






2024.5.19 可视化方面的探索
结合前端的需求,我需要将爬取的文档和关系数据进行一定的格式转化以便于可视化展示。
知识图谱数据格式转换
1. 概述
该工作主要功能是处理一个包含文档标题和实体名称的 JSON 文件,生成一个包含节点(文档标题)和边(文档标题与实体名称关系)的知识图谱(KG)。生成的知识图谱按特定类别(如物理层、数据链路层等)进行分类,并将结果输出到一个 JSON 文件中。
2. 代码功能简介
代码执行以下主要任务:
- 从输入的 JSON 文件中读取数据。
- 创建节点和边,并构建一个图结构。
- 按照预定义的类别对节点进行分类。
- 将处理后的图结构数据存储到一个 JSON 文件中。
3. 数据格式转换分析
输入数据格式
输入数据来自一个名为 computer_network_mentions_with_title.json 的文件,其中每行是一个 JSON 对象,包含以下字段:
doc_title: 文档标题entity_name: 实体名称
输出数据格式
输出是一个 JSON 对象,包含以下结构:
categories: 节点类别列表nodes: 节点列表,每个节点包含名称、值和类别links: 边列表,每个边包含源节点和目标节点
4. 实现思路
- 初始化类别和数据结构:首先定义类别列表,并初始化存储节点、节点ID映射、图结构和边的相关数据结构。
- 读取并解析输入文件:逐行读取输入文件,将每个文档标题和实体名称映射到节点和边的数据结构中。
- 构建图结构:根据文档标题和实体名称的关系构建图结构,并记录每个文档标题的实体名称。
- 分类节点:基于预定义的类别,通过广度优先搜索(BFS)方法,将相关节点进行分类,并构建节点之间的边。
- 输出结果:将最终构建的图结构数据写入到一个 JSON 文件中。
读取并解析输入文件
f = open('./computer_network_mentions_with_title.json', 'r', encoding='utf-8')
last_title = ''
for line in f:
item = json.loads(line)
if item['doc_title'] not in nodes_id.keys():
nodes_id[item['doc_title']] = len(nodes)
nodes.append({
"name": item['doc_title'],
"value": 1,
"category": 7
})
graph[item['doc_title']] = []
edges.append((item['doc_title'], item['entity_name']))
graph[item['doc_title']].append(item['entity_name'])
if len(nodes) == 1000:
break
- 打开输入文件,逐行读取并解析为 JSON 对象。
- 对每个文档标题,检查是否已经在
nodes_id中,如不存在则添加到nodes和nodes_id中,并初始化graph字典。 - 添加文档标题与实体名称的关系到
edges列表和graph字典中。 - 当节点数量达到 1000 时,停止读取。
构建图结构
for id, categorie in enumerate(tqdm(categories)):
now_title = categorie['name']
max_dis = 2
que = [(now_title, 0)]
vis = set()
now = 0
while now < len(que):
now_title, now_dis = que[now]
now += 1
if now_title in nodes_id.keys():
nodes[nodes_id[now_title]]['category'] = id
if now_dis < max_dis:
if now_title in graph.keys():
for new_title in graph[now_title]:
if new_title not in vis:
que.append([new_title, now_dis + 1])
vis.add(new_title)
if now_title in nodes_id.keys() and new_title in nodes_id.keys():
links.append({
"source": nodes_id[now_title],
"target": nodes_id[new_title]
})
- 使用广度优先搜索(BFS)方法,从每个类别的名称开始,遍历其相关的文档标题和实体名称,将节点分类并构建边。
max_dis参数限制了搜索深度,确保仅搜索与类别名称相关的节点及其直接连接的节点。
输出结果
kg = {
"categories": categories,
"nodes": nodes,
"links": links
}
out_f = open("./kg_by_category.json", 'w', encoding='utf-8')
out_f.write(json.dumps(kg, ensure_ascii=False))
- 构建最终的知识图谱数据结构,包括
categories、nodes和links。 - 将知识图谱数据写入到
kg_by_category.json文件中。
实现效果
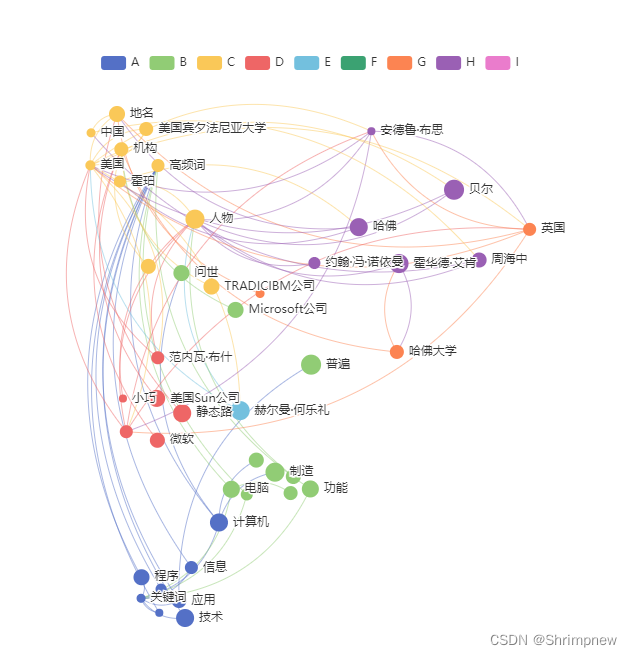
章节实体数目统计
1. 初始化部分
代码首先初始化了几个变量和数据结构:
categories:一个包含了各个网络层级及其他分类的列表。nodes:用于存储所有的文档节点。nodes_id:用于记录文档节点的唯一ID。graph:用于存储文档节点之间的关系。edges、links:用于存储文档节点与实体之间的边和链接关系。
categories = [
{"name": "物理层", "keyword": {}, "base": "物理层"},
{"name": "数据链路层", "keyword": {}, "base": "数据链路层"},
{"name": "介质访问控制", "keyword": {}, "base": "介质访问控制"},
{"name": "网络层", "keyword": {}, "base": "网络层"},
{"name": "传输层", "keyword": {}, "base": "传输层"},
{"name": "应用层", "keyword": {}, "base": "应用层"},
{"name": "其他", "keyword": {}, "base": "其他"}
]
nodes = []
nodes_id = {}
graph = {}
edges = []
links = []
2. 读取文件并构建图结构
代码从文件./computer_network_mentions_with_title.json中读取数据,并构建文档节点和实体之间的关系图:
- 如果文档标题不在
nodes_id中,则将其添加到nodes列表和nodes_id字典中。 - 更新
graph字典以记录文档节点与实体节点的关系。 - 构建
edges列表来记录文档与实体之间的边。
f = open('./computer_network_mentions_with_title.json', 'r', encoding='utf-8')
for line in f:
item = json.loads(line)
if item['doc_title'] not in nodes_id.keys():
nodes_id[item['doc_title']] = len(nodes)
nodes.append({
"name": item['doc_title'],
"value": 1,
"category": 7
})
graph[item['doc_title']] = []
edges.append((item['doc_title'], item['entity_name']))
graph[item['doc_title']].append(item['entity_name'])
if len(nodes) == 1000:
break
3. 统计章节相关实体数量
接下来,代码按章节统计了相关实体的数量:
- 遍历每一个章节
categories,对每一个章节进行广度优先搜索(BFS),以统计与该章节相关的实体数量。 - 对每一个章节的实体节点进行遍历,记录访问过的节点,并更新节点类别。
- 在遍历过程中,记录章节与实体节点之间的链接关系。
data = []
for id, categorie in enumerate(tqdm(categories)):
now_title = categorie['name']
max_dis = 2
que = [(now_title, 0)]
vis = set()
now = 0
sum = 0
while now < len(que):
now_title, now_dis = que[now]
now += 1
sum += 1
if now_title in nodes_id.keys():
nodes[nodes_id[now_title]]['category'] = id
if now_dis < max_dis:
if now_title in graph.keys():
for new_title in graph[now_title]:
if new_title not in vis:
que.append([new_title, now_dis + 1])
vis.add(new_title)
if now_title in nodes_id.keys() and new_title in nodes_id.keys():
links.append({
"source": nodes_id[now_title],
"target": nodes_id[new_title]
})
data.append({
'value': sum,
'name': categorie['name']
})
4. 输出结果
最后,代码将统计结果输出到文件./chapter_statistics.json中,以JSON格式保存:
out_f = open("./chapter_statistics.json", 'w', encoding='utf-8')
out_f.write(json.dumps(data, ensure_ascii=False))
5.效果
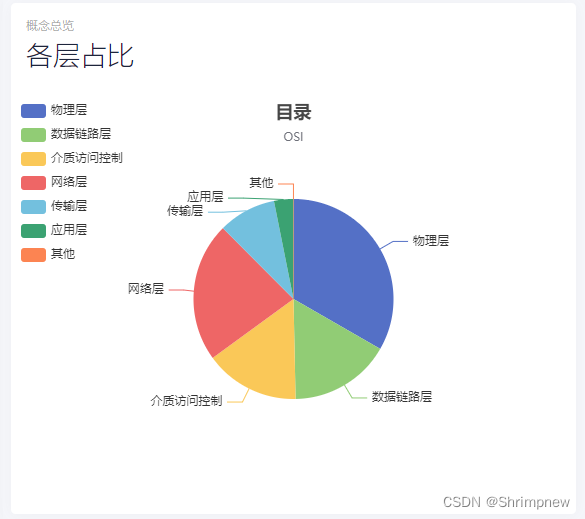
章节关系建模
1. 初始化部分
代码首先初始化了几个变量和数据结构:
categories:一个包含了各个网络层级及其他分类的列表。nodes:用于存储所有的文档节点。nodes_id:用于记录文档节点的唯一ID。graph:用于存储文档节点之间的关系。edges、links:用于存储文档节点与实体之间的边和链接关系。
categories = [
{"name": "物理层", "keyword": {}, "base": "物理层"},
{"name": "数据链路层", "keyword": {}, "base": "数据链路层"},
{"name": "介质访问控制", "keyword": {}, "base": "介质访问控制"},
{"name": "网络层", "keyword": {}, "base": "网络层"},
{"name": "传输层", "keyword": {}, "base": "传输层"},
{"name": "应用层", "keyword": {}, "base": "应用层"},
{"name": "其他", "keyword": {}, "base": "其他"}
]
nodes = []
nodes_id = {}
graph = {}
edges = []
links = []
2. 读取文件并构建图结构
代码从文件./computer_network_mentions_with_title.json中读取数据,并构建文档节点和实体之间的关系图:
- 如果文档标题不在
nodes_id中,则将其添加到nodes列表和nodes_id字典中。 - 更新
graph字典以记录文档节点与实体节点的关系。 - 构建
edges列表来记录文档与实体之间的边。
f = open('./computer_network_mentions_with_title.json', 'r', encoding='utf-8')
for line in f:
item = json.loads(line)
if item['doc_title'] not in nodes_id.keys():
nodes_id[item['doc_title']] = len(nodes)
nodes.append({
"name": item['doc_title'],
"value": 1,
"category": 7
})
graph[item['doc_title']] = []
edges.append((item['doc_title'], item['entity_name']))
graph[item['doc_title']].append(item['entity_name'])
if len(nodes) == 1000:
break
3. 过滤和连接章节节点
代码通过广度优先搜索(BFS)对章节节点间的关系进行过滤和连接:
- 遍历每一个章节
categories,对每一个章节进行广度优先搜索,以统计与该章节相关的实体节点。 - 对每一个章节的实体节点进行遍历,记录访问过的节点,并更新节点类别。
- 在遍历过程中,记录章节与实体节点之间的链接关系。
for id, categorie in enumerate(tqdm(categories)):
now_title = categorie['name']
max_dis = 2
que = [(now_title, 0)]
vis = set()
vis.add(now_title)
now = 0
while now < len(que):
now_title, now_dis = que[now]
now += 1
if now_title in nodes_id.keys():
nodes[nodes_id[now_title]]['category'] = id
if now_dis < max_dis:
if now_title in graph.keys():
for new_title in graph[now_title]:
if new_title not in vis:
que.append([new_title, now_dis + 1])
vis.add(new_title)
if now_title in nodes_id.keys() and new_title in nodes_id.keys():
links.append({
"source": nodes_id[now_title],
"target": nodes_id[new_title]
})
4. 输出结果
最后,代码将构建的知识图谱(包括节点、链接和分类信息)输出到文件./kg_by_category.json中,以JSON格式保存:
kg = {
"categories": categories,
"nodes": nodes,
"links": links
}
out_f = open("./kg_by_category.json", 'w', encoding='utf-8')
out_f.write(json.dumps(kg, ensure_ascii=False))
5. 结果

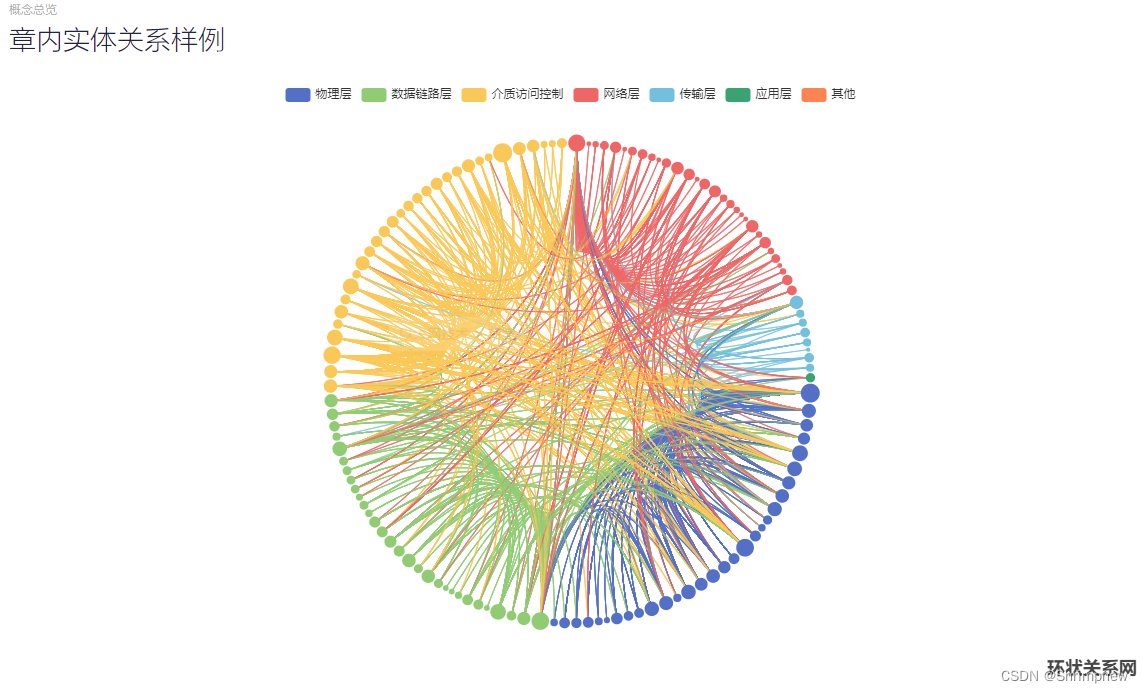
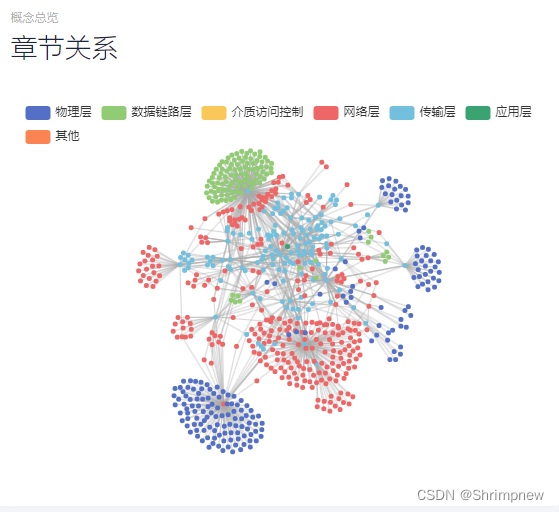
树形结构的可视化
概述
读取一个包含文档标题和实体名称的 JSON 文件,将其转换成树形结构的数据,并将每个文档标题及其子树结构存储到单独的 JSON 文件中。输出的 JSON 文件适用于可视化工具,如 d3.js,用于展示树形结构图。
主要任务
- 读取并解析输入 JSON 文件。
- 维护一个顺序列表
order和一个字典sons,记录每个文档标题及其关联的实体名称。 - 生成树形结构数据。
- 将树形结构数据保存到单独的 JSON 文件中,每个文件对应一个文档标题。
数据格式转换分析
输入数据格式
输入数据来自一个名为 computer_network_mentions_with_title.json 的文件,其中每行是一个 JSON 对象,包含 doc_title 和 entity_name。
输出数据格式
输出是树形结构的 JSON 对象,每个对象包含 name、size、children 和 value 属性。输出文件以 id.json 命名存储在 tree_data 目录中。
实现思路
- 初始化必要的数据结构。
- 读取输入文件并解析数据,将每个文档标题和其关联的实体名称存储到
order和sons中。 - 按照预定义的规则生成树形结构数据。
- 将每个文档标题及其树形结构数据存储到单独的 JSON 文件中。
生成树形结构数据
id = 0
for fa in order:
item = {
"name": '',
"size": 0,
"children": [],
"value": 0
}
fasize = 0
for s1 in sons[fa]:
if len(item['children']) == 10:
break
if s1 in sons.keys():
s1item = {
"name": '',
"size": 0,
"children": [],
"value": 0
}
s1size = 0
for s2 in sons[s1]:
if len(s1item['children']) == 10:
break
if s2 in sons.keys():
s2item = {}
s2size = random.randrange(1, 100)
s1size += s2size
s2item['name'] = s2
s2item['size'] = s2size
s2item['value'] = s2size
s1item['children'].append(s2item)
s1item['name'] = s1
s1item['size'] = s1size
s1item['value'] = s1size
fasize += s1size
item['children'].append(s1item)
item['name'] = fa
item['size'] = fasize
item['value'] = fasize
out_f = open("./tree_data/" + str(id) + ".json", "w", encoding='utf-8')
out_f.write(json.dumps(item, ensure_ascii=False))
id += 1
print(id)
if id == 2000:
break
- 初始化
id计数器。 - 对于每个文档标题
fa,创建一个包含name、size、children和value的空字典item。 - 对于每个与文档标题关联的实体名称
s1,如果它也是一个文档标题,则创建一个类似的字典s1item。 - 对于每个与
s1关联的实体名称s2,生成一个随机大小s2size,并将其添加到s1item的children中。 - 更新
s1item的size和value,并将其添加到item的children中。 - 更新
item的size和value,并将其写入到一个以id命名的 JSON 文件中。
数据展示
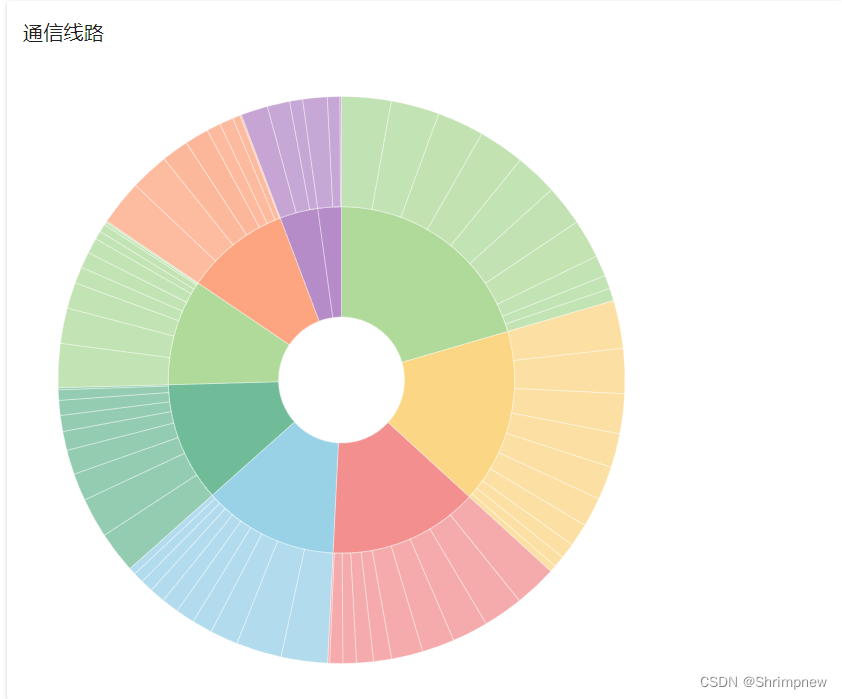
{"name": "计算机网络", "size": 5290, "children": [{"name": "地理位置", "size": 604, "children": [{"name": "地理事物", "size": 67, "value": 67}, {"name": "空间关系", "size": 58, "value": 58}, {"name": "确定", "size": 46, "value": 46}, {"name": "经纬度", "size": 83, "value": 83}, {"name": "经济地理位置", "size": 65, "value": 65}, {"name": "地理事物", "size": 99, "value": 99}, {"name": "空间关系", "size": 43, "value": 43}, {"name": "测绘科学与技术", "size": 81, "value": 81}, {"name": "地理事物", "size": 43, "value": 43}, {"name": "定性", "size": 19, "value": 19}], "value": 604}, {"name": "外部设备", "size": 543, "children": [{"name": "外设", "size": 9, "value": 9}, {"name": "输出设备", "size": 76, "value": 76}, {"name": "外存储器", "size": 78, "value": 78}, {"name": "作用", "size": 73, "value": 73}, {"name": "外围设备", "size": 72, "value": 72}, {"name": "主机", "size": 1, "value": 1}, {"name": "设备", "size": 49, "value": 49}, {"name": "系统", "size": 20, "value": 20}, {"name": "外设", "size": 99, "value": 99}, {"name": "计算机硬件", "size": 66, "value": 66}], "value": 543}, {"name": "通信线路", "size": 547, "children": [{"name": "有线通信", "size": 4, "value": 4}, {"name": "传输媒介", "size": 99, "value": 99}, {"name": "巴尔的摩", "size": 37, "value": 37}, {"name": "英吉利海峡", "size": 94, "value": 94}, {"name": "海底电缆", "size": 68, "value": 68}, {"name": "海底电缆", "size": 87, "value": 87}, {"name": "丹麦大北电报公司", "size": 44, "value": 44}, {"name": "多模光纤", "size": 68, "value": 68}, {"name": "单模光纤", "size": 3, "value": 3}, {"name": "传输媒介", "size": 43, "value": 43}], "value": 547}, {"name": "网络操作系统", "size": 515, "children": [{"name": "计算机", "size": 95, "value": 95}, {"name": "操作系统", "size": 4, "value": 4}, {"name": "服务器", "size": 49, "value": 49}, {"name": "客户端", "size": 26, "value": 26}, {"name": "服务器", "size": 63, "value": 63}, {"name": "资源", "size": 62, "value": 62}, {"name": "计算机", "size": 31, "value": 31}, {"name": "NOS", "size": 90, "value": 90}, {"name": "工作站", "size": 64, "value": 64}, {"name": "单用户操作系统", "size": 31, "value": 31}], "value": 515}, {"name": "网络管理软件", "size": 573, "children": [{"name": "网络管理", "size": 67, "value": 67}, {"name": "支撑软件", "size": 93, "value": 93}, {"name": "网络设备", "size": 22, "value": 22}, {"name": "网络系统", "size": 53, "value": 53}, {"name": "体系结构", "size": 13, "value": 13}, {"name": "应用程序", "size": 79, "value": 79}, {"name": "网络搜索", "size": 45, "value": 45}, {"name": "Windows NT", "size": 18, "value": 18}, {"name": "网络管理软件", "size": 93, "value": 93}, {"name": "网络管理协议", "size": 90, "value": 90}], "value": 573}, {"name": "网络通信协议", "size": 736, "children": [{"name": "操作系统", "size": 85, "value": 85}, {"name": "体系结构", "size": 84, "value": 84}, {"name": "互联网络", "size": 54, "value": 54}, {"name": "网络", "size": 81, "value": 81}, {"name": "操作系统", "size": 54, "value": 54}, {"name": "体系结构", "size": 90, "value": 90}, {"name": "互联网络", "size": 82, "value": 82}, {"name": "TCP/IP", "size": 86, "value": 86}, {"name": "传输控制协议", "size": 55, "value": 55}, {"name": "网际协议", "size": 65, "value": 65}], "value": 736}, {"name": "资源共享", "size": 437, "children": [{"name": "计算机", "size": 46, "value": 46}, {"name": "操作系统", "size": 53, "value": 53}, {"name": "共享空间", "size": 38, "value": 38}, {"name": "局域网", "size": 61, "value": 61}, {"name": "打印服务器", "size": 84, "value": 84}, {"name": "邮件服务器", "size": 66, "value": 66}, {"name": "局域网", "size": 28, "value": 28}, {"name": "集中存储", "size": 7, "value": 7}, {"name": "网络存储", "size": 47, "value": 47}, {"name": "工作组", "size": 7, "value": 7}], "value": 437}, {"name": "信息传递", "size": 407, "children": [{"name": "现代化管理", "size": 58, "value": 58}, {"name": "电码", "size": 66, "value": 66}, {"name": "购买行为", "size": 6, "value": 6}, {"name": "销售管理", "size": 21, "value": 21}, {"name": "商品信息", "size": 38, "value": 38}, {"name": "购买行为", "size": 32, "value": 32}, {"name": "信息管理", "size": 38, "value": 38}, {"name": "信息活动", "size": 64, "value": 64}, {"name": "有机体", "size": 31, "value": 31}, {"name": "主体要素", "size": 53, "value": 53}], "value": 407}, {"name": "计算机系统", "size": 354, "children": [{"name": "存储信息", "size": 53, "value": 53}, {"name": "结果信息", "size": 21, "value": 21}, {"name": "计算机", "size": 4, "value": 4}, {"name": "硬件", "size": 18, "value": 18}, {"name": "软件", "size": 27, "value": 27}, {"name": "中央处理机", "size": 62, "value": 62}, {"name": "存储器", "size": 61, "value": 61}, {"name": "外部设备", "size": 12, "value": 12}, {"name": "系统软件", "size": 83, "value": 83}, {"name": "应用软件", "size": 13, "value": 13}], "value": 354}, {"name": "计算机通信网", "size": 574, "children": [{"name": "通信设备", "size": 86, "value": 86}, {"name": "数据传输", "size": 58, "value": 58}, {"name": "领域", "size": 87, "value": 87}, {"name": "条件", "size": 76, "value": 76}, {"name": "通信技术", "size": 6, "value": 6}, {"name": "微电子", "size": 86, "value": 86}, {"name": "数据传输", "size": 19, "value": 19}, {"name": "处理器", "size": 50, "value": 50}, {"name": "功能", "size": 10, "value": 10}, {"name": "资源共享", "size": 96, "value": 96}], "value": 574}], "value": 5290}
实现结果
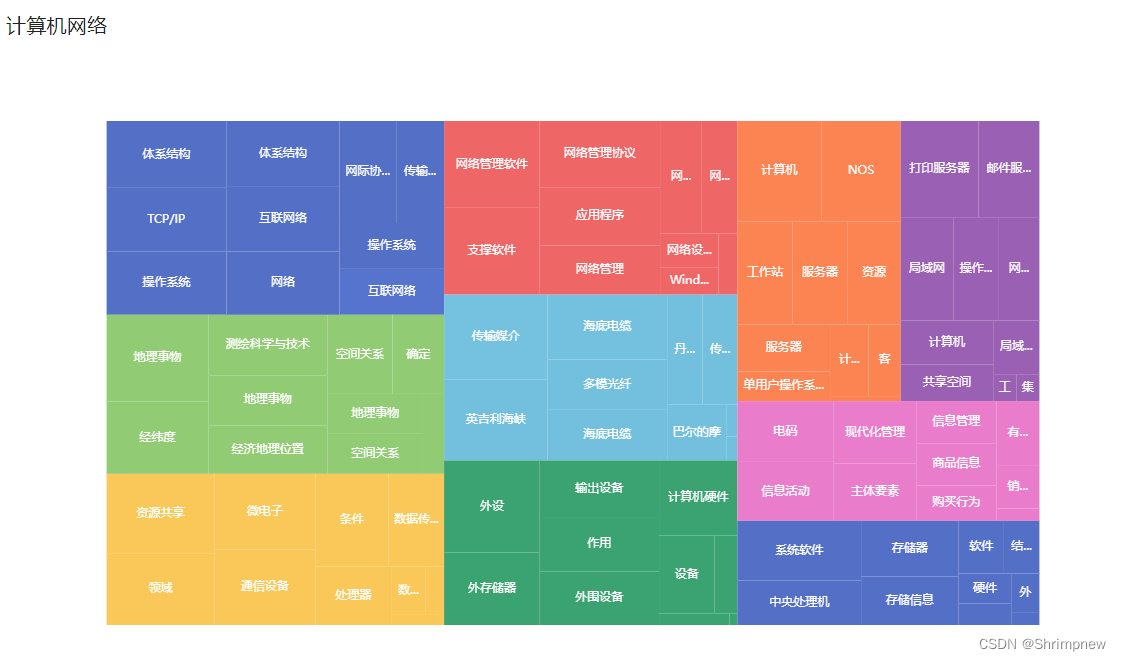















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









