









符号表示
矩阵:A
转置矩阵:AT
逆矩阵:A-1
单位阵:E或者I
伴随矩阵:A*
行列式:|A|或det(A);主对角线乘积(多维时所有主向乘积相加) - 次对角线乘积(多维时所有次向乘积相加)
矩阵的秩:r(A),rk(A)或rank A
共轭矩阵:AH;虚部取负,如:i取为-i即可,实部不变
酉矩阵:U;UH=U-1
转换公式
将A的(i行j列)和(j行i列)互换得到AT,记作:(AT)ij=Aji
(A+B)T=AT+BT
(AB)T=BTAT
(AB)-1=B-1A-1
AA-1=A-1A=E
A* = |A|A-1
设 A 是n阶方阵,如果存在数m和非零n维列向量 x,使得 Ax=mx 成立,则称 m 是A的一个特征值(characteristic value)或本征值(eigenvalue)。
故Ax-mx=0=>(A-mE)x=0=>A-mE=0=>det(A-mE)=0
求解可得特征值m。
最小二乘法(二乘即平方)
如果误差是随机的,yi应该围绕真值y上下波动,误差记为 |y-yi| 。
所有误差的和最小时,最接近真实,而求绝对值的最小值比较麻烦,所以就使用平方 (y-yi)2最小来代替绝对值|y-yi|最小,因此得名最小二乘法。
误差 Σ(y-yi)2
===>二次函数的导数=0时,值最小
===>2Σ(y-yi)
===>2[(y-y1)+(y-y2)+…+(y-yi)]=0
===>ny-Σyi=0/2
===>y=Σyi/n
===>因此,yi的平均值就是最接近真实的值
假设回归方程为:y=ax+b
已知n对(xi,yi)
误差e2=(yi-y)2=Σ(yi-axi-b)2
那么对a和b分别求偏导,偏导等于0,可求得极值,有:
- 2Σ(yi-axi-b)*(-xi)=0
- 2Σ(yi-axi-b)*(-1) =0
求解可得a和b的值
ALS交替最小二乘法(协同过滤,常用于数据挖掘推荐系统)
ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面。
Am×n=Um×k × Vk×n (其中:k<<m,n)
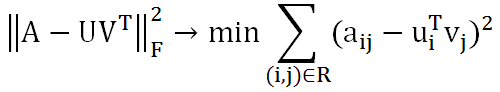
为什么计算函数最优值采用梯度下降算法而不是直接求导等于0的深度解释
https://blog.csdn.net/qq_41800366/article/details/86600893
代价函数如下时:
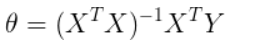
参数的结果给出两个信息,同时也是直接求导不可行的原因:
1、X的转置乘以X必须要可逆,也就是X必须可逆,但是实际情况中并不一定都满足这个条件,因此直接求导不可行;
2、假设满足了条件一,那么就需要去求X的转置乘以X这个整体的逆,线性代数中给出了求逆矩阵的方法,是非常复杂的(对计算机来说就是十分消耗性能的),数据量小时,还可行,一旦数据量大,计算机求矩阵的逆将会是一项非常艰巨的任务,消耗的性能以及时间巨大,而在机器学习中,数据量少者上千,多者上亿;
因此直接求导不可行。
相较而言,梯度下降算法同样能够实现最优化求解,通过多次迭代使得代价函数收敛,并且使用梯度下降的计算成本很低,所以基于以上两个原因,回归中多数采用梯度下降而不是求导等于零。
PCA主成分分析(降维)
PCA主成分分析原理详见:https://blog.csdn.net/program_developer/article/details/80632779


SVD奇异值分解(降维)
SVD奇异值分解原理详见:https://wenku.baidu.com/view/05a07e0069eae009581becf1.html
或:http://www.cnblogs.com/pinard/p/6251584.html
方阵的特征分解:n阶方阵A均可进行特征分解表示:
A=WΣW-1
特征分解推广:任意矩阵的特征分解:
Amxn=Umxm Σmxn Vnxn-T
对于奇异值,它跟特征分解中的特征值类似,在奇异值矩阵Σ中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。也就是说:
Amxn = Umxm Σmxn Vnxn-T ≈ Umxk Σkxk Vkxn-T
Σ 是由奇异值 i 的平方组成的对角阵
V 是 AT A的特征向量
U 是 AAT 的特征向量















 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









