







 本文介绍了图的广度优先遍历算法,通过迷宫寻路的比喻解释其原理。广度优先遍历从起点开始,逐层访问所有节点,先访问距离起点近的节点。文章还详细阐述了遍历过程,并提供了具体的实现代码,展示了如何使用队列实现该算法。
本文介绍了图的广度优先遍历算法,通过迷宫寻路的比喻解释其原理。广度优先遍历从起点开始,逐层访问所有节点,先访问距离起点近的节点。文章还详细阐述了遍历过程,并提供了具体的实现代码,展示了如何使用队列实现该算法。
前言
广度优先遍历算法是图的另一种基本遍历算法,其基本思想是尽最大程度辐射能够覆盖的节点,并对其进行访问。以迷宫为例,深度优先搜索更像是一个人在走迷宫,遇到没有走过就标记,遇到走过就退一步重新走;而广度优先搜索则可以想象成一组人一起朝不同的方向走迷宫,当出现新的未走过的路的时候,可以理解成一个人有分身术,继续从不同的方向走,,当相遇的时候则是合二为一(好吧,有点扯了)。
广度优先遍历算法的遍历过程
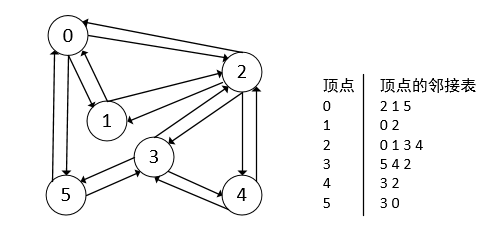
仍然以上一篇图的深度优先遍历算法的例子进行说明,下面是广度优先遍历的具体过程:
- 从起点0开始遍历
- 从其邻接表得到所有的邻接节点,把这三个节点都进行标记,表示已经访问过了
- 从0的邻接表的第一个顶点2开始寻找新的叉路
- 查询顶点2的邻接表,并将其所有的邻接节点都标记为已访问
- 继续从顶点0的邻接表的第二个节点,也就是顶点1,遍历从顶点1开始
- 查询顶点1的邻接表的所有邻接节点,也就是顶点0和顶点2,发现这两个顶点都被访问过了,顶点1返回
- 从顶点0的下一个邻接节点,也就是顶点5,开始遍历
- 查询顶点5的邻接节点,发现其邻接节点3和0都被访问过了,顶点5返回
- 继续从2的下一个邻接节点3开始遍历
- 寻找顶点3的邻接节点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2492
2492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









