









简述
FOTS是CVPR 2018的一篇论文,其是第一篇针对多方向文本的端到端可训练的文本检测+识别算法。(反正论文中是这么说的,感觉貌似不是,莫在意)
概述:FOTS(Fast Oriented Text Spotting)是图像文本检测与识别联合训练、端到端可学习的网络模型。检测和识别任务共享卷积特征层,既节省了计算时间,也比两阶段训练方式能学习到更通用的图像特征。引入了旋转感兴趣区域(RoIRotate), 可以从卷积特征图中产生出水平轴对齐且高度固定(论文中固定为8)的文本区域,从而支持倾斜文本的识别。
得益于检测和识别这两种互补监督的端到端训练,实现了效率和精度的双提升,在icdar 2015上取得89.84%的F1,帧率达到22.6fps。很强的算法!(就是现在还没有官方开源)

上图所示红框内为两阶段法(先检测再识别),蓝框内为端到端(FOTS)的方式,可见端到端的方式比两阶段法几乎快了一倍。
一般来说文本检测和识别是分为两项任务进行的,分开更容易实现,可是也带来了先验知识的损失。FOTS提出了ROIRotate方法,将文本检测和文本识别这两项监督进行融合互补。观察其网络结构可以发现,是将east(检测)和crnn(识别)两个算法通过其提出ROIRotate连接起来。通过这种方式不仅速度快而且相比分开两项任务精度还能所有提升。能有效减少“漏检”、“错检”、“字符错误分割”、“字符错误合并”等4种错误。
网络结构
首先是网络结构,如下:

FOTS的整体结构由4部分组成。shared convolutions(共享特征),the text detection branch(检测分支),RoIRotate operation(仿射变换分支),the text recognition branch(识别分支)。数据通过主干网络提取共享特征,经过检测分支来预测文本框位置和方向,利用仿射变换在共享特征图上将文本框的内容变换到标准x,y坐标轴上,最后经过识别分支得出文本内容。
本文的检测分支为EAST,识别分支为CRNN,所以就整个网络来说,此网络的关键创新点为:提出了RoIRotate ,类似于roi pooling 和roi align,该操作主要池化带方向的文本区域,通过该操作可以实现将文本检测和文本识别端到端的连接起来。
backbone
FOTS的backbone为ResNet50 with FPN,共享卷积层采用了类似U-net的卷积共享方法,将底层和高层的特征进行了融合。这部分和EAST中的特征共享方式一样。最终输出的特征图大小为原图的1/4(论文中说是为了检测小物体)。

检测分支
这部分和EAST基本完全一样,这里我直接拿了“EAST文本检测算法”的网络结构图来作说明:(仅关注红框内的部分)

EAST算法输出了6个channel的feature map:第一个channel表示每个pixel属于正样本(文本区域)的概率;对于每个正样本,后面的4个channel表示该pixel到包围它的bounding box的上、下、左、右边界的距离(这里不太懂不要紧,后面还会说);最后一个channel预测相应bounding box的方向(旋转角度)。
所以检测部分的loss为:文本分类loss和一个bounding box regression loss。其中,文本分类loss是一个交叉熵损失,bounding box regression loss由一个iou loss和一个rotation angle loss组成。文中将 λ θ \lambda_\theta λθ设置为了10,将 λ r e g \lambda_{reg} λreg设置为了1。(超参)
注:其中, Ω是通过OHEM算法在score map上选取的正样本区域, |Ω|表示像素点数, H(px, px*)表示交叉熵。
RoIRotate分支
该模块的目的是:将有角度的文本块(EAST文本检测算法得到的),经过仿射变换,转化为正常的axis-align的,高度固定(论文中固定为了8),且长宽比保持不变的文本块,以满足后续识别分支(CRNN)的输入要求。
该变换分为两步。一是通过text proposals的预测值或者text proposals真实值计算仿射变换矩阵M;二是分别对检测分支得到的不同的文本框实施仿射变换,通过双线性插值获取水平feature map。(训练的时候输入给recognize的部分,是gt的部分经过roirotate得到的feature map;预测的时候输入给recognize的部分是使用的east回归的出来的参数进行roirotate得到的feature map。所以说训练和预测阶段的处理有点不太一样。)
下面是EAST检测分支的输出(这里忽略了第一个表示前景概率的channel),EAST得到的文本框是这样定义的: (???, ?, ?, ?, ?, ?),如下图所示:
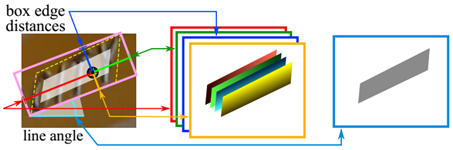
然后对EAST得到的文本框进行RoIRotate变换,得到仿射变换矩阵M,方式如下:


其中M是仿射变换矩阵。 h t , w t h_t,w_t ht,wt分别表示仿射变换后特征图的高度(论文中设置为8)和宽度。 ( x , y ) (x,y) (x,y)表示共享特征图上点的坐标, ( t , b , l , r ) (t,b,l,r) (t,b,l,r) 分别表示到达框内某点到文本候选框的顶部,底部,左侧,右侧的距离,以及 θ \theta θ表示文本候选框的方向。 ( t , b , l , r ) (t,b,l,r) (t,b,l,r)和 θ \theta θ可以由真实候选框或检测分支给出。
得到仿射变换矩阵M, 思路是:
- 先计算ROI内的点(x,y)(在ROI内的坐标为(l, t))旋转至水平后要平移的距离。
- 计算目标高度ht与预测高度(t+b)的比值s, 为保持ROI的高宽比, 预测的长度(l+r)进行s倍的放缩。
- 平移(tx, ty), 放缩, 旋转得到水平的ROI。
- 按照仿射矩阵M, 可得目标ROI上每个像素点对应的原ROI上的坐标。
接下使用仿射变换参数,可以轻松生成最终的target RoI特征:

上公式表示目标ROI(I, j, c)处要填入的像素值, hs,ws表示ROIRotate的高和宽, Umn表示原ROI中(n, m, c)处的像素值, k()表示通用采样核(generic sampling kernel), 其参数φx, φy定义了采样方式, 此处取双线性插值采样。处理旋转好的目标ROI在宽的方向用0填充至固定宽度, 填充的部分不计算loss。
识别分支
识别分支就是CRNN,这部分不再详细介绍,可以参考我的另一篇博客。
这部分的损失函数和CRNN也是一样的,如下:

损失函数
综上所述,整个网络的损失函数为一个多任务损失函数:
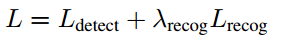
这里
λ
r
e
c
o
g
\lambda_{recog}
λrecog设置为了1。
这确实是一个很强悍的算法,就是目前没开源且复现代码没成功,有什么疑问欢迎留言。
done~
References
- https://arxiv.org/abs/1801.01671
- https://zhuanlan.zhihu.com/p/51090538
- https://blog.csdn.net/u013063099/article/details/89236368
- https://blog.csdn.net/yang_daxia/article/details/88047035
- https://blog.csdn.net/sinat_30822007/article/details/89294068
- https://blog.csdn.net/qq_14845119/article/details/84635847















 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









