







提供推荐CF
此章节介绍了最基本的相似度概念以及简单的推荐算法,重点是Pearson相关性分析。
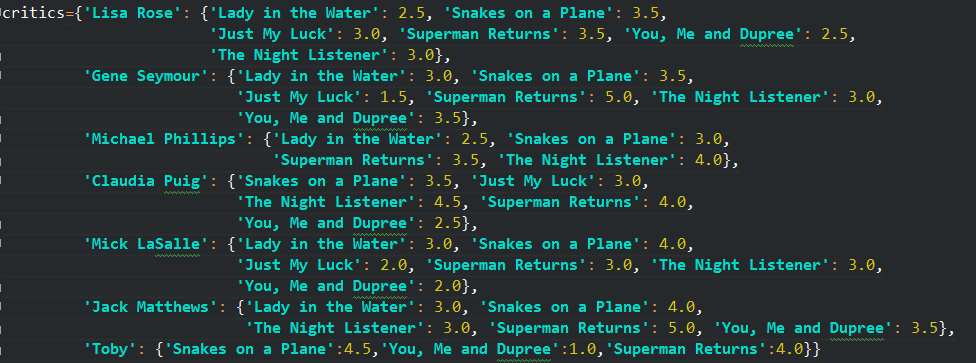
书中给出数据集如下,以一个嵌套字典的形式给出。具体内容是7个人对不同电影的评分。
Pearson相关系数计算
在给不同的人推荐电影时,我们希望参照与他有同样口味的人来进行推荐,这就用到了相关性分析。书中开头介绍了欧几里得距离,这是最简单的相关性分析,显然距离越远相关性越低。这里学习了Pearson相关性分析。
计算公式:
ρ(x,y)=ΣXY−ΣXΣYN(ΣX2−(ΣX)2N)(ΣY2−(ΣY)2N)−−−−−−−−−−−−−−−−−−−−−−−√
该函数返回一个介于-1到1之间的一个数,值越大表明相关性越高。相比欧几里得距离,Pearson相关系数修正了“夸大分值”的情况。例如如果某人总是倾向于相对另一个人给出跟高的分值,而二者的分值只差又始终保持一致,那么我们认为他们有很好的相关性。
代码块
计算Pearson相关系数代码如下:
def sim_pearson(prefs,p1,p2): #pref即给出的数据集,p1与p2分别是需要计算相关性的两个人
si = {} #首先找出两者共同评论过的电影放到字典si里
for item in prefs[p1]:
if item in prefs[p2]:
si[item] = 1
n = len(si) #两者共同评论过的电影
if n==0: return 1
sum1 = sum([prefs[p1][it] for it in si]) #sigma X
sum2 = sum([prefs[p2][it] for it in si]) #sigma Y
sum1Sq = sum([pow(prefs[p1][it],2) for it in si]) #sigma X^2
sum2Sq = sum([pow(prefs[p2][it],2) for it in si]) #sigma Y^2
pSum = sum([prefs[p1][it]*prefs[p2][it] for it in si]) #sigma XY
num = pSum-(sum1*sum2/n) #上述公式分子
den = sqrt( (sum1Sq-pow(sum1,2)/n) * (sum2Sq-pow(sum2,2)/n) ) #上述公式分母
if den == 0:
return 0
r = num/den
return r简单的推荐
如果要对一个人推荐一部电影,我们需要参考很多看过的人给出的评价,给他推荐一部评价最高的电影。显然对于那些口味与他大相径庭的人的评价是不怎么具有参考价值的,而与他口味相似的人的评价的参考价值是很高的,于是我们把相似度作为权值,将其他人的评价进行加权,得到一个比较适合于这个人口味的评分。例如下表:
| 评价者 | 相似度 | Night | S.xNight |
|---|---|---|---|
| Rose | 0.99 | 3.0 | 2.97 |
| Seymour | 0.38 | 3.0 | 1.14 |
| Puig | 0.89 | 4.5 | 4.02 |
| LaSalle | 0.92 | 3.0 | 2.77 |
| Matthews | 0.66 | 3.0 | 1.99 |
| 总计 | 12.89 | ||
| Sim.sum | 3.84 | ||
| 总计/Sim.sum | 3.35 |
如上表,我们用相似度作为权值对Night这部电影的所有评分进行加权得到S.xNight。将相似度加和得到Sim.sum,用加权值除以Sim.sum得到这部电影的评分(之所以这么做是为了防止评论者越多,显然加权和会变得很大,除以相似度来修正这一问题)。我们就可以以此结果进行排序推荐。
代码块
推荐代码如下:
def getRecommendations(prefs,person,similarity = sim_pearson):
totals = {} #所有电影对应的分数构成一个字典
simSums = {} #所有电影对应的相似度之和构成一个字典
for other in prefs:
if other == person: #仅统计person没评价过得电影
continue
sim = similarity(prefs,person,other) #计算other与person的相似度
if sim<0: #相似度小于0的忽略
continue
for item in prefs[other]:
if item not in prefs[person] or prefs[person] == 0: #如果person没评价过这部电影
totals.setdefault(item,0) #加入字典
totals[item] += sim*prefs[other][item] #累加加权评分
simSums.setdefault(item,0) #相似度加入字典
simSums[item] += sim #累加相似度
ranking = [(total/simSums[item],item) for item,total in totals.items()]
ranking.sort()
ranking.reverse()
return ranking

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









