







目录
知识图谱初探:定义、发展与应用简介
知识图谱(Knowledge Graph)是近年来备受关注的数据组织和应用技术,它将复杂的信息以图的形式呈现,帮助人们更好地理解和利用数据。本文将从知识图谱的定义开始,逐步深入到其发展历程、实现方法、应用场景等。
1. 什么是知识图谱?
知识图谱是一种将数据组织成**实体(Entity)和它们之间关系(Relationship)**的图结构。实体可以是现实世界中的人、地点、组织、概念等,而关系则描述了这些实体之间的连接,比如“位于”、“属于”、“是”等。这种结构使得数据不仅可以被存储,还可以被理解和分析,从而支持更智能的应用。
简单示例
假设我们有一个知识图谱,其中包含“北京”、“中国”、“首都”这三个实体。它们之间的关系可以是“北京 是 中国的 首都”。在图中:
- “北京”和“中国”是实体节点;
- “首都”是连接它们的边(关系)。
核心优势
知识图谱能够捕捉现实世界中的复杂信息,提供数据的语义上下文,使得机器能够“理解”数据背后的含义,而不仅仅是处理孤立的文本或数字。例如,搜索“苹果”时,知识图谱可以帮助判断用户指的是水果还是公司,并提供相应的信息。
2. 知识图谱的发展历程
知识图谱的概念并非凭空出现,它经历了从学术研究到广泛应用的发展过程。
早期阶段
- 20世纪70年代:知识图谱的起源可以追溯到**语义网络(Semantic Network)和本体论(Ontology)**的研究,这些技术旨在为计算机提供一种理解和推理数据的方式。
- 1985年:WordNet的创立标志着知识图谱在语言学领域的应用,它为英语单词提供了语义关系网络。
突破性进展
- 2012年:谷歌推出了自己的知识图谱(Google Knowledge Graph),这标志着知识图谱进入主流视野。谷歌通过整合全球范围内的数据,提升了搜索结果的准确性和上下文相关性。例如,搜索“爱因斯坦”时,不仅返回他的生平,还能展示他的成就、相关人物等。
- 后续发展:微软的Bing、Facebook和LinkedIn等公司也纷纷推出了自己的知识图谱项目,推动了技术在商业领域的普及。
当前趋势
近年来,随着人工智能和机器学习的发展,知识图谱的应用范围不断扩展,尤其在自然语言处理(NLP)、推荐系统和智能问答等领域取得了显著进展。
3. 知识图谱的实现方法
构建知识图谱是一个复杂的过程,通常包括以下几个关键步骤:
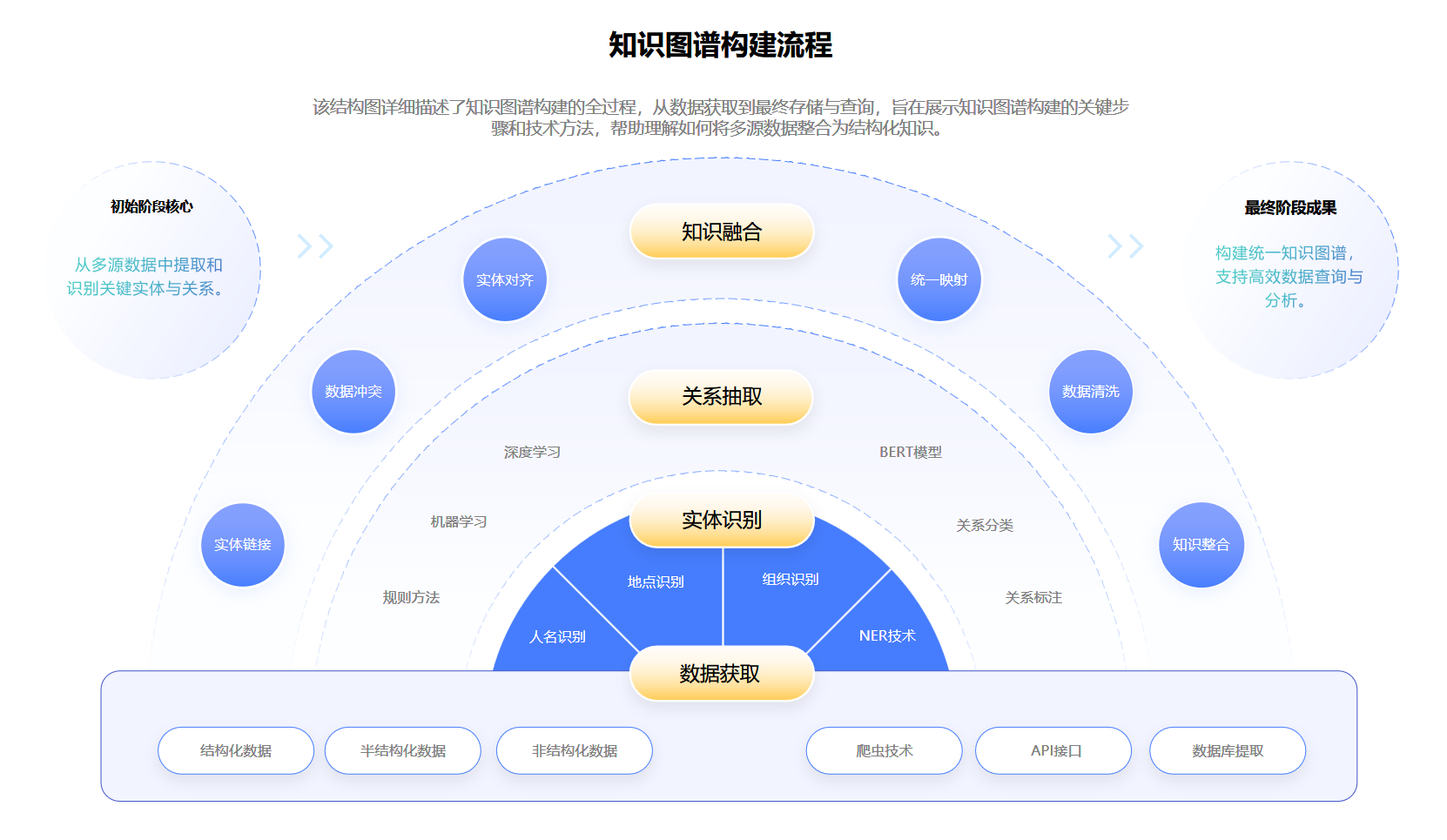
3.1 数据获取
- 来源:数据可以来自结构化数据库(如SQL数据库)、半结构化数据(如JSON、XML)以及非结构化数据(如网页、文档)。
- 方法:通过爬虫、API接口或直接从数据库中提取数据。
3.2 实体识别
- 目的:从文本中识别出实体,如人名、地点、组织等。
- 技术:使用自然语言处理(NLP)技术,如命名实体识别(NER)。
3.3 关系抽取
- 目的:识别实体之间的关系,如“工作于”、“位于”等。
- 技术:基于规则的方法、机器学习模型(如BERT)或深度学习技术。
3.4 知识融合
- 目的:将从不同来源获取的数据整合到统一的知识图谱中,解决实体对齐和数据冲突问题。例如,“Peking”和“Beijing”需要被识别为同一个实体。
- 方法:使用**实体链接(Entity Linking)**技术,将不同来源的实体映射到同一实体上。
3.5 存储与查询
- 存储:使用图数据库(如Neo4j、JanusGraph)存储知识图谱,支持高效的图遍历和查询。
- 查询:使用查询语言(如Cypher、SPARQL)进行数据的检索和分析。
4. 知识图谱的应用场景
知识图谱在多个领域都有广泛的应用,以下是几个典型场景:
| 应用场景 | 描述 | 示例 |
|---|---|---|
| 搜索引擎 | 利用知识图谱提供更准确和上下文相关的搜索结果,帮助用户快速获取所需信息。 | 谷歌搜索“北京”时,展示关于北京的地理、历史、文化等多方面的信息。 |
| 推荐系统 | 通过分析用户行为和实体之间的关系,增强推荐系统的个性化能力。 | Netflix使用知识图谱推荐用户可能感兴趣的电影或电视剧。 |
| 智能问答 | 为智能问答系统提供丰富的知识库,使系统能够理解用户问题并提供准确答案。 | 苹果的Siri和亚马逊的Alexa依赖知识图谱回答用户查询。 |
| 风险管理 | 在金融和保险行业,帮助识别潜在的风险和欺诈行为,通过分析实体之间的复杂关系发现异常模式。 | 银行使用知识图谱检测洗钱行为。 |
| 生物医学 | 整合和分析大量生物数据,帮助研究人员发现新的药物靶点或理解疾病机制。 | 研究人员使用知识图谱探索基因与疾病之间的关系。 |
5. 知识图谱的开源项目排名
开源项目为知识图谱的开发和应用提供了重要的支持。以下是一些知名的开源知识图谱项目及其特点:
| 项目名称 | 描述 | 特点 |
|---|---|---|
| Neo4j | 一个流行的图数据库,支持知识图谱的存储和查询。 | 易于使用,提供了强大的查询语言Cypher,适合构建和分析知识图谱。 |
| JanusGraph | 一个可扩展的图数据库,支持大规模知识图谱的存储和处理。 | 支持多机集群,适用于处理海量数据。 |
| DBpedia | 从维基百科中提取结构化信息的项目,提供了大量关于人、地点、组织等的知识。 | 数据量大,覆盖面广,是许多知识图谱应用的基石。 |
| Wikidata | 维基媒体基金会的一个项目,旨在为维基百科等项目提供结构化数据。 | 社区驱动,数据更新频繁,支持多语言。 |
| YAGO | 一个大规模的知识图谱,整合了维基百科、GeoNames和WordNet等数据源。 | 数据质量高,提供了丰富的实体和关系信息。 |
| GeoNames | 一个地理信息数据库,包含了全球数百万个地理实体的信息。 | 专注于地理数据,支持多种语言和格式。 |
| WordNet | 英语词汇的语义网络,提供了单词之间的同义、反义等关系。 | 在自然语言处理领域应用广泛,常用于增强搜索和NLP应用。 |
6. 总结
知识图谱作为一种强大的数据组织和应用技术,正在改变我们处理和理解数据的方式。从搜索引擎到推荐系统,从智能问答到风险管理,知识图谱的应用场景不断扩展。随着技术的进步和开源项目的支持,知识图谱的构建和应用将变得更加高效和普及。

















 8534
8534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









