







目录
注:这篇文章只是对常用的分类问题中的评价指标的总结。
一、二分类评价指标
1、真实标签-预测标签的混淆矩阵
| 样本被预测为正 | 样本被预测为负 | |
| 实际样本为正 | TP(true positive) | FN (false negative) |
| 实际样本为负 | FP(false positive) | TN(true negative) |
TP:这里的T表示true,样本被正确的预测了,p即positive,表示样本被预测为正样本。
TN:正确的预测了该样本,且样本预测值是负样本
FP:错误的预测了该样本,且样本被预测成了正样本,说明样本本身是负样本
FN:错误的预测了该样本,且样本被预测成了负样本,说明样本本身是正样本
以上的四个值,是样本的真实标签和预测标签之间会发生的所有关联情况,也是分类指标计算的基础。
2、accuracy
accuracy,后面简称acc,是分类中非常常见的一种评价指标,也是非常好理解的一种评价指标,即所有被预测的样本,预测正确的概率是多少,这个其实是比较直观的,就是正确预测样本的占比,计算公式如下:
acc指标存在一个问题,只要样本的标签预测正确了,acc就会上升。如果一个数据集中,正负样本严重失衡,所有的正样本能检测出来,所有的负样本检测不出来,最后的acc还是会很高,但是这样也没有意义。比如在癌症检测里面,不患病的正样本很多,患病的负样本很少,如果只是检测出那些没有患病的人,而患病的样本都没有检测出来,计算acc的时候还是很高,但是实际上acc就不是很适用这种场景,因为如果患了癌症而系统检测检测不出来,那这个检测系统根本就没有意义。
3、precision、recall和F1-score
precision和recall经常一起出现,它们都是只关心预测正确的正样本占的比例,只是分母不一样。precision即准确度,也是衡量分类器能正确识别样本的能力,它表示的是,在被识别成正样本的样本中,正确预测的样本占的比例,通常叫做查准率。recall即召回率,它表示的是,被预测的所有正样本,能够被正确预测的占比,通常叫查全率。计算公式分别如下:
![]()
![]()
![]()
对于F1-score,更一般的有:
![]()
可以看出, F1-score是一个综合的评价指标。对于precision和recall的选择,个人认为应该根据实际的应用场景来,最后想要的是更多的检测出想要的样本,还是尽量少出错。
4、指标的选择问题
例如,在一个癌症病人的检测系统里,我们更希望的是,尽可能多的检测出癌症病人,因为希望它们能得到及时的治疗,那么这个时候就应该用recall,也就是查全率,尽可能将所有的癌症样本识别出来。
如果是在一个垃圾邮件检测系统中,我们当然也很希望尽量检测出垃圾邮件,但是如果把一封正常邮件识别为垃圾邮件,可能会带来很严重的后果。所以,在这种情况下,我们要保证的是系统对邮件的判断的正确性,那么就要用precision,也就是查准率,保证定性为垃圾邮件的样本不出错。
对于precision和recall的选择,包括acc的选择,个人比较赞同的是根据实际的分类任务或者目标,来确定使用哪种指标。acc的话,一般肯定是样本比较均衡的时候一种比较好的选择。
多分类模型Accuracy, Precision, Recall和F1-score的超级无敌深入探讨——NaNNN,这篇文章,作者还给出了一个需要同时考虑precision和recall的比较有趣的例子。
分类问题的评估指标一览——老宋的茶书会,这篇文章作者也有给出一个指标的分析,但是觉得太过学术,不是很好理解。
二、多分类评价指标
其实多分类评价指标也是从二分类评价指标演变而来的,现在来看一下各个指标实际关注的信息。
对于accuracy来说,它是针对全局的样本的,只要样本被正确预测,公式的分子就加1,分母就是全部被预测的样本。所以,样本的类别标签对acc没有影响,acc只关注预测正确与否。所以,对于一个多分类模型,acc的计算方式跟二分类是一样的,都是以样本为单位的。
对于其它指标的计算,如下:
1、macro-F1
最直接的一种计算方式,就是分别计算每个类比的precision和recall,以此计算相应的F1,然后再用类别数平均一下F1,即为macro-F1,感觉这种计算方式比较好理解,也比较好实现。就是每个类别分别计算了,然后再平均。
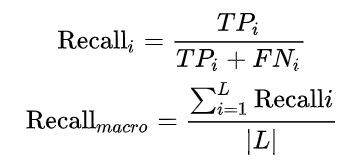
2、weight-F1
这种方式是在macro-F1的基础上考虑到类别不平衡的问题,假设有三类,样本数分别为c1,c2和c3,那么每一类的权重分别为ci/(c1+c2+c3),则precision的计算方式是每个类别的precision和其权重的加权平均,recall也同理,F1则直接由precision和recall计算得到。

3、micro-F1
这种方式是以样本为基本单位,直接根据公式计算全局的precision和recall,计算公式如下:

对于micro-F1,有一个很有意思的性质:
![]()
具体的可以参考这篇文章:多分类模型Accuracy, Precision, Recall和F1-score的超级无敌深入探讨——NaNNN
4、指标的选择问题
从计算公式来看,micro-F1依赖于每个类别的识别准确度,而对于那些样本比较小的类别,可能会拉高precision,所以类别不平衡时用这个指标不怎么合适。在这篇文章:分类问题的评估指标一览——老宋的茶书会,中给出了类别不均衡带来的指标影响,以及指标选择的结论,部分如下:
“我们看到,对于 Macro 来说, 小类别相当程度上拉高了 Precision 的值,而实际上, 并没有那么多样本被正确分类,考虑到实际的环境中,真实样本分布和训练样本分布相同的情况下,这种指标明显是有问题的, 小类别起到的作用太大,以至于大样本的分类情况不佳。 而对于 Micro 来说,其考虑到了这种样本不均衡的问题, 因此在这种情况下相对较佳。
总的来说, 如果你的类别比较均衡,则随便; 如果你认为大样本的类别应该占据更重要的位置, 使用Micro; 如果你认为小样本也应该占据重要的位置,则使用 Macro; 如果 Micro << Macro , 则意味着在大样本类别中出现了严重的分类错误; 如果 Macro << Micro , 则意味着小样本类别中出现了严重的分类错误。
为了解决 Macro 无法衡量样本均衡问题,一个很好的方法是求加权的 Macro, 因此 Weighed F1 出现了。”
三、多标签分类评价指标
参考:Machine Learning]分类问题的性能度量方法——二分类、多分类、多标签分类
多标签分类(multilabel classification )
注:文章是在看了其它文章的基础上总结的,因为定义性的东西就是很确定的,所以公式就直接用其它文章的公式截图的(因为自己输入太耗时了)。对于觉得比较有参考价值的文章,已经在文中穿插给出链接了。本文章也仅作为自己对相关知识点的总结,一点点自己的白话理解,加上前辈的知识总结,以便日后有问题的时候可以再回顾,以免再再网上看多篇文章。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









