









基于keras的CNN图片分类模型的搭建与调参
更新一下这篇博客,因为最近在CNN调参方面取得了一些进展,顺便做一下总结。
我的项目目标是搭建一个可以分五类的卷积神经网络,然后我找了一些资料看了一些博客,发现keras搭建CNN,还是比较简单快捷的,模块化,易扩展,极简,让我最终选择了keras。本质上keras相对于python,就相当于python相对于c/c++。就是一个封装的一个关系。
然后讲讲我的模型吧。我的模型是由两层卷积层,两层池化层,两层全连接层组成。这个结构 应该算是最简单的卷积神经网络了。可调的参数也并不多。整个分类系统代码组成也很简单,主要就三部分,一个是数据读取处理部分,一个是模型训练部分,一个是模型测试部分。我分类的数据集是通过热成像仪拍摄得到的热成像图,然后经过简单处理之后得到的灰度图。原本这个模型是一个人脸识别系统,把其中摄像头拍摄部分去掉了。只保留图像分类部分的代码,就做成了我的系统了。基本思想还是很简单的。
但是在接触了代码之后,还是发现了很多坑。经过掉坑,爬坑的洗礼之后,写下这篇博客,记载下一些有价值的知识。
1. 数据读取
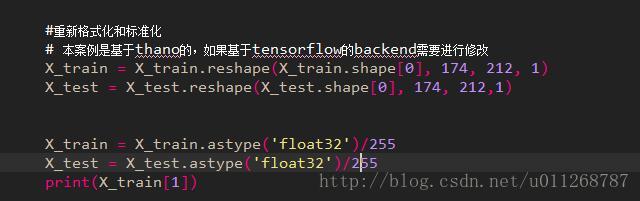
这部分代码开始我就没读懂 ,reshape函数不是将图片的大小改变的嘛?咋改成了四维的?
查了好多博客,都没说出个所以然。后来我想起手上还有三本TensorFlow的电子书,通过书终于发现了问题所在。

这段代码(来自《TensorFlow技术解析与实战》)表示keras分别以theano和TensorFlow为backend实现图像大小重置与存取的区别。同时我还明白了这个代码里面各个参数代表的意思。就比如TensorFlow的吧。
x_test=x_test.reshape(x_test.shape[0],img_rows,img_cols,1)这个x_test.shape[0]表示总共有多少个照片,因为当时读进照片数据的时候,照片都被放在了list里面了,然后他的大小就是整个list就是照片的数目。然后img_rows,img_cols就是每张照片的大小。
.
2. 调参数
由于优化器和批归一化,对最终的结果产生了很大的影响,我将在下面的内容详细地解释一下这两者的优化原理。
要将一个模型的性能达到一个比较高的水准,必定需要调节相关的参数。作为一名小白。一开始我是一脸闷逼的。不知道该调哪些参数,不知道应该调到多大的数值才算合适。虽然现在的分类准确率还是没达到一个令人满意的程度,但是相较于开始已经提升了很多。先记下来一些吧。
我主要调整了两个部分。
- (一)输入图像的大小。这个是我在数据读取部分改的。我将读入的图片长宽调整的更加接近。
- (二)增加了dropout函数,dropout函数说白了就是在训练时将部分神经元暂停工作,提升模型的抗过拟合能力。我在每一层都加入了dropout函数,开始的两层都是比较小的概率(0.15),后面到了全连接层比较大(0.5)
- (三)将模型的优化器由原来的Adagrad,改为adadelta。这一篇文章里面给出了比较详细的优化方法的总结:深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)这个地方,还有一个值得挖掘的地方就是模型的优化器,optimizor对最终结果影响原来这么大。我在代码中用到的优化器依次是Adagrad,adadelta,Adam,效果依次上升。
Adagrad:
Adagrad其实就是对学习率进行了一个约束,
A
d
a
g
r
a
d
其
实
就
是
对
学
习
率
进
行
了
一
个
约
束
,
nt=nt−1+g2t
n
t
=
n
t
−
1
+
g
t
2
Δθt=−ηnt+ϵ√∗gt
Δ
θ
t
=
−
η
n
t
+
ϵ
∗
g
t
对
对
Δθt=−1∑tr=1(gr)2+ϵ,ϵ,用来保证分母非0
Δ
θ
t
=
−
1
∑
r
=
1
t
(
g
r
)
2
+
ϵ
,
ϵ
,
用
来
保
证
分
母
非
0
特点:
前期
gt较小的时候,regularizer较大,能够放大梯度
g
t
较
小
的
时
候
,
r
e
g
u
l
a
r
i
z
e
r
较
大
,
能
够
放
大
梯
度
前期
gt较大的时候,regularizer较小,能约束梯度
g
t
较
大
的
时
候
,
r
e
g
u
l
a
r
i
z
e
r
较
小
,
能
约
束
梯
度
适合处理稀疏梯度
Adadelta:
Adadelta是对Adagrad的扩展,最初的方案依然是对学习率进行自适应的约束,但是进行了计算上的简化。Adagrad会累加之前所有梯度的平方,而Adadelta只累加固定大小的项,并且不直接存储这些项,仅仅是近似计算对应的平均值。即:
A
d
a
d
e
l
t
a
是
对
A
d
a
g
r
a
d
的
扩
展
,
最
初
的
方
案
依
然
是
对
学
习
率
进
行
自
适
应
的
约
束
,
但
是
进
行
了
计
算
上
的
简
化
。
A
d
a
g
r
a
d
会
累
加
之
前
所
有
梯
度
的
平
方
,
而
A
d
a
d
e
l
t
a
只
累
加
固
定
大
小
的
项
,
并
且
不
直
接
存
储
这
些
项
,
仅
仅
是
近
似
计
算
对
应
的
平
均
值
。
即
:
nt=v∗nt−1+(1−v)∗g2t
n
t
=
v
∗
n
t
−
1
+
(
1
−
v
)
∗
g
t
2
Δθt=−ηnt+ϵ√∗gt
Δ
θ
t
=
−
η
n
t
+
ϵ
∗
g
t
此处
Adadelta其实还是依赖于全局学习率的,但是经过近似牛顿迭代法之后:
A
d
a
d
e
l
t
a
其
实
还
是
依
赖
于
全
局
学
习
率
的
,
但
是
经
过
近
似
牛
顿
迭
代
法
之
后
:
E|g2|t=ρ∗E|g2|t−1+(1−ρ)∗g2t
E
|
g
2
|
t
=
ρ
∗
E
|
g
2
|
t
−
1
+
(
1
−
ρ
)
∗
g
t
2
Δxt=−∑t−1r=1Δxr√E|g2|t+ϵ√
Δ
x
t
=
−
∑
r
=
1
t
−
1
Δ
x
r
E
|
g
2
|
t
+
ϵ
其中,E代表期望,可以看出Adadelta已经不用依赖于全局学习率了。
其
中
,
E
代
表
期
望
,
可
以
看
出
A
d
a
d
e
l
t
a
已
经
不
用
依
赖
于
全
局
学
习
率
了
。
特点:
训练初中期,加速效果不错,很快
训练后期,反复在局部最小值附近抖动
Adam:
Adam(AdaptiveMomentEstimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点是经过偏置校正之后,每次迭代学习率都有一个确定的范围,使得参数比较平稳,公式如下:
A
d
a
m
(
A
d
a
p
t
i
v
e
M
o
m
e
n
t
E
s
t
i
m
a
t
i
o
n
)
本
质
上
是
带
有
动
量
项
的
R
M
S
p
r
o
p
,
它
利
用
梯
度
的
一
阶
矩
估
计
和
二
阶
矩
估
计
动
态
调
整
每
个
参
数
的
学
习
率
。
A
d
a
m
的
优
点
是
经
过
偏
置
校
正
之
后
,
每
次
迭
代
学
习
率
都
有
一
个
确
定
的
范
围
,
使
得
参
数
比
较
平
稳
,
公
式
如
下
:
mt=μ∗mt−1+(1−μ)∗gt
m
t
=
μ
∗
m
t
−
1
+
(
1
−
μ
)
∗
g
t
nt=v∗nt−1+(1−v)∗g2t
n
t
=
v
∗
n
t
−
1
+
(
1
−
v
)
∗
g
t
2
m^t=mt1−μt
m
^
t
=
m
t
1
−
μ
t
n^t=nt1−vt
n
^
t
=
n
t
1
−
v
t
Δθt=−m^tn^t√+ϵ∗η
Δ
θ
t
=
−
m
^
t
n
^
t
+
ϵ
∗
η
其中,mt,nt分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望E|gt|,E|g2t|的估计;m^t,n^t是对mt,nt的校正,这样可以近似为对期望的无偏估计。
其
中
,
m
t
,
n
t
分
别
是
对
梯
度
的
一
阶
矩
估
计
和
二
阶
矩
估
计
,
可
以
看
作
对
期
望
E
|
g
t
|
,
E
|
g
t
2
|
的
估
计
;
m
^
t
,
n
^
t
是
对
m
t
,
n
t
的
校
正
,
这
样
可
以
近
似
为
对
期
望
的
无
偏
估
计
。
可以看出,直接对梯度的矩估计,对内存没有额外的要求,并且可以根据梯度进行动态调整,而−m^tn^t√+ϵ对学习率形成了一个动态约束,并且有明确的范围。
可
以
看
出
,
直
接
对
梯
度
的
矩
估
计
,
对
内
存
没
有
额
外
的
要
求
,
并
且
可
以
根
据
梯
度
进
行
动
态
调
整
,
而
−
m
^
t
n
^
t
+
ϵ
对
学
习
率
形
成
了
一
个
动
态
约
束
,
并
且
有
明
确
的
范
围
。
特点:
结合了
Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的特点
A
d
a
g
r
a
d
善
于
处
理
稀
疏
梯
度
和
R
M
S
p
r
o
p
善
于
处
理
非
平
稳
目
标
的
特
点
对内存要求比较小
对
内
存
要
求
比
较
小
为不同参数计算不同的自适应学习率
为
不
同
参
数
计
算
不
同
的
自
适
应
学
习
率
适用于大多数非凸优化,适用于大数据集和高维空间
适
用
于
大
多
数
非
凸
优
化
,
适
用
于
大
数
据
集
和
高
维
空
间
- (四)Batch_normalization(批归一化处理)开始我没注意到有这个优化手段。后来看了些别人博客,于是我想着尝试一下这个BN,我在看的视频里面,也多次提及这个优化手段。但是在使用的时候,我就犯难了,到底应该把代码加在哪儿呢?各种百度不得其解,后来百度了一下终于明白了。CNN with BatchNormalization in Keras 94% 这个代码应用的也是keras实现的CNN,简洁明了,适合小白。
我在这再讲解一下批归一化的原理和作用。
批归一化也叫做批标准化,通俗来说就是对每一层神经网络进行标准化,输入数据进行标准化能让机器学习更加有效地学习。除此之外
batchnormalization
b
a
t
c
h
n
o
r
m
a
l
i
z
a
t
i
o
n
还能有效控制坏的参数初始化,比如说
Relu
R
e
l
u
这种激励函数最怕所有值都落在附属区间。
但是现在遇到的一个问题是训练的准确率还可以能够达到90%+,但是测试准确率只有70%+,因此下一步准备将这个过拟合问题解决。等我将各方面问题解决好,我就会将代码上传到我的GitHub上,供大家学习借鉴。
对了,这一篇知乎专栏是我看到写的比较好的调参博客《如何一步一步提高图像分类准确率?》-曹荣禹,推荐一下
写在最后关于CNN的学习,我开始了大约五六个月,当然这里面是有间断的,关于CNN的认识,现在好多还是停留在纸面上。没法真正完美地解决工程问题。还需要继续努力。以后有新技巧习得,再更!















 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









