






线性代数:
n维向量x乘以x的转置就是一个对称矩阵
矩阵转置时主对角的元素不变
矩阵乘法的计算规则如下图:
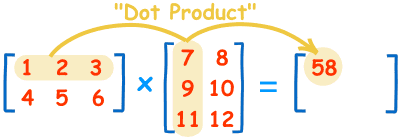
为什么是这样的计算规则,参考:Linear Algebra: What matrices actually are
Most high school students in the United States learn about matrices and matrix multiplication, but they often are not taught why matrix multiplication works the way it does. Adding matrices is easy: you just add the corresponding entries. However, matrix multiplication does not work this way, and for someone who doesn’t understand the theory behind matrices, this way of multiplying matrices may seem extremely contrived and strange. To truly understand matrices, we view them as representations of part of a bigger picture. Matrices represent functions between spaces, called vector spaces, and not just any functions either, but linear functions. This is in fact why linear algebra focuses on matrices. The two fundamental facts about matrices is that every matrix represents some linear function, and every linear function is represented by a matrix. Therefore, there is in fact a one-to-one correspondence between matrices and linear functions. We’ll show that multiplying matrices corresponds to composing the functions that they represent. Along the way, we’ll examine what matrices are good for and why linear algebra sprang up in the first place.
Most likely, if you’ve taken algebra in high school, you’ve seen something like the following:

Your high school algebra teacher probably told you this thing was a “matrix.” You then learned how to do things with matrices. For example, you can add two matrices, and the operation is fairly intuitive:

You can also subtract matrices, which works similarly. You can multiply a matrix by a number:

Then, when you were taught how to multiply matrices, everything seemed wrong:

That is, to find the entry in the 


")
")


How come matrix multiplication doesn’t work like addition and subtraction? And if multiplication works this way, how the heck does division work? The goal of this post is to answer these questions.
To understand why matrix multiplication works this way, it’s necessary to understand what matrices actually are. But before we get to that, let’s briefly take a look at why we care about matrices in the first place. The most basic application of matrices is solving systems of linear equations. A linear equation is one in which all the variables appear by themselves with no powers; they don’t get multiplied with each other or themselves, and no funny functions either. An example of a system of linear equations is

The solution to this system is 




If only we could find a matrix 


The applications of matrices reach far beyond this simple problem, but for now we’ll use this as our motivation. Let’s get back to understanding what matrices are. To understand matrices, we have to know what vectors are. A vector space is a set with a specific structure, and a vector is simply an element of the vector space. For now, for technical simplicity, we’ll stick with vector spaces over the real numbers, also known as real vector spaces. A real vector space is basically what you think of when you think of space. The number line is a 1-dimensional real vector space, the x-y plane is a 2-dimensional real vector space, 3-dimensional space is a 3-dimensional real vector space, and so on. If you learned about vectors in school, then you are probably familiar with thinking about them as arrows which you can add together, multiply by a real number, and so on, but multiplying vectors together works differently. Does this sound familiar? It should. That’s how matrices work, and it’s no coincidence.
The most important fact about vector spaces is that they always have a basis. A basis of a vector space is a set of vectors such that any vector in the space can be written as a linear combination of those basis vectors. If 


, (0,1)")
")

so we indeed have a basis! This is not the only possible basis. In fact, the vectors in our basis don’t even have to be perpendicular! For example, the vectors , (1,1)")
 \begin{pmatrix} 1 \\ 0 \end{pmatrix} + b \begin{pmatrix} 1 \\ 1 \end{pmatrix}")
Now, a linear transformation is simply a function between two vector spaces that happens to be linear. Being linear is an extremely nice property. A function 
 = f(x) + f(y) \\ f(ax) = af(x)")
For example, the function  = x^2")
 = (x+y)^2 = x^2 + y^2 + 2xy")
 + f(y) = x^2 + y^2")


 = f(av_1 + bv_2 + cv_3) = af(v_1) + bf(v_2) + cf(v_3).")
Notice that the value of ")
, f(v_2), f(v_3)")


, v_2 = (0,1,0), v_3 = (0,0,1)")
, w_2 = (0,1)")


 = 2w_1 + 4w_2 \\ f(v_2) = w_1 - w_2 \\ f(v_3) = w_2.")
Then the corresponding matrix will be

The reason why this works is that matrix multiplication was designed so that if you multiply a matrix by the vector with all zeroes except a 1 in the  = Mx + My")
 = aMx")


Now, finally to answer the question posed at the beginning. Why does matrix multiplication work the way it does? Let’s take a look at the two matrices we had in the beginning: 



)")

) = f(w_1 + w_2) = f(w_1) + f(w_2) \\ = (2w_1 + 4w_2) + (w_1 + 3w_2) = 3w_1 + 7w_2")
so the first column of ")
) = f(2w_1) = 2f(w_1) = 2(2w_1 + 4w_2) = 4w_1 + 8w_2")
so the second column of ")
Now that we understand how and why matrix multiplication works the way it does, how does matrix division work? You are probably familiar with functional inverses. The inverse of a function ) = x = g(f(x))")

 = x+y")
")
")
")



(1)你有感觉到某一类矩阵和矩阵相乘,其实就是解方程时的消元吗?
(2)
你有发现解方程时对矩阵的操作,与消元法解方程的对应关系吗?
你有发现行列式的定义和性质,与消元法解方程的对应关系吗?
你有发现求逆矩阵与消元法解方程的对应关系吗?而奇异矩阵与这个消元法解方程又有什么关系呢?
你有发现非常自然的消元法解方程,是连结矩阵、行列式、逆矩阵这些概念线索和纽带吗?这么普普通通的消元法解方程是多少线性代数基础概念的核心啊!所有的东西都不是无中生有的,
线性代数的设定真的不是像国内那些垃圾教材里面描述的好像一只孙猴子一样,像直接从石头缝里蹦出来的啊!
(3)前面已经提到了,三种“理解矩阵变换”,你理解了吗?
(4)为什么行秩和列秩是一样的?涉及四个基本子空间(列空间,零空间,行空间,左零空间),这个东西是我最近才感悟到的。
概率统计:
(1)极大似然思想
(2)贝叶斯模型
(3)隐变量混合概率模型,EM思想
(4)基础的典型分布如高斯分布
微积分:
(1)极值问题 与 (条件)最优化问题
(2)偏导数,梯度
(3)凸优化和条件最优化问题,这个是理解SVM,或者线性回归等等模型正则化的基础
公开课与相关文献:
(1)麻省理工公开课:线性代数 http://open.163.com/special/opencourse/daishu.html
(2)斯坦福大学公开课 :机器学习课程 http://open.163.com/special/opencourse/machinelearning.html
(3)知乎 https://www.zhihu.com/question/36324957
(4)凸优化 http://www.bilibili.com/video/av8907218/















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









