







前沿
-
目标检测任务关注的是图片中特定目标物体的位置。一个检测任务包含两个子任务,其一是输出这一目标的类别信息,属于分类任务;其二是输出目标的具体位置信息,属于定位任务。类比我们去摘草莓,找到草莓和草莓的位置。
-
物体在图像中的位置信息(矩形框的坐标值表示, X m i n 、 Y m i n 、 X m a x 、 Y m a x Xmin、Ymin、Xmax、Ymax Xmin、Ymin、Xmax、Ymax), X m i n 、 Y m i n Xmin、Ymin Xmin、Ymin 左上角, X m a x 、 Y m a x Xmax、Ymax Xmax、Ymax 右下角。
-
物体的中心点可以根据坐标值计算得到,中心点 ( X m i n + ( X m a x − X m i n ) / 2 , Y m i n + ( Y m a x − Y m i n ) / 2 ) ( Xmin + (Xmax - Xmin)/2 , Ymin + (Ymax - Ymin)/2 ) (Xmin+(Xmax−Xmin)/2,Ymin+(Ymax−Ymin)/2)

早期,传统目标检测算法还没有使用深度学习,一般分为三个阶段:区域选取(找到物体的位置)、特征提取(描述物体的特征,特征类比苹果与西瓜的颜色与形状,苹果:小小的红色椭圆,西瓜:大大的绿色椭圆)、特征分类(看见小小的红色椭圆,知道是苹果;看见大大的绿色椭圆,知道是西瓜)。
- 区域选取:采用滑动窗口(Sliding Windows)算法(可以想象一个窗口在图像从左到右,从上到下,框出图像内容),选取图像中可能出现物体的位置,这种算法会存在大量冗余框,并且计算复杂度高。
- 特征提取:通过手工设计的特征提取器(如SIFT和HOG等)进行特征提取。
- 特征分类:使用分类器(如SVM)对上一步提取的特征进行分类。
YOLO 的算法流程
以下适合有深度学习基础的读者
YOLO v1 是深度学习的方法,可以看成黑盒子,输入一张图片,输出图中物体类别信息和物体的位置。
为什么网络能输出物体的类别信息和物体的位置呢?这里需要了解网络的输出是什么样子的?

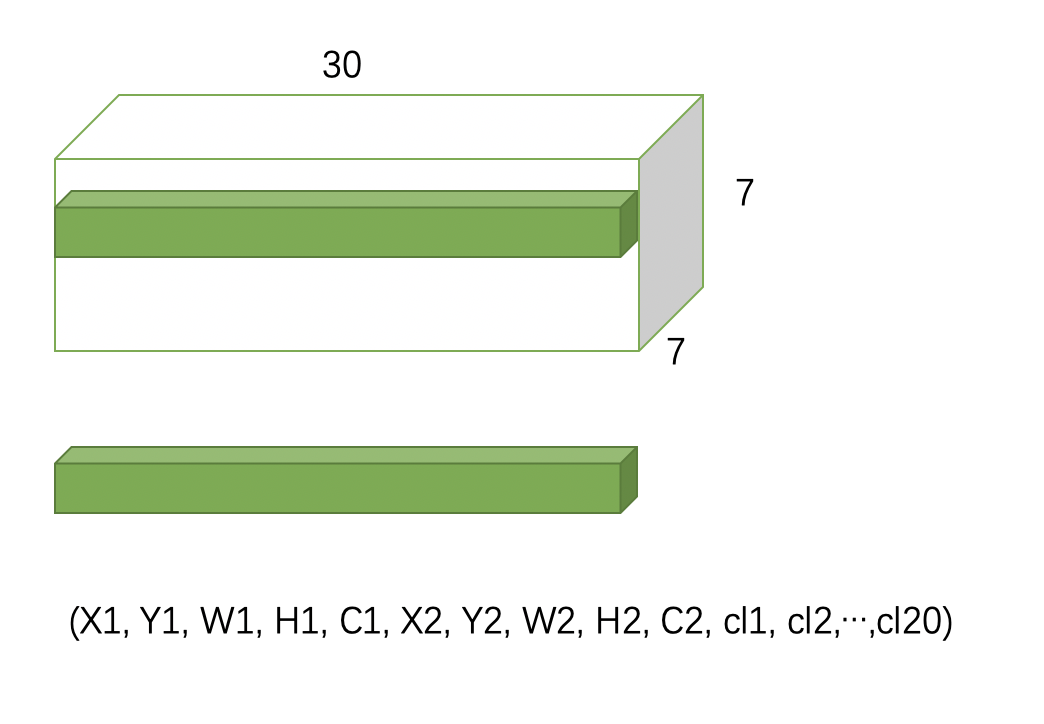
网络输出的张量尺寸为 7 × 7 × 30 7×7×30 7×7×30
S × S × ( 5 × B + C ) S\times S\times(5\times B + C) S×S×(5×B+C)
S = 7 , B = 2 , C = 20 S = 7,B = 2,C = 20 S=7,B=2,C=20
- 7 × 7 7×7 7×7 是最后的特征图化为 7 × 7 7×7 7×7 grid cell.
- 每个grid cell 里有 2个 bounding boxes [简称bbox],生成 x , y , w , h x , y, w, h x,y,w,h , x , y x , y x,y是物体中心点坐标, w , h w, h w,h是 bbox 的长宽。
- 每个bbox有包含物体的概率 c o n f i d e n c e confidence confidence。
- Each grid cell predicts
B
B
B(
B
=
2
B = 2
B=2) bounding boxes and confidence scores for those boxes.
- define
c
o
n
f
i
d
e
n
c
e
confidence
confidence as
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object) ∗ IOU^{truth}_{pred}
Pr(Object)∗IOUpredtruth
- I O U p r e d t r u t h IOU^{truth}_{pred} IOUpredtruth 指网络生成的bbox框和GT标注bbox计算IOU值(两个框的重叠率)。
- 不包含物体: If no object exists in that cell, the c o n f i d e n c e confidence confidence scores should be zero. = > P r ( O b j e c t ) = 0 Pr(Object) = 0 Pr(Object)=0
- 包含物体:Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box and the ground truth. = > P r ( O b j e c t ) = 1 Pr(Object) = 1 Pr(Object)=1
- define
c
o
n
f
i
d
e
n
c
e
confidence
confidence as
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object) ∗ IOU^{truth}_{pred}
Pr(Object)∗IOUpredtruth
- C C C是类别概率,根据这个可以得到物体的类别标签 ,在YOLO v1论文中,使用VOC的数据集,有20个类别。实际在代码里还有一个背景类,不包含物体的情况下,confidence = 0,是背景类。
一个网络能学习预测物体类别和物体位置,这就要看损失函数了~
Loss Function
损失函数包含三个部分:(1)2.1 中心点、宽、高;(2)2.2 置信度;(3)2.3 物体的类别标签
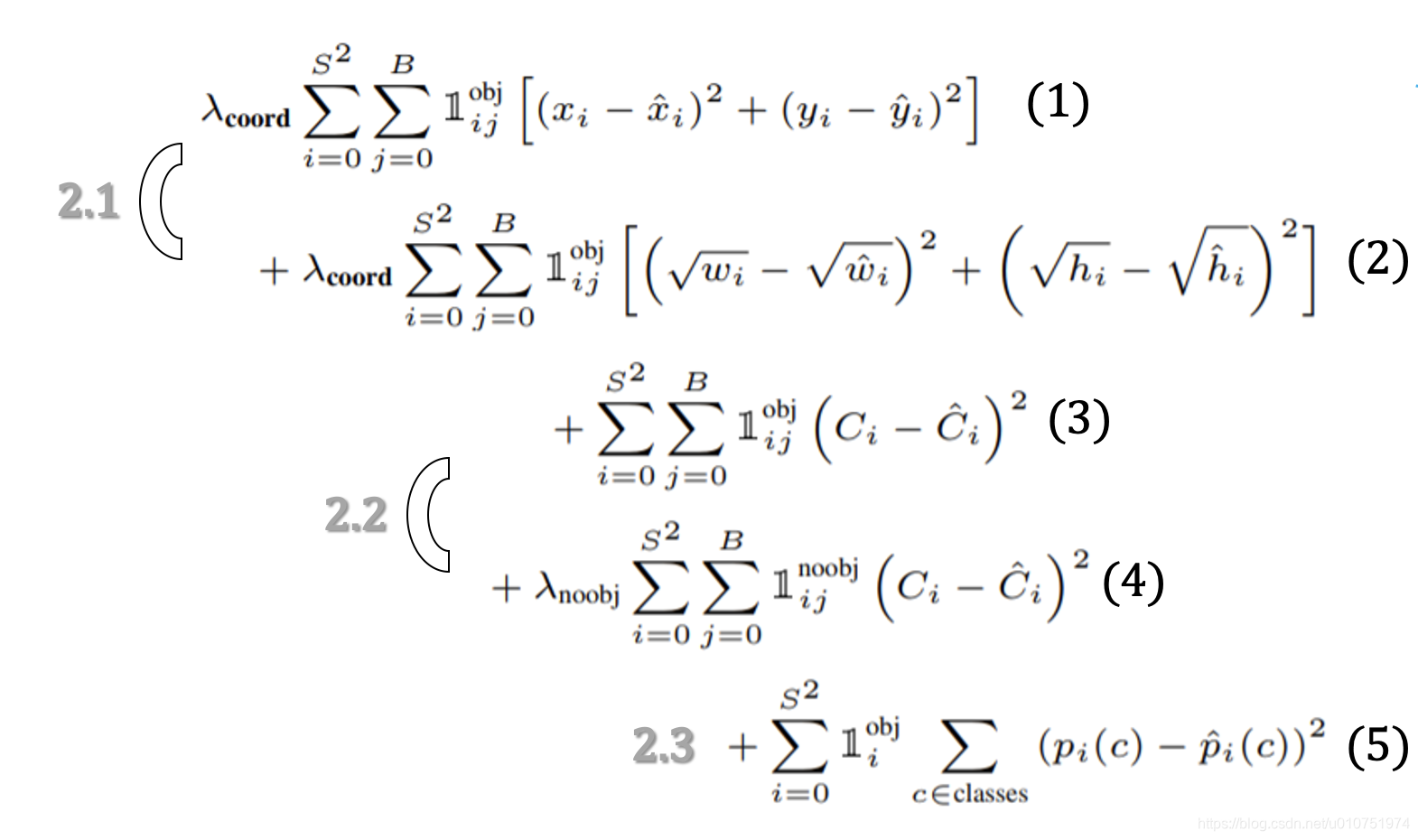
损失函数三个部分的细节分别了解一下
2.1 中心点、宽、高的损失计算
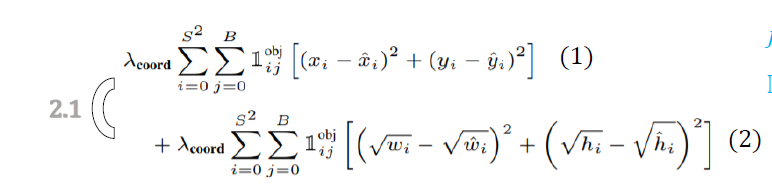
- x , y x,y x,y: predicated bbox center, w , h w,h w,h: predicated bbox width & height
- x ^ , y ^ \hat{x}, \hat{y} x^,y^: labeled bbox center, w ^ , h ^ \hat{w}, \hat{h} w^,h^ : labeled bbox width & height
- w , h \sqrt{w},\sqrt{h} w,h: Suppress the effect for larger bbox ==> 物体大,宽变化大、物体小,变化小,抑制之后,两者变化区别不大
-
i : 0 − ( S 2 − 1 ) i:0 -(S^2-1) i:0−(S2−1) [iterate each grid cell ( 0 − 48 0-48 0−48)]
-
j : 0 − ( B − 1 ) j:0-(B-1) j:0−(B−1) [iterate each bbox ( 0 − 1 ) (0 - 1) (0−1)]
2.2 置信度的损失计算
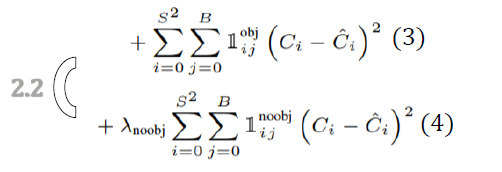
C i ^ \hat{C_i} Ci^: confidence score [IoU] of predicated and labeled bbox
C i ^ \hat{C_i} Ci^进一步翻译: 网络生成的 x , y , w , h x,y,w,h x,y,w,h 与 label的 x ^ , y ^ , w ^ , h ^ \hat{x}, \hat{y},\hat{w}, \hat{h} x^,y^,w^,h^计算IOU
C i C_i Ci : predicated confidence score [IoU] generated from networks

-
此图中的Test: 公式来源论文,代码中,网络直接生成confidence的值。
- l i j o b j l_{ij}^{obj} lijobj 指正样本,类似mask, 例如下面的表格, 正样本的位置为1, C i = = 1 C_i == 1 Ci==1
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
- l i j n o o b j l_{ij}^{noobj} lijnoobj 指负样本,类似 mask, 例如下面的表格,负样本的位置为1。 C i = = 0 C_i == 0 Ci==0
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
- For l i j o b j l_{ij}^{obj} lijobj, we have B B B predictions in each cell, only the one with largest IoU shall be labeled as 1,另一个bbox一般设置为noobj,如果另一个bbox与GT的IOU过大(例如0.65),可以不加入noobj,不参与计算。
2.3 物体的类别标签,损失计算
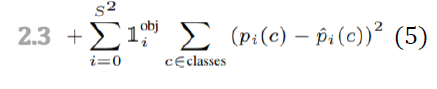
Each cell will only predict 1 object, which is decided by the bbox with largest IoU
这里给一个思考题:如果两个物体很近,物体的中心点也靠的很近,标签会标两个物体还是一个物体呢?这个主要看代码的实现,以下代码是一个。
for box in boxes:
class_label, x, y, width, height = box.tolist()
class_label = int(class_label)
# i,j represents the cell row and cell column
i, j = int(self.S * y), int(self.S * x)
x_cell, y_cell = self.S * x - j, self.S * y - i
"""
Calculating the width and height of cell of bounding box,
relative to the cell is done by the following, with
width as the example:
width_pixels = (width*self.image_width)
cell_pixels = (self.image_width)
Then to find the width relative to the cell is simply:
width_pixels/cell_pixels, simplification leads to the
formulas below.
"""
width_cell, height_cell = (
width * self.S,
height * self.S,
)
# If no object already found for specific cell i,j
# Note: This means we restrict to ONE object
# per cell!
if label_matrix[i, j, 20] == 0:
# Set that there exists an object
label_matrix[i, j, 20] = 1
# Box coordinates
box_coordinates = torch.tensor(
[x_cell, y_cell, width_cell, height_cell]
)
label_matrix[i, j, 21:25] = box_coordinates
# Set one hot encoding for class_label
label_matrix[i, j, class_label] = 1
return image, label_matrix
这里代码只会标注一个














 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









