







- 机器学习项目的完整周期
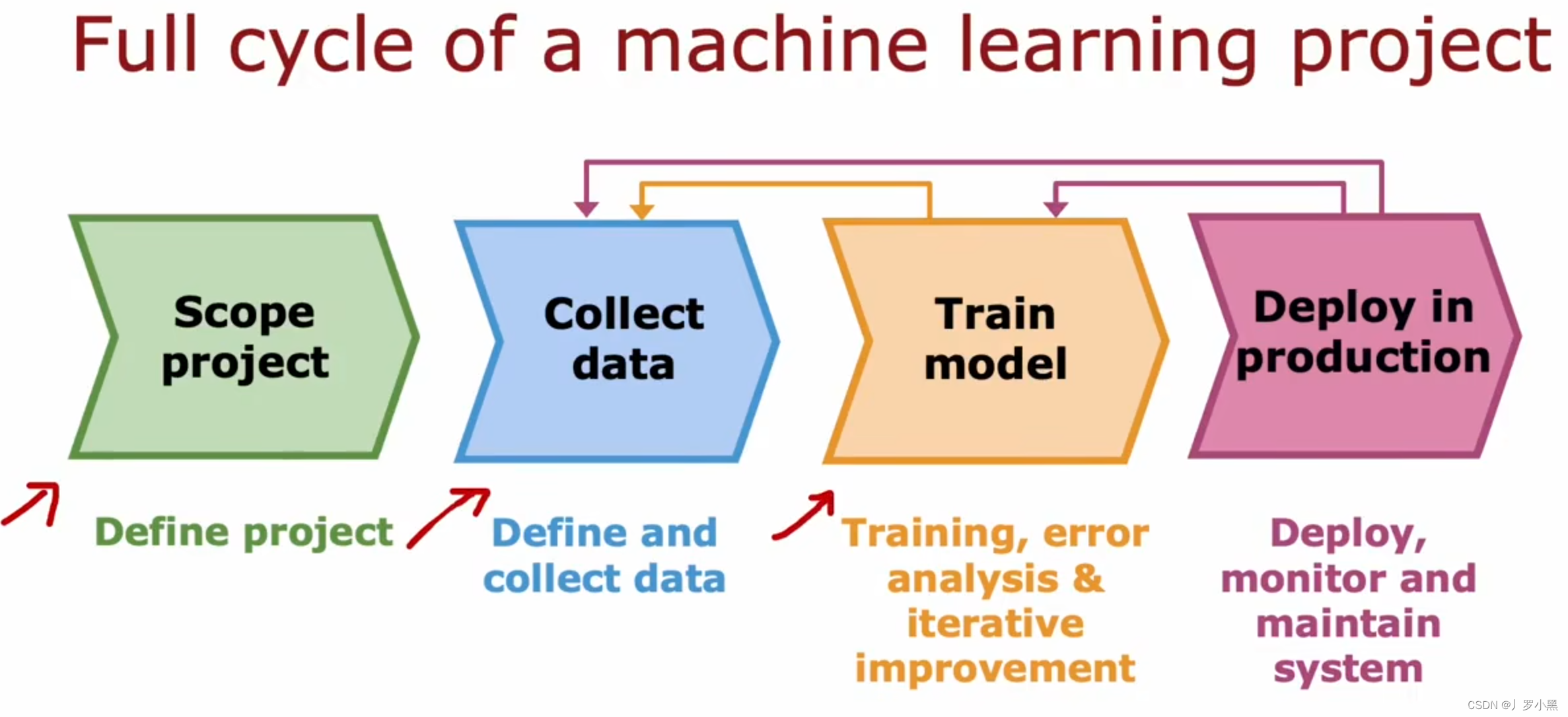
- 第一步,决定项目是什么。第二步,收集数据。第三步,训练模型,进行错误分析并改进模型,可能会回到第二步。第四步,当模型足够好后,部署在生产环境中,继续监控性能并维护模型,以防性能下降,可能会回到第二步或第三步。
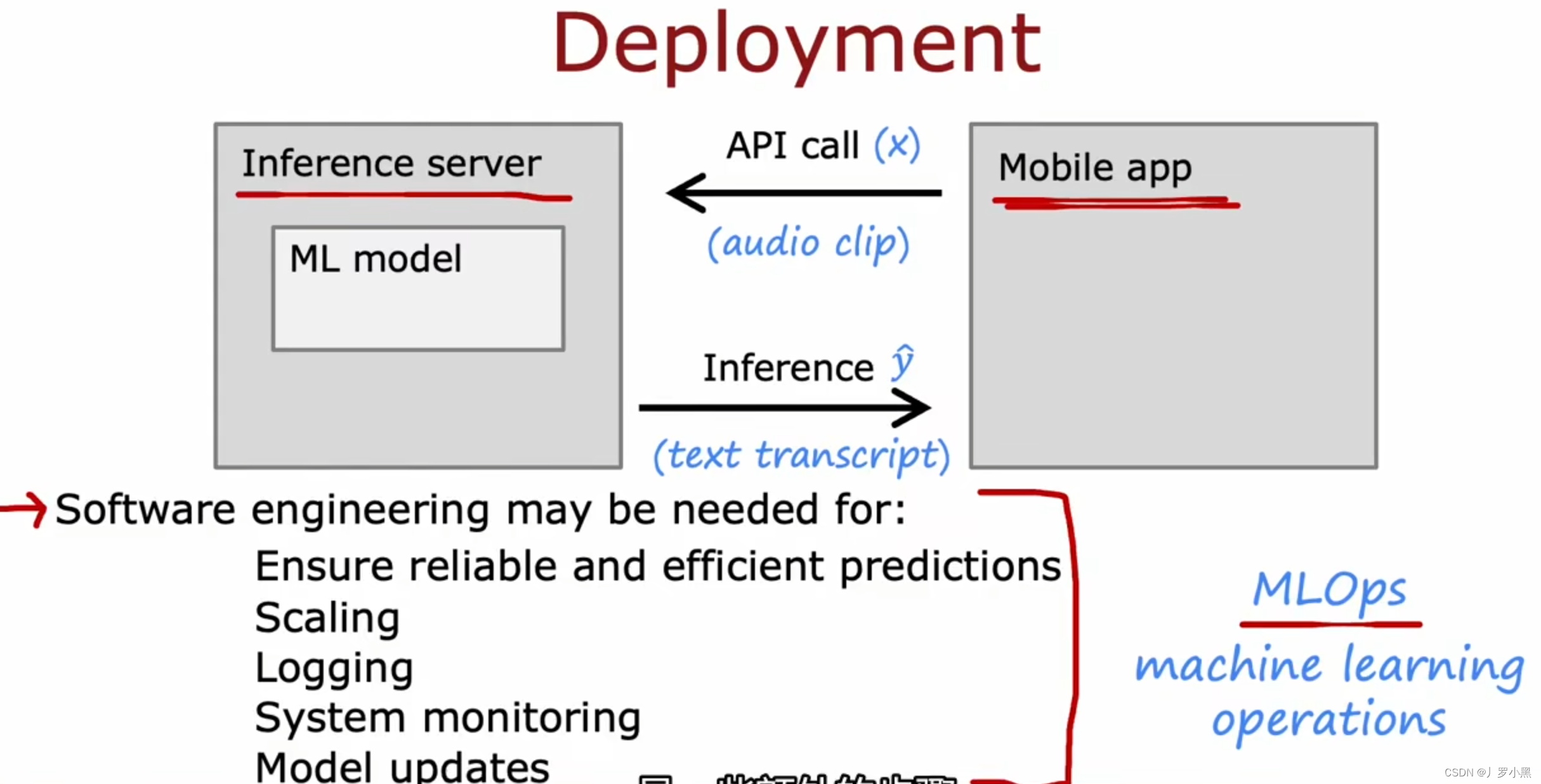
- 部署在生产环境中的常见方法:将模型部署在服务器中,并在应用程序中通过API调用,最后返回模型的预测
- 根据生产环境是服务于少数几个用户还是几百万个用户,软件工程的需求也有所不同:确保可靠和有效的预测输出,大量用户的扩展,记录用户输入输出数据,系统监控,模型更新等。
- 精确度和召回率

- 对于倾斜数据集(正面例子比反面例子不是50:50),我们通常不使用分类错误,而使用其他错误度量(精确度、召回率)来衡量模型的表现
- 如上图,对于只有0.5%的人患有罕见病的情况,如果我们的模型的分类错误率有1%,而一个只会输出y=0的模型的分类错误率却仅有0.5%,这很明显我们的模型还是能判断出一些罕见病,因此表现要比只会输出y=0的模型要好,但通过分类错误值却不容易判断

- 左图为混淆矩阵,分别将真实分类和预测分类填入矩阵中,四个区域分别为:真阳性(True positive),真阴性(True negative),假阳性(False positive),假阴性(False negative)
- 精确度为在所有我们预测y=1的例子中,真正为y=1的概率有多少。即 True positive / Predicted Class
- 召回率为在所有真正为y=1的例子中,我们预测y=1的概率有多少。即True positive / Actual Class
- 如果该模型一个y=1的例子都预测不出来,那我们说该模型的精确度为零,虽然此时精确度为 0 / 0 无定义
- 零召回率和零精确度都能表示该模型不是一个很好的模型,所以我们要求召回率和精确度都很高
- Precision很高:说话靠谱,Recall很高:遗漏很少

- 我们可以通过取不同的阈值,来选择不同的精确度和召回率。
- 通常对大多数学习算法来说,当阈值越高,精确度越高,召回率越低;当阈值越低,精确度越低,召回率越高。
- F1分数

- 如果通过精确度和召回率不容易判断模型的好坏,我们可以合并精确度和召回率,即取它俩的调和平均数(F1),通过F1的值来判断模型的好坏
- 调和平均数是强调较小值的平均数
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











