







优化器
- 在模型的训练过程中,我们根据反向传播来获取每个网络节点的对应梯度,之后通过某种算法(优化器)根据对应梯度来不断更新节点的参数,最终达到最小loss的结果。
- 优化器有很多,但有两个参数是所有优化器都有的:
- 模型的节点参数、学习率,其中:学习率是我们手动指定的,一般都为较小的数,如下:
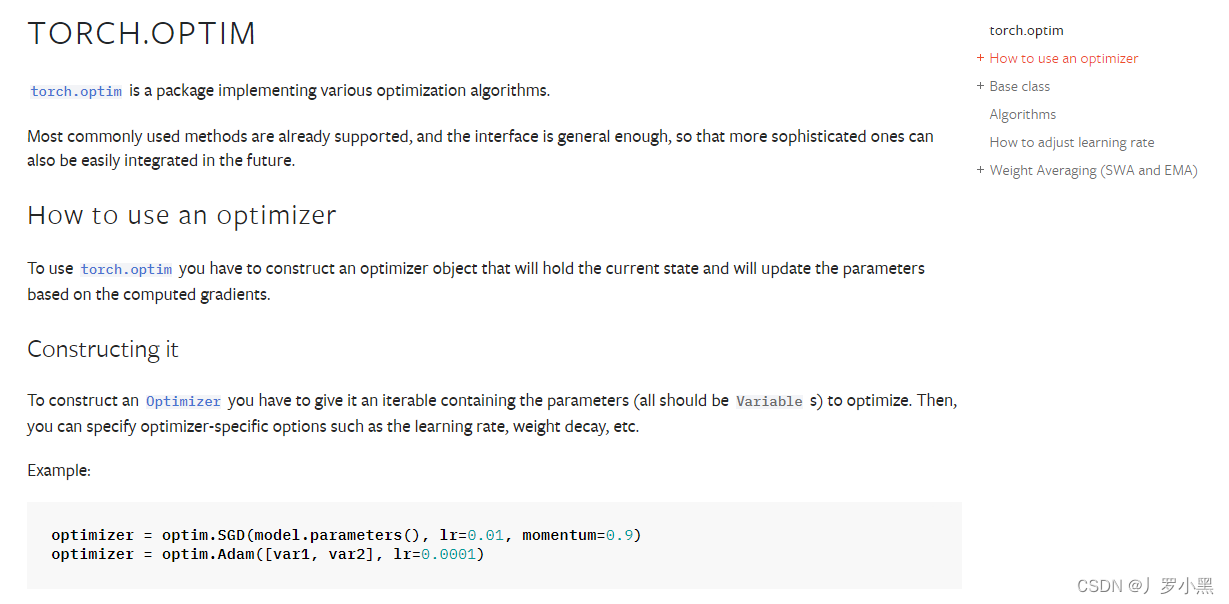
- 模型的节点参数、学习率,其中:学习率是我们手动指定的,一般都为较小的数,如下:
- 以下为使用优化器的步骤:
- 注意,在每次反向传播(backward)之前,需要进行梯度清零(zero_grad)。
- 因为在反向传播过程中,计算出的梯度会累积在模型的参数中。如果不进行梯度清零,那么在下一次反向传播时,当前的梯度会与上一次的梯度累加,导致更新参数时的梯度方向不准确,从而影响模型的收敛性和性能。所以为了确保每次的反向传播都是计算的当前参数下的梯度,需要进行梯度清零。

- 因为在反向传播过程中,计算出的梯度会累积在模型的参数中。如果不进行梯度清零,那么在下一次反向传播时,当前的梯度会与上一次的梯度累加,导致更新参数时的梯度方向不准确,从而影响模型的收敛性和性能。所以为了确保每次的反向传播都是计算的当前参数下的梯度,需要进行梯度清零。
- 下图中的data为网络节点参数,grad为梯度:
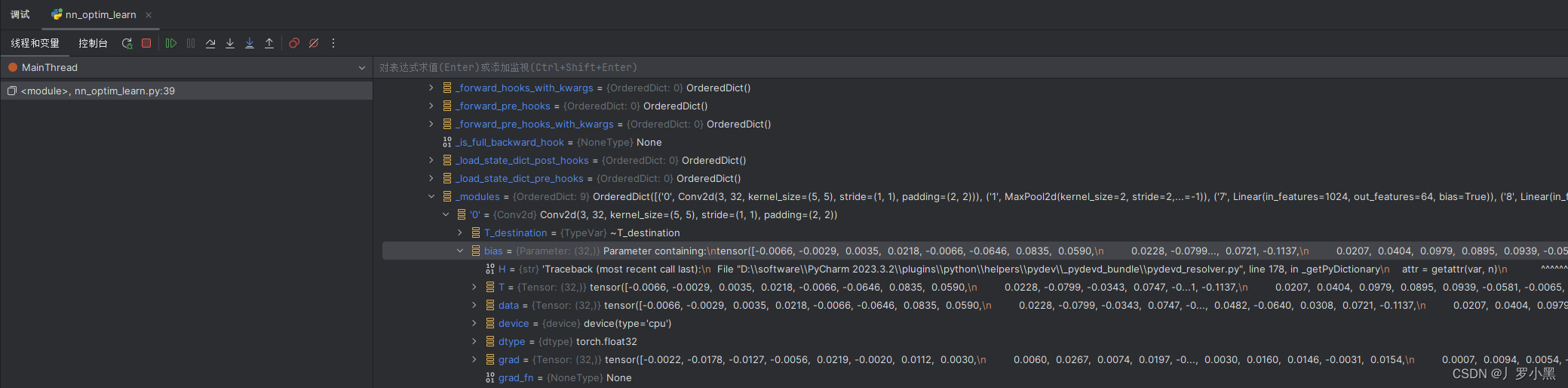
- 注意,在每次反向传播(backward)之前,需要进行梯度清零(zero_grad)。
- 以下为采用SGD优化器,并结合上一节的交叉熵损失函数,对CIFAR10数据集进行分类的模型代码:
- 这里我们将每轮中每个预测的loss加和,作为该轮模型的整体loss进行输出
import torch
import torchvision
from torch import nn
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
class Tudui(nn.Module):
def __init__(self):
super().__init__()
self.module1 = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, input):
output = self.module1(input)
return output
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01) # SGD优化器 随机梯度下降
for epoch in range(20):
runnning_loss = 0.0
for data in test_loader:
inputs, targets = data
outputs = tudui(inputs)
result_loss = loss(outputs, targets) # 计算loss
optim.zero_grad() # 梯度清零,注意需要在反向传播之前
result_loss.backward() # 反向传播,计算梯度,注意需要使用计算后的loss
optim.step() # 更新参数
runnning_loss += result_loss
print(f'epoch: {epoch}, loss: {runnning_loss}')
使用和修改现有网络模型
- 在我们不使用预训练的网络模型时,模型各节点的参数都是默认设置。如果我们更换预训练的模型,则节点参数是已经在某个数据集上训练好的,可以达到一个比较好的输出结果
- VGG16模型的用法:
- 注意:当weights = None时,表示不使用预训练的网络模型,节点参数使用默认设置
- 当weights = 'DEFAULT’时,表示使用预训练的网络模型
- 以下是VGG16在ImageNet数据集上,使用预训练的节点参数:

- 以下为VGG16的默认节点参数:

- 可以打印VGG16的模型结构,代码如下:
- 由最后的输出结果可以看出VGG16的预测类别为1000类,符合ImageNet数据集的类别
import torch
import torchvision
import torch.nn as nn
# train_dataset = torchvision.datasets.ImageNet(root = 'Dataset', split='train', download=True, transform=torchvision.transforms.ToTensor())
# 由于数据集太大,现在已经不提供下载,报错如下:
# RuntimeError: The archive ILSVRC2012_devkit_t12.tar.gz is not present in the root directory or is corrupted. You need to download it externally and place it in Dataset.
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights="DEFAULT")
print(vgg16_false)
# 输出结果:
# VGG(
# (features): Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace=True)
# (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (6): ReLU(inplace=True)
# (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (8): ReLU(inplace=True)
# (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (11): ReLU(inplace=True)
# (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (13): ReLU(inplace=True)
# (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (15): ReLU(inplace=True)
# (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (18): ReLU(inplace=True)
# (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (20): ReLU(inplace=True)
# (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (22): ReLU(inplace=True)
# (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (25): ReLU(inplace=True)
# (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (27): ReLU(inplace=True)
# (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (29): ReLU(inplace=True)
# (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
# (classifier): Sequential(
# (0): Linear(in_features=25088, out_features=4096, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=4096, out_features=4096, bias=True)
# (4): ReLU(inplace=True)
# (5): Dropout(p=0.5, inplace=False)
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# )
# )

- 由于CIFAR10数据集只有10各类别,所以我们可以修改VGG16的最后一层的输出,将1000改为10,或者再添加一层将1000转为10。
- 可以使用 .add_module(name, module)函数。
- name:表示添加层的名字
- module:表示添加的层,如nn.Linear()、nn.Conv2d()、nn.Sequential()均可
- 可以使用 .add_module(name, module)函数。
- 添加一层的代码如下:
- 如果我们直接用模型名.add_module(),那么我们添加的层是在模型的最末端
- 我们也可以使用模型名.sequential名.add_module()的形式,那么我们添加的层就是在该sequential的最末端
import torch
import torchvision
import torch.nn as nn
# train_dataset = torchvision.datasets.ImageNet(root = 'Dataset', split='train', download=True, transform=torchvision.transforms.ToTensor())
# 由于数据集太大,现在已经不提供下载,报错如下:
# RuntimeError: The archive ILSVRC2012_devkit_t12.tar.gz is not present in the root directory or is corrupted. You need to download it externally and place it in Dataset.
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights="DEFAULT")
# print(vgg16_false)
# print(vgg16_true)
test_dataset = torchvision.datasets.CIFAR10(root = 'Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
vgg16_true.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
# 输出结果:
# VGG(
# (features): Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace=True)
# (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (6): ReLU(inplace=True)
# (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (8): ReLU(inplace=True)
# (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (11): ReLU(inplace=True)
# (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (13): ReLU(inplace=True)
# (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (15): ReLU(inplace=True)
# (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (18): ReLU(inplace=True)
# (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (20): ReLU(inplace=True)
# (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (22): ReLU(inplace=True)
# (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (25): ReLU(inplace=True)
# (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (27): ReLU(inplace=True)
# (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (29): ReLU(inplace=True)
# (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
# (classifier): Sequential(
# (0): Linear(in_features=25088, out_features=4096, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=4096, out_features=4096, bias=True)
# (4): ReLU(inplace=True)
# (5): Dropout(p=0.5, inplace=False)
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# )
# (add_linear): Linear(in_features=1000, out_features=10, bias=True)
# )
- 修改一层的代码如下:
- 可以通过模型实例.层名的方法来修改某一层,如果为该层为sequential,那么层名后加 [ ] 可以指定sequential中的第几层
import torch
import torchvision
import torch.nn as nn
# train_dataset = torchvision.datasets.ImageNet(root = 'Dataset', split='train', download=True, transform=torchvision.transforms.ToTensor())
# 由于数据集太大,现在已经不提供下载,报错如下:
# RuntimeError: The archive ILSVRC2012_devkit_t12.tar.gz is not present in the root directory or is corrupted. You need to download it externally and place it in Dataset.
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights="DEFAULT")
# print(vgg16_false)
# print(vgg16_true)
test_dataset = torchvision.datasets.CIFAR10(root = 'Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
vgg16_true.classifier[6]=nn.Linear(1000, 10)
print(vgg16_true)
# 输出结果:
# VGG(
# (features): Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace=True)
# (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (6): ReLU(inplace=True)
# (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (8): ReLU(inplace=True)
# (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (11): ReLU(inplace=True)
# (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (13): ReLU(inplace=True)
# (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (15): ReLU(inplace=True)
# (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (18): ReLU(inplace=True)
# (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (20): ReLU(inplace=True)
# (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (22): ReLU(inplace=True)
# (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (25): ReLU(inplace=True)
# (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (27): ReLU(inplace=True)
# (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (29): ReLU(inplace=True)
# (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
# (classifier): Sequential(
# (0): Linear(in_features=25088, out_features=4096, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=4096, out_features=4096, bias=True)
# (4): ReLU(inplace=True)
# (5): Dropout(p=0.5, inplace=False)
# (6): Linear(in_features=4096, out_features=10, bias=True)
# )
# )
















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











