem_path和题目文件名列表problem_files,包括选择题、判断题和简答题。 - 初始化一个空列表
problems用于存储所有题目信息。
- 定义一个题目文件路径
- 读取题目数据:
- 逐个打开每个题目文件(
choice.json、judge.json、answer.json),并使用json.load加载JSON数据。 - 为每个题目分配一个唯一的
problem_id,并添加到problems列表中。
- 逐个打开每个题目文件(
2. 统计实体在题目中的出现次数
步骤
- 初始化实体计数字典:
- 创建一个字典
entity_counts,键为实体名称,值为一个defaultdict,用于存储该实体在不同题目中的出现次数。
- 创建一个字典
- 统计出现次数:
- 遍历所有题目,逐个检查每个实体是否出现在题目的文本和答案中。
- 如果实体名称在题目文本或答案中出现,则在
entity_counts字典中记录该实体在对应题目中的出现次数。
3. 对统计结果进行排序
步骤
- 排序:
- 创建一个字典
sorted_entity_counts,对entity_counts中的每个实体,按照在题目中的出现次数进行排序。
- 创建一个字典
4. 结果输出
步骤
- 组织输出数据:
- 创建一个字典
output,包含以下三个部分:entities:所有实体的名称列表。problems:所有题目的详细信息列表。entity_problem_counts:实体在题目中的出现次数统计结果,按出现次数排序。
- 创建一个字典
- 保存为JSON文件:
- 将
output字典以JSON格式写入entity2problem.json文件中。
- 将
import json
import os
from collections import defaultdict
with open('./datasets/entities.json', 'r', encoding='utf-8') as f:
entities = json.load(f)
problem_path = "./datasets/problems/"
problem_files = ["choice", "judge", "answer"]
problems = []
for problem_file in problem_files:
with open(problem_path + problem_file + ".json", 'r', encoding='utf-8') as f:
problem_data = json.load(f)
for problem in problem_data:
problem['problem_id'] = len(problems) + 1 # 给每个problem分配唯一的problem_id
problems.append(problem)
entity_counts = {entity['name']: defaultdict(int) for entity in entities}
for problem in problems:
for entity in entities:
entity_name = entity['name']
count = problem['problem_text'].count(entity_name) + problem['answer_text'].count(entity_name)
if count > 0:
entity_counts[entity_name][problem['problem_id']] += count
sorted_entity_counts = {
entity_name: sorted(problem_counts.items(), key=lambda x: x[1], reverse=True)
for entity_name, problem_counts in entity_counts.items()
}
output = {
'entities': [entity['name'] for entity in entities],
'problems': problems,
'entity_problem_counts': sorted_entity_counts
}
with open(problem_path + 'entity2problem.json', 'w', encoding='utf-8') as f:
json.dump(output, f, ensure_ascii=False, indent=4)
print("finished!")
编号和统计结果



3.1.3 将题目导入数据库
def create_problem(tx, problem):
query = (
"MERGE (p:Problem {problem_id: $problem_id, problem_type: $problem_type, problem_text: $problem_text, answer_text: $answer_text}) "
)
tx.run(
query,
problem_id= problem['problem_id'],
problem_type=problem['problem_type'],
problem_text=problem['problem_text'],
answer_text=problem['answer_text']
)导入效果
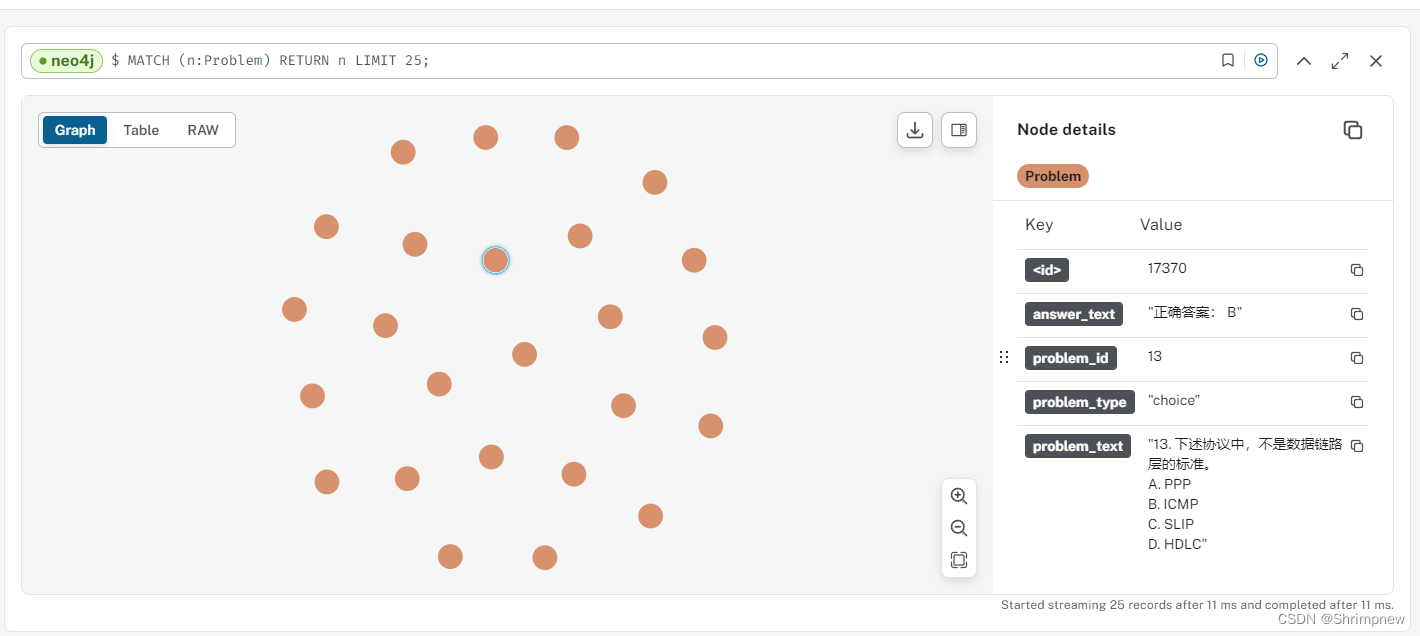
3.1.4 将节点按照相关性强弱向题目进行连接
将实体和题目的关联数据导入到Neo4j数据库中
1. 数据读取和数据库连接
-
数据库连接:
- 定义连接到Neo4j数据库的URI、用户名和密码。
- 使用
GraphDatabase.driver方法创建数据库驱动driver,以便与Neo4j数据库进行通信。
-
读取JSON文件:
- 打开并读取
./datasets/problems/entity2problem.json文件,使用json.load将文件内容加载为Python字典,存储在file_json变量中。 - 提取
entities、problems和entity_problem_counts三个关键部分的数据。
- 打开并读取
2. 创建题目节点
- 定义创建题目节点的函数:
create_problem(tx, problem):使用Cypher查询创建题目节点Problem,节点包含problem_id、problem_type、problem_text和answer_text四个属性。- 使用
MERGE语句确保节点的唯一性,即如果节点不存在则创建,已存在则不重复创建。
3. 创建实体与题目的关联关系
- 定义创建关联关系的函数:
create_exercise_relation(tx, entity_name, problem_id, weight):使用Cypher查询创建实体Entity和题目Problem之间的关系Exercise,关系包含weight属性,表示实体在题目中出现的次数。- 使用
MERGE语句确保节点和关系的唯一性。
4. 导入数据
-
定义数据导入的函数:
import_data(driver, entities, problems, entity_problem_counts):使用Neo4j数据库驱动driver开启会话,通过事务将数据写入数据库。- 遍历所有题目数据,调用
create_problem函数创建题目节点。 - 遍历所有实体数据,调用
create_exercise_relation函数创建实体与题目的关联关系。
-
执行数据导入:
- 调用
import_data函数,将entities、problems和entity_problem_counts三个部分的数据导入Neo4j数据库。
- 调用
-
关闭数据库连接:
- 调用
driver.close()关闭数据库连接。
- 调用
import json
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
username = "neo4j"
password = "11111111"
driver = GraphDatabase.driver(uri, auth=(username, password))
with open("./datasets/problems/entity2problem.json", "r", encoding="utf-8") as f:
file_json = json.load(f)
entities = file_json['entities']
problems = file_json['problems']
entity_problem_counts = file_json['entity_problem_counts']
def create_problem(tx, problem):
query = (
"MERGE (p:Problem {problem_id: $problem_id, problem_type: $problem_type, problem_text: $problem_text, answer_text: $answer_text}) "
)
tx.run(
query,
problem_id= problem['problem_id'],
problem_type=problem['problem_type'],
problem_text=problem['problem_text'],
answer_text=problem['answer_text']
)
def create_exercise_relation(tx, entity_name, problem_id, weight):
query = (
"MERGE (e:Entity {name: $entity_name}) "
"WITH e "
"MATCH (p:Problem {problem_id: $problem_id})"
"MERGE (e)-[:Exercise {weight: $weight}]->(p)"
)
tx.run(query, entity_name=entity_name, problem_id=problem_id, weight=weight)
def import_data(driver, entities, problems, entity_problem_counts):
with driver.session() as session:
for problem in problems:
session.write_transaction(create_problem, problem)
for entity in entities:
if entity in entity_problem_counts.keys() and len(entity_problem_counts[entity]) > 0:
for link in entity_problem_counts[entity]:
session.write_transaction(create_exercise_relation, entity, link[0], link[1])
import_data(driver, entities, problems, entity_problem_counts)
driver.close()
题目关系连接效果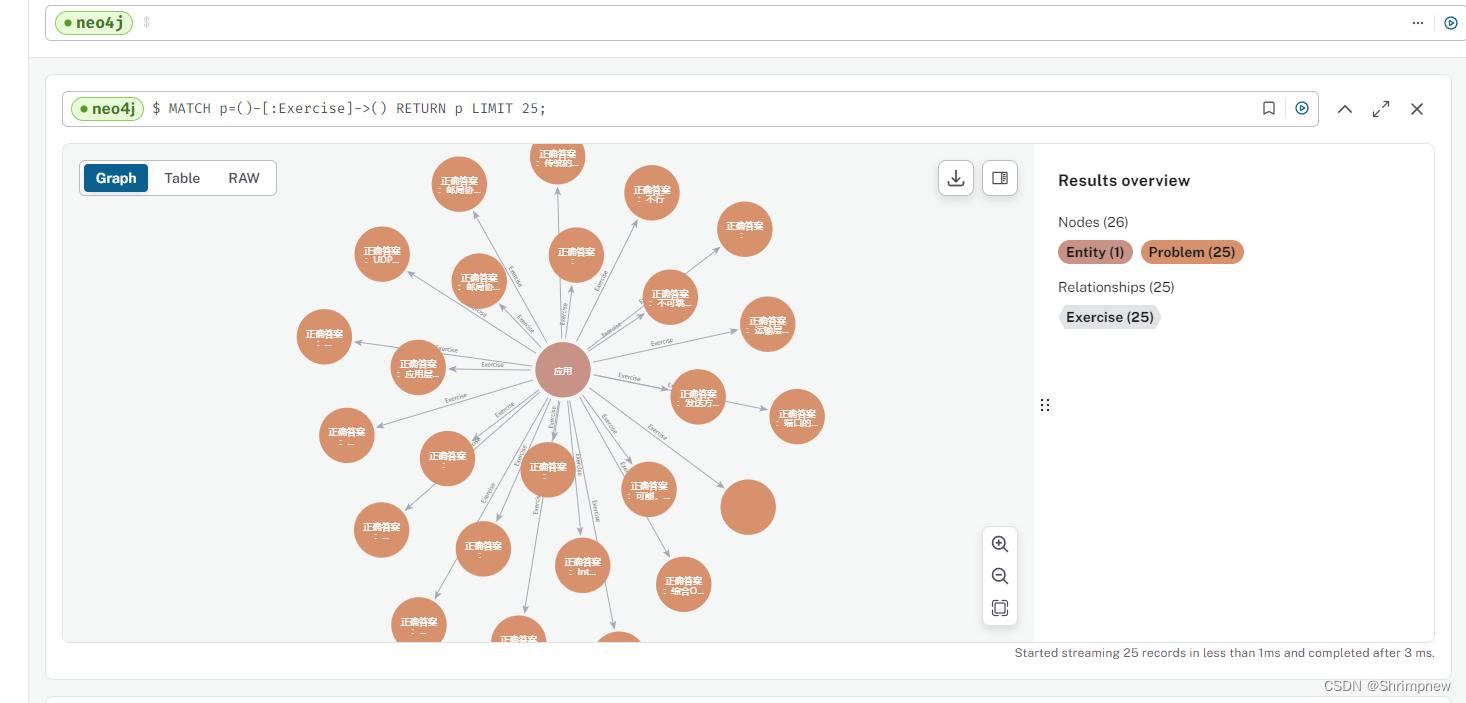















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









