






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
机器学习算法基础-day02
3. sklearn数据集与估计器
3.1 数据集划分
机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
3.2 sklearn数据集划分API
sklearn.model_selection.train_test_split
3.3 scikit-learn数据集API介绍
sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集、下载的目录,默认是 ~/scikit_learn_data/
获取数据集返回的类型:
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名,回归数据集没有
3.3.1 sklearn分类数据集
3.3.2 数据集进行分割

import pandas as pd
from sklearn.datasets import load_iris,fetch_20newsgroups,load_boston
li=load_iris()
print("获取特征值")
print(li.data)
print(type(li.data))
print("获取目标值")
print(li.target)
print(type(li.target))
print(li.DESCR)
# 注意返回值,训练集train x_train,y_train 测试集test x_test,y_test
x_train,x_test,y_train,y_test=train_test_split(li.data,li.target,test_size=0.25)
print("训练集特征值和目标值",x_train,y_train)
print("测试集特征值和目标值",x_test,y_test)

3.3.3 用于分类的大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset: ‘train’或者’test’,‘all’,可选,选择要加载的数据集.
训练集的“训练”,测试集的“测试”,两者的“全部”
datasets.clear_data_home(data_home=None)
清除目录下的数据
import pandas as pd
from sklearn.datasets import load_iris,fetch_20newsgroups,load_boston
#获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
# news=fetch_20newsgroups(subset="all")
# print(news.data)
# print(news.target)
3.3.4 sklearn回归数据集
import pandas as pd
from sklearn.datasets import load_iris,fetch_20newsgroups,load_boston
#获取回归数据集:波士顿房价
# lb=load_boston()
# print("获取特征值")
# print(lb.data)
# print("获取目标值")
# print(lb.target)
# print(lb.DESCR)

3.4 转换器与估计器
想一下之前做的特征工程的步骤?
1、实例化 (实例化的是一个转换器类(Transformer))
2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
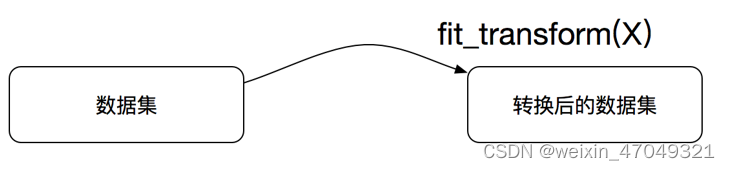
3.4.1 sklearn机器学习算法的实现-估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
1、用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
sklearn.tree 决策树与随机森林
2、用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
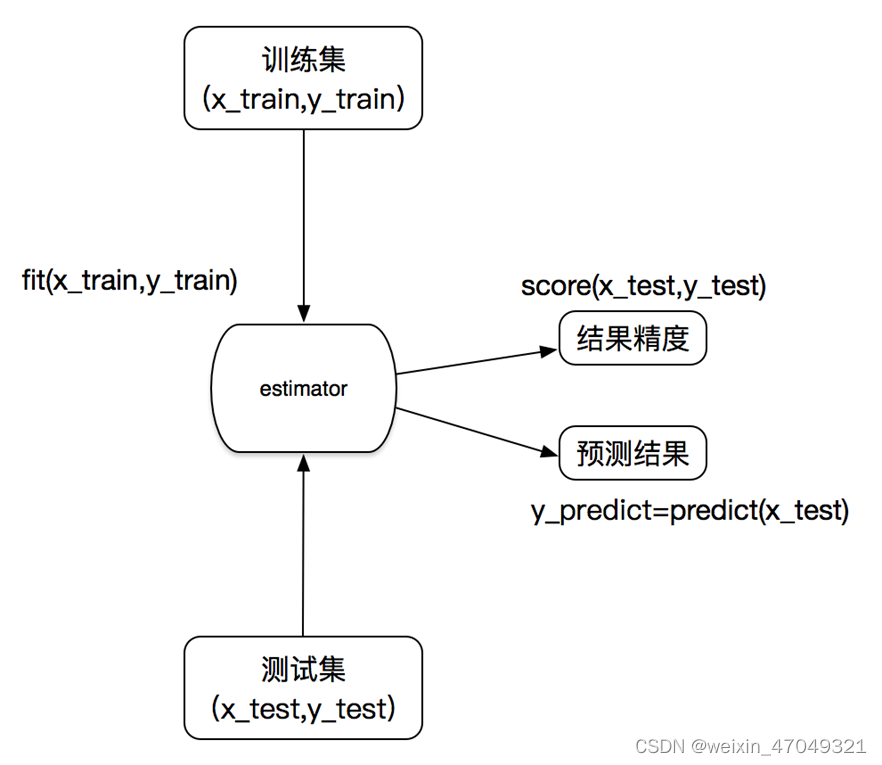
3.4.2 估计器的工作流程
4.Scikit-learn的分类器算法
4.1 分类算法-k近邻算法
你的“邻居”来推断出你的类别


定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
4.1.1 计算距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
比如说,a(a1,a2,a3),b(b1,b2,b3)

4.1.2 sklearn k-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
4.1.3 k近邻算法实例-预测入住位置


def knncls():
"""
K-近邻 预测用户签到位置
:return:None
"""
#读取数据
data=pd.read_csv(r"C:\01-工作相关\0002-dingdownload\数据集\facebook-v-predicting-check-ins\train.csv")
#print(data.shape)
#特征工程(标准化)
#1 缩小数据
data=data.query("x>1.0 & x<1.25 & y>2.5 & y<2.75")
#print(data.head(10))
#print(data.shape)
#处理时间的数据
time_value=pd.to_datetime(data["time"],unit="s")
# print(time_value)
#把日期格式转换成字典格式:
time_value = pd.DatetimeIndex(time_value)
# print(time_value)
# 构造一些特征
data["day"]=time_value.day
data["hour"]=time_value.hour
data["weekday"]=time_value.weekday
# 把时间戳特征删除
data=data.drop(["time"],axis=1)
# print(data)
#把签到数量少于n个的目标位置删除
place_count=data.groupby('place_id').count()
tf=place_count[place_count.row_id>3].reset_index()
data=data[data['place_id'].isin(tf.place_id)]
#将row_id这一列删除,因为意义不大,影响预测得分
data=data.drop(["row_id"],axis=1)
# print(data)
#取出数据当中的特征值和目标值
y=data["place_id"]
x=data.drop(["place_id"],axis=1)
#进行数据的分割,训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
# 特征工程(标准化)
std=StandardScaler()
#要对测试集合训练集的特征值进行标准化
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
#进行算法流程,#超参数
knn=KNeighborsClassifier()
# #fit, predict,score
# knn.fit(x_train,y_train)
# #得出预测结果
# y_predict=knn.predict(x_test)
# print("预测的目标签到位置为:",y_predict)
# #得出准确率
# print("预测的准确率:",knn.score(x_test,y_test))
# 进行网格搜索与交叉验证
param={"n_neighbors":[3,5,10]}
gc=GridSearchCV(knn,param_grid=param,cv=3)
gc.fit(x_train,y_train)
#预测准确率:
print("在测试集上准确率:",gc.score(x_test,y_test))
print("在交叉验证中测试的最好结果:",gc.best_score_)
print("最好的参数模型:", gc.best_estimator_)
print("每次交叉验证后的测试集准确率结果和训练集准确率结果:", gc.cv_results_)
return None
运行结果:
预测的目标签到位置为: [2946102544 2355236719 7707340051 ... 2355236719 2355236719 1097200869]
预测的准确率: 0.46643026004728133
Process finished with exit code 0
进行网格搜索与交叉验证后运行结果:
在测试集上准确率: 0.48321513002364064
在交叉验证中测试的最好结果: 0.460199053367299
最好的参数模型: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
每次交叉验证后的测试集准确率结果和训练集准确率结果: {'mean_fit_time': array([0.03949324, 0.03179892, 0.03315187]), 'std_fit_time': array([0.00332427, 0.00078708, 0.00427661]), 'mean_score_time': array([0.69310975, 0.73931638, 0.80941653]), 'std_score_time': array([0.01768546, 0.02373735, 0.13976549]), 'param_n_neighbors': masked_array(data=[3, 5, 10],
mask=[False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 10}], 'split0_test_score': array([0.43286052, 0.45460993, 0.45390071]), 'split1_test_score': array([0.43840151, 0.46039253, 0.45566328]), 'split2_test_score': array([0.43887444, 0.4655947 , 0.46654055]), 'mean_test_score': array([0.43671216, 0.46019905, 0.45870151]), 'std_test_score': array([0.00273035, 0.0044866 , 0.00558955]), 'rank_test_score': array([3, 1, 2])}
Process finished with exit code 0
4.1.4 k-近邻算法优缺点

4.2 分类算法-朴素贝叶斯算法
联合概率和条件概率
- 联合概率:包含多个条件,且所有条件同时成立的概率
记作:𝑃(𝐴,𝐵) - 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
记作:𝑃(𝐴|𝐵)
特性:P(A1,A2|B) = P(A1|B)P(A2|B)
注意:此条件概率的成立,是由于A1,A2相互独立的结果
4.2.1 朴素贝叶斯-贝叶斯公式

公式分为三个部分:
𝑃(𝐶):每个文档类别的概率(某文档类别词数/总文档词数)
𝑃(𝑊│𝐶):给定类别下特征(被预测文档中出现的词)的概率
计算方法:𝑃(𝐹1│𝐶)=𝑁𝑖/𝑁 (训练文档中去计算)
𝑁𝑖为该𝐹1词在C类别所有文档中出现的次数
N为所属类别C下的文档所有词出现的次数和
𝑃(𝐹1,𝐹2,…) 预测文档中每个词的概率

拉普拉斯平滑
问题:从上面的例子我们得到娱乐概率为0,这是不合理的,如果词频列表里面
有很多出现次数都为0,很可能计算结果都为零
解决方法:拉普拉斯平滑系数
𝑃(𝐹1│𝐶)=(𝑁𝑖+𝛼)/(𝑁+𝛼𝑚)
𝛼为指定的系数一般为1,m为训练文档中统计出的特征词个数
4.2.2 sklearn朴素贝叶斯实现API
sklearn.naive_bayes.MultinomialNB
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
朴素贝叶斯分类
alpha:拉普拉斯平滑系数
4.2.3 朴素贝叶斯算法案例
sklearn20类新闻分类
20个新闻组数据集包含20个主题的18000个新闻组帖子
def naive_bayes():
"""
朴素贝叶斯 对每篇文章进行分类
:return: None
"""
#加载20类新闻数据,
news = fetch_20newsgroups(subset="all")
#并进行数据分割
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25)
#对数据集进行特征抽取
tf=TfidfVectorizer()
#以训练集当中的词的列表进行每篇文章重要性统计["a","b","c","d"]
x_train=tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test=tf.transform(x_test)
print(x_train.toarray())
#进行朴素贝叶斯算法的预测
mlt=MultinomialNB(alpha=1.0)
mlt.fit(x_train,y_train)
y_predict=mlt.predict(x_test)
print("预测的文章类别为:",y_predict)
#得出准确率
print("准确率为:",mlt.score(x_test,y_test))
#得出精确率和召回率
print("每个类别的精确率和召回率:",classification_report(y_test,y_predict,target_names=news.target_names))
return None
if __name__=="__main__":
naive_bayes()
运行结果:
预测的文章类别为: [10 2 12 ... 10 6 14]
准确率为: 0.8671477079796265
每个类别的精确率和召回率: precision recall f1-score support
alt.atheism 0.88 0.75 0.81 208
comp.graphics 0.87 0.80 0.84 225
comp.os.ms-windows.misc 0.85 0.86 0.86 230
comp.sys.ibm.pc.hardware 0.82 0.83 0.83 253
comp.sys.mac.hardware 0.92 0.90 0.91 235
comp.windows.x 0.95 0.87 0.91 234
misc.forsale 0.94 0.74 0.82 235
rec.autos 0.93 0.90 0.92 259
rec.motorcycles 0.93 0.97 0.95 238
rec.sport.baseball 0.97 0.96 0.97 267
rec.sport.hockey 0.93 0.98 0.95 277
sci.crypt 0.81 0.98 0.89 256
sci.electronics 0.86 0.86 0.86 218
sci.med 0.93 0.90 0.91 226
sci.space 0.90 0.96 0.93 241
soc.religion.christian 0.60 0.98 0.75 268
talk.politics.guns 0.77 0.97 0.86 226
talk.politics.mideast 0.93 0.96 0.95 259
talk.politics.misc 0.98 0.62 0.76 203
talk.religion.misc 1.00 0.18 0.30 154
accuracy 0.87 4712
macro avg 0.89 0.85 0.85 4712
weighted avg 0.88 0.87 0.86 4712
Process finished with exit code 0
4.2.4 朴素贝叶斯分类优缺点
优点:
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
分类准确度高,速度快
缺点:
需要知道先验概率P(F1,F2,…|C),因此在某些时候会由于假设的先验
模型的原因导致预测效果不佳。
4.3 分类算法-决策树、随机森林
4.3.1 决策树
决策树是一种基本的分类方法,当然也可以用于回归。我们一般只讨论用于分类的决策树。决策树模型呈树形结构。在分类问题中,表示基于特征对实例进行分类的过程,它可以认为是if-then规则的集合。在决策树的结构中,每一个实例都被一条路径或者一条规则所覆盖。通常决策树学习包括三个步骤:特征选择、决策树的生成和决策树的修剪

4.3.1.1 特征选择
银行贷款数据

你如何去划分是否能得到贷款?
决策树的实际划分

问题是究竟选择哪个特征更好些呢?那么直观上,如果一个特征具有更好的分类能力,是的各个自己在当前的条件下有最好的分类,那么就更应该选择这个特征。信息增益就能很好的表示这一直观的准则。这样得到的一棵决策树只用了两个特征就进行了判断:
通过信息增益生成的决策树结构,更加明显、快速的划分类别。
4.3.1.2 信息熵

“谁是世界杯冠军”的信息量应该比5比特少。香农指出,它的准确信息量应该是:
H = -(p1logp1 + p2logp2 + … + p32log32)
H的专业术语称之为信息熵,单位为比特。
公式:

当这32支球队夺冠的几率相同时,对应的信息熵等于5比特
信息和消除不确定性是相联系的
决策树的划分依据之一-信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:

注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
信息增益的计算


4.3.1.3 常见决策树使用的算法
ID3
信息增益 最大的准则
C4.5
信息增益比 最大的准则
CART
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的默认原则
4.3.1.4 sklearn决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
method:
decision_path:返回决策树的路径
4.3.1.5 泰坦尼克号乘客生存分类模型
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return: None
"""
# 获取数据
titan=pd.read_csv("C:/01-工作相关/0002-dingdownload\数据集/titanic/train.csv")
# print(titan.head())
# print(titan.info())
#处理数据,找出特征值和目标值 (筛选了3个)
x=titan[["Pclass","Age","Sex"]]
y=titan["Survived"]
#处理缺失值
x["Age"].fillna(x["Age"].mean(),inplace=True)
# print(x)
#进行训练集测试集分类
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#进行处理(特征工程) 特征--》类别--》one_hot编码
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient="records"))
# print(dict.get_feature_names())
x_test=dict.transform(x_test.to_dict(orient="records"))
# print(x_train)
# #用决策树进行预测
# dec=DecisionTreeClassifier(max_depth=5)
# dec.fit(x_train,y_train)
# #预测准确率
# print("预测的准确率:",dec.score(x_test,y_test))
# #导出决策树的结构
# export_graphviz(dec,out_file="./tree.dot",feature_names=['Age', 'Pclass', 'Sex=female', 'Sex=male'])
# 随机森林进行预测 (超参数调优)
rf=RandomForestClassifier()
# 进行网格搜索与交叉验证
param={"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
gc=GridSearchCV(rf,param_grid=param,cv=6)
gc.fit(x_train,y_train)
print("准确率:",gc.score(x_test,y_test))
print("查看选择的参数模型:",gc.best_params_)
return None
if __name__=="__main__":
decision()
决策树运行结果:
预测的准确率: 0.7982062780269058
Process finished with exit code 0
随机森林进行预测 (超参数调优)运行结果:
准确率: 0.8295964125560538
查看选择的参数模型: {'max_depth': 5, 'n_estimators': 800}
Process finished with exit code 0
4.3.2 集成学习方法-随机森林
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
4.3.2.1 什么是随机森林
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
学习算法
根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
4.3.2.2 集成学习API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,
max_depth=None, bootstrap=True, random_state=None)
随机森林分类器
n_estimators:integer,optional(default = 10) 森林里的树木数量
120,200,300,500,800,1200
criteria:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度
5,8,15,25,30
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
4.3.2.3 随机森林的优点
在当前所有算法中,具有极好的准确率
能够有效地运行在大数据集上
能够处理具有高维特征的输入样本,而且不需要降维
能够评估各个特征在分类问题上的重要性
对于缺省值问题也能够获得很好得结果
4.4 分类模型的评估
estimator.score()
一般最常见使用的是准确率,即预测结果正确的百分比
混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)

4.4.1 精确率(Precision)与召回率(Recall)

其他分类标准,F1-score,反映了模型的稳健型
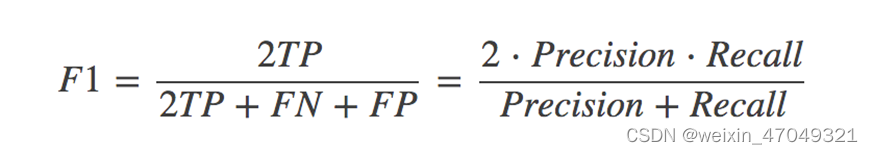
4.4.2 分类模型评估API
sklearn.metrics.classification_report
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值
y_pred:估计器预测目标值
target_names:目标类别名称
return:每个类别精确率与召回率
4.5 模型的选择与调优
4.5.1 交叉验证
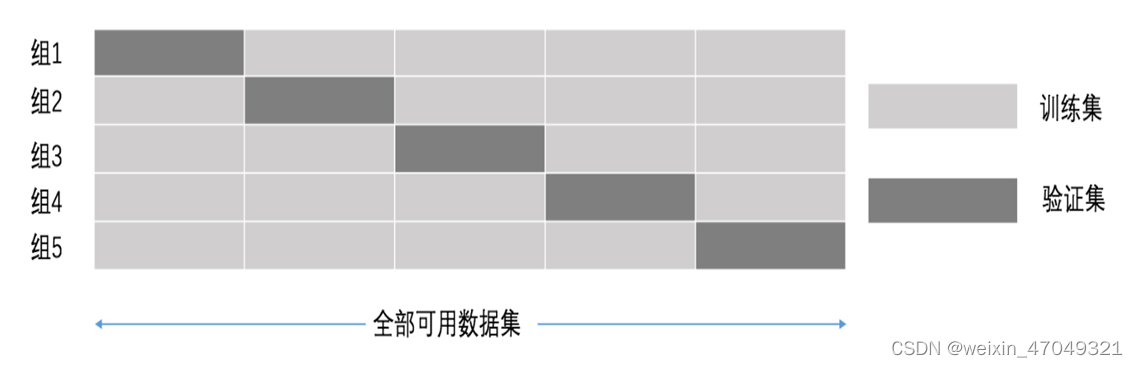
交叉验证:为了让被评估的模型更加准确可信
交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分
成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同
的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉
验证。
4.5.2 超参数搜索-网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),
这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组
合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建
立模型。

4.5.3 超参数搜索-网格搜索API
sklearn.model_selection.GridSearchCV
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
对估计器的指定参数值进行详尽搜索
estimator:估计器对象
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
fit:输入训练数据
score:准确率
结果分析:
best_score_:在交叉验证中测试的最好结果
best_estimator_:最好的参数模型
cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果
















 2400
2400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











