






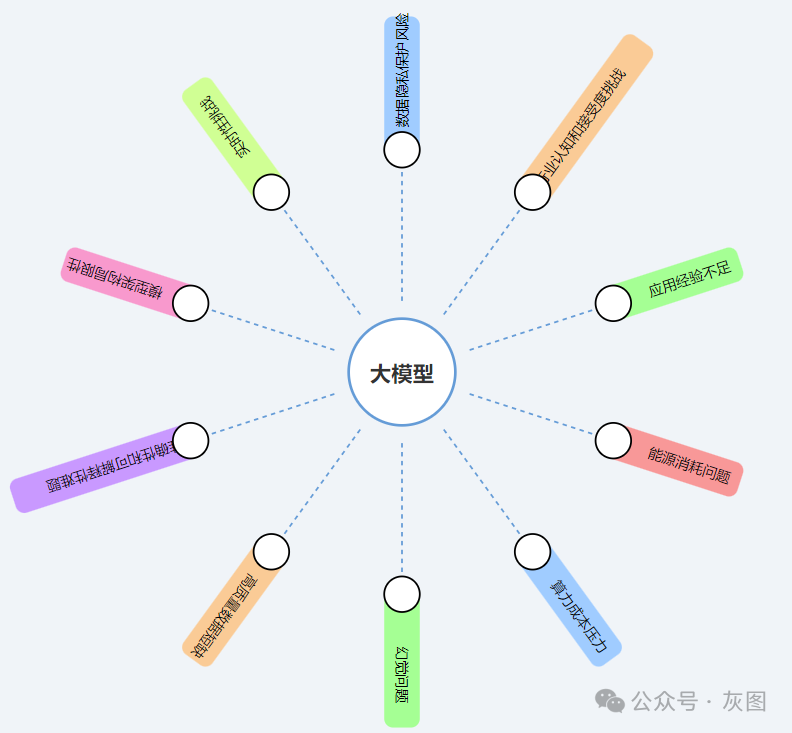
一、数据大模型的风险挑战
1. 能源消耗问题
事实描述:训练大型AI模型需要消耗大量电力资源,尤其是当模型参数规模扩大时,能源成本显著上升。根据斯坦福人工智能研究所的数据,像GPT-3这样的大型语言模型单次训练耗电量可达1287兆瓦时,相当于3000辆特斯拉电动汽车行驶20万英里所消耗的电量。这种高能耗不仅增加了经济负担,还对环境造成了负面影响,如增加碳排放。
实例:某科技公司为训练一个新的人工智能模型支付了相当于一个月运行3000辆电动汽车的电费,这不仅让公司的财务部门头疼,也引起了对公司环保责任的关注。
2. 算力成本压力
事实描述:大型AI模型依赖于强大的计算能力,导致算力成本高昂,占据了运营成本的主要部分。例如,OpenAI预计在2024年可能面临高达50亿美元的亏损,其中超过八成的成本来自算力消耗。
实例:一家云端游戏平台发现,仅维持现有服务每年就要花费数亿美元在云计算资源上,迫使管理层重新评估业务模式的可持续性。
3. 幻觉问题
事实描述:大型AI模型有时会产生与现实不符的信息,即“幻觉”。这些错误源于数据集偏见、训练缺陷或推理逻辑失误,损害了系统的可信度,并可能导致误导性信息传播,甚至引发法律和伦理风险。
实例:用户询问:“秦始皇为什么喜欢用苹果手机?”未充分训练的AI可能会一本正经地回答,给出看似合理但完全不切实际的答案,如“因为苹果手机帮助他更好地管理国家事务”。
4. 高质量数据短缺
事实描述:高质量文本数据逐渐被采集殆尽,这对机器学习模型构成了威胁。权威研究机构预测,到2028年,互联网上的优质文本数据将被采集完毕,而合成数据的应用虽然可以缓解这一问题,但也可能引入新的偏差。
实例:一家医疗初创企业在开发癌症早期检测系统时,发现可用的高质量标注数据非常有限,阻碍了项目的进展,影响了算法的效果。
5. 准确性和可解释性难题
事实描述:大模型的“黑箱”特性使得决策过程不透明,影响用户信任。特别是在医疗和金融等关键领域,需要确保输出结果既准确又易于解释,以满足合规性和伦理要求。
实例:在线理财平台上,AI提供的投资建议如果无法解释其决策过程,用户很难完全信任这些建议,从而影响他们对该平台的信任。
6. 模型架构局限性
事实描述:基于现有架构(如Transformer)的大规模语言模型面临诸多限制,包括对计算资源的巨大需求以及能效比不佳等问题,限制了模型的可扩展性和实时处理能力。
实例:智能家居系统中使用的复杂AI模型,在处理语音命令时由于过于庞大,响应时间过长,降低了用户体验,并可能在紧急情况下带来安全隐患。
7. 实时性挑战
事实描述:自动驾驶汽车和高频股票交易等领域要求大模型具备高数据处理速度和低延迟。任何延迟都可能导致安全风险或经济损失。
实例:提供无人机快递服务的企业,若其无人机不能及时处理传感器数据并做出决策,可能会导致安全事故,影响配送效率和服务质量。
8. 数据隐私保护风险
事实描述:大模型在数据安全和隐私保护方面面临多种风险,如数据泄露、滥用等。特别是在云端训练过程中,数据传输和存储的安全性尤为重要。
实例:三星员工在使用ChatGPT时发生了信息泄漏事故,员工要求聊天机器人检查敏感数据库源代码是否有错误,导致信息存在泄露风险。
9. 行业认知和接受度挑战
事实描述:行业专家和决策者对新技术的理解不足,加之对变革的抵抗,以及高成本和效益不确定性,尤其是在金融和医疗等关键领域,使得大模型的推广面临障碍。
实例:金融机构可能对大模型的安全性和准确性存有疑虑,担心其会导致金融风险,因此对新技术持谨慎态度。
10. 应用经验不足
事实描述:集成现有系统难、探索新场景不确定、用户接受度问题等构成了大模型应用经验不足的挑战。此外,成本效益评估难度、专业人才短缺、法规适应性等因素也增加了应用的复杂性。
实例:企业在尝试将大模型集成到现有系统时遇到了技术难题,而用户对于新模型的接受度也存在不确定性,如一些用户对AI助手提供的建议持怀疑态度。
二、数据大模型的风险评估
1. 数据采集、处理阶段的风险治理
为了降低数据采集和处理阶段的风险,可以采取以下措施:
数据分类与保护:通过分类明确不同类型数据的敏感程度和保护要求。
数据脱敏:对敏感数据进行处理,使其在不影响数据可用性的前提下,降低泄露风险。例如,可以对个人身份信息、金融数据等敏感数据进行脱敏处理,防止非法获取。
2. 大模型敏感信息的泄露检测和风险评估
(1)安全合规需求
各国法规对敏感信息处理提出了严格要求,如美国的《格雷姆 - 里奇 - 比利雷法》(GLBA)、《加州消费者隐私法案》(CCPA),欧盟的《通用数据保护条例》(GDPR),英国的《数据保护法案》(DPA)等,规范了从收集到使用的各个环节。我国也有相关法律和《生成式人工智能服务管理暂行办法》,旨在保障用户的隐私和个人信息安全。
(2)泄露检测和风险评估方案
敏感信息来源标识:追溯敏感信息的来源,确认是否存在泄露潜在可能。
敏感信息分类分级:根据数据安全法规要求,对不同来源信息进行全面审查,标识并分类敏感信息。
敏感信息泄露检测:采用先进的检测技术和监测系统来实时监控敏感信息流动,检测泄露迹象。
敏感信息风险评估:制定综合的风险评估模型,结合敏感信息的来源、分类、分级和泄露概率等因素,评估风险并提出应对措施。
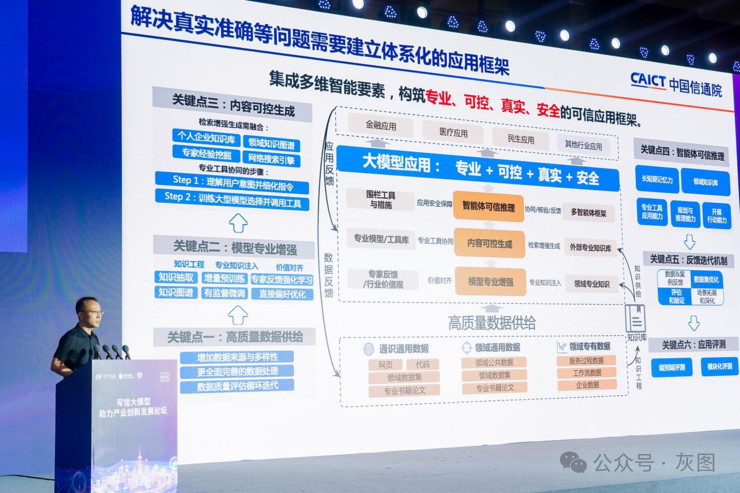
三、数据大模型的能力成熟度评估
1. 数据资源成熟度
数据采集:评估大模型训练、推理过程中数据采集能力,支持结构化和非结构化的数据格式,如文本、图片、音频、视频等。
数据存储:确保数据的安全性和可访问性,选择合适的存储方式,如文件系统、关系型数据库、NoSQL数据库或云存储服务。
数据管理:建立完善的数据管理体系,支持数据分类、分级,以及数据集的创建、查询、修改、删除等操作。
数据应用:建立完善的数据质量管理体系、数据安全体系,实现数据分析结果反馈回业务系统。
数据审查:建立严格的数据审查机制,确保数据的准确性、完整性和一致性。
数据来源:确保数据来源的多样性和可靠性,注意合法性和隐私问题。
数据模态:支持多种数据模态,如文本、图像、语音等,提高模型泛化能力和准确性。
数据分布:确保数据在不同领域、主题、场景中的均衡分布,避免数据偏差。
数据质量:确保数据的准确性、完整性、一致性和时效性,避免低质量数据影响模型性能。
2. 应用服务成熟度
行业技术服务:为不同行业提供技术服务,加速智能化升级,如金融领域的风险评估和投资决策、医疗领域的疾病诊断和治疗建议、教育领域的个性化学习和智能辅导等。
微调方式:评估大模型能否支持多种微调方式,如全量微调、PEFT中的高效微调方式等,提升特定领域的能力。
模型协同:实现大小模型的优势互补,提高整体应用效果,如先利用大模型进行初步处理,再利用小模型进行精细调整。
部署方式:支持多种环境的灵活部署方式,如API和SDK、主流的云服务平台等,满足不同用户需求。
运营管理:评估大模型系统的流程化、自动化及持续闭环能力,支持监控模型性能、资源消耗等,提高稳定性和可靠性。
四、数据大模型的分类分级
1. 使用大模型进行数据分类分级的方法
大模型的能力:利用大模型的强大逻辑分析能力直接用于数据分类,如对医疗数据进行分类时输出JSON格式。
Prompt增强:把分类标准直接告诉大模型,让其按需分类,如使用“think step by step”指定处理步骤。
指令微调:准备微调数据集,简化Prompt,提高分类准确率。
更复杂的形式:结合各种手段不断强化能力,取得更好的分类效果,如从数据源收集数据、使用特定领域数据进行微调或小样本学习等。
2. 大模型时代公共数据分类分级治理
数据安全风险新变化:从文本数据到多模态数据,从静态保护到数据全生命周期,从单一主体到多元主体,数据安全管控形势严峻。
推动公共数据分类分级治理的路径选择:制度上兼顾数据安全和发展;管理上建立多方联动机制;技术上创新智能分类分级方法,建设公共训练数据资源平台,提供安全、可信的数据清洗、加工环境。
3. 大模型的分类方式
按任务类型分类:分为生成式模型、判别式模型和混合模型。
按数据模态分类:分为单模态模型和多模态模型。
按训练方法分类:分为预训练模型、从零训练模型和迁移学习模型。
按应用领域分类:分为自然语言处理、计算机视觉、语音处理等模型。
按模型架构分类:分为transformer架构、卷积神经网络、循环神经网络和长短期记忆网络。
展望大模型的未来
面对数据大模型带来的挑战,从能源消耗到隐私保护,我们需通过技术创新和政策引导来实现可持续发展。细致的风险评估、能力成熟度评估以及分类分级治理的应用,将帮助我们更科学地管理和优化这些模型,确保其高效与安全。
未来,节能减排的新技术和更高效的算法将缓解环境压力和计算资源需求,而建立健全的数据保护制度和跨部门协作机制,则能促进大模型的健康发展。我们应积极拥抱变化,坚守伦理底线,让大模型真正成为推动社会进步的强大工具,服务于人类的美好未来。

















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









