









简介
为何要生成pb文件,大家应该有所了解吧,这里是提供Android的调用,即将Tensorflow训练好了的模型结构和参数移植到Android手机上。
训练
读取原始图片过程,将其ratio=0.2为校验样本,0.8的比重为训练样本。设置图片宽w = 200,高h = 150,通道c=3,类别数量n_classes = 2。这里提供了transform.resize(img, (h, w, c))将不同的图片大小统一为宽w = 200,高h = 150。
w = 200
h = 150
c = 3
n_classes = 2
path = 'D:\\AutoSparePart\\ToFinall_Data\\'
def read_img(path):
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
imgs = []
labels = []
for idx, folder in enumerate(cate):
for im in glob.glob(folder + '/*.jpg'):
print('reading the image: %s' % (im))
img = io.imread(im)
img = transform.resize(img, (h, w, c))
imgs.append(img)
labels.append(idx)
return np.asarray(imgs, np.float32), np.asarray(labels, np.int32)
data, label = read_img(path)
num_example = data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
data = data[arr]
label = label[arr]
ratio = 0.8
s = np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
x_val = data[s:]
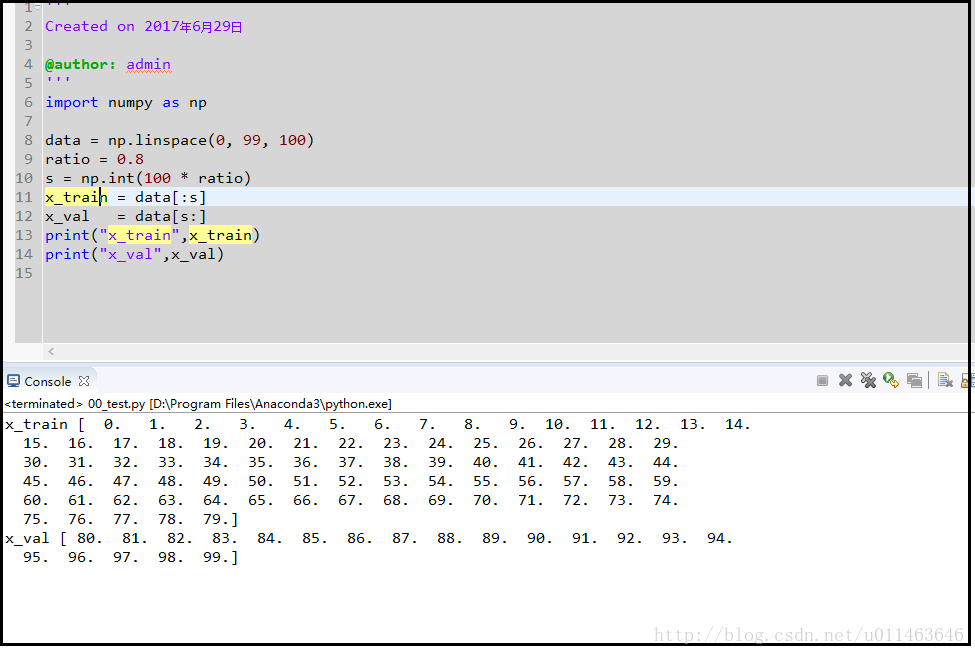
y_val = label[s:]这里是把图片的顺序打乱,取前num_example * ratio和后num_example * (1-ratio),最后赋值回原来的data和label.示意图:
定义神经网络模型:
def build_network(height, width, channel):
x = tf.placeholder(tf.float32, shape=[None, height, width, channel], name='input')
y = tf.placeholder(tf.int64, shape=[None, n_classes], name='labels_placeholder')
def weight_variable(shape, name="weights"):
initial = tf.truncated_normal(shape, dtype=tf.float32, stddev=0.1)
return tf.Variable(initial, name=name)
def bias_variable(shape, name="biases"):
initial = tf.constant(0.1, dtype=tf.float32, shape=shape)
return tf.Variable(initial, name=name)
def conv2d(input, w):
return tf.nn.conv2d(input, w, [1, 1, 1, 1], padding='SAME')
def pool_max(input):
return tf.nn.max_pool(input,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool1')
def fc(input, w, b):
return tf.matmul(input, w) + b
# conv1
with tf.name_scope('conv1_1') as scope:
kernel = weight_variable([3, 3, c, 64])
biases = bias_variable([64])
output_conv1_1 = tf.nn.relu(conv2d(x, kernel) + biases, name=scope)
with tf.name_scope('conv1_2') as scope:
kernel = weight_variable([3, 3, 64, 64])
biases = bias_variable([64])
output_conv1_2 = tf.nn.relu(conv2d(output_conv1_1, kernel) + biases, name=scope)
pool1 = pool_max(output_conv1_2)
# conv2
with tf.name_scope('conv2_1') as scope:
kernel = weight_variable([3, 3, 64, 128])
biases = bias_variable([128])
output_conv2_1 = tf.nn.relu(conv2d(pool1, kernel) + biases, name=scope)
with tf.name_scope('conv2_2') as scope:
kernel = weight_variable([3, 3, 128, 128])
biases = bias_variable([128])
output_conv2_2 = tf.nn.relu(conv2d(output_conv2_1, kernel) + biases, name=scope)
pool2 = pool_max(output_conv2_2)
# conv3
with tf.name_scope('conv3_1') as scope:
kernel = weight_variable([3, 3, 128, 256])
biases = bias_variable([256])
output_conv3_1 = tf.nn.relu(conv2d(pool2, kernel) + biases, name=scope)
with tf.name_scope('conv3_2') as scope:
kernel = weight_variable([3, 3, 256, 256])
biases = bias_variable([256])
output_conv3_2 = tf.nn.relu(conv2d(output_conv3_1, kernel) + biases, name=scope)
with tf.name_scope('conv3_3') as scope:
kernel = weight_variable([3, 3, 256, 256])
biases = bias_variable([256])
output_conv3_3 = tf.nn.relu(conv2d(output_conv3_2, kernel) + biases, name=scope)
pool3 = pool_max(output_conv3_3)
'''
# conv4
with tf.name_scope('conv4_1') as scope:
kernel = weight_variable([3, 3, 256, 512])
biases = bias_variable([512])
output_conv4_1 = tf.nn.relu(conv2d(pool3, kernel) + biases, name=scope)
with tf.name_scope('conv4_2') as scope:
kernel = weight_variable([3, 3, 512, 512])
biases = bias_variable([512])
output_conv4_2 = tf.nn.relu(conv2d(output_conv4_1, kernel) + biases, name=scope)
with tf.name_scope('conv4_3') as scope:
kernel = weight_variable([3, 3, 512, 512])
biases = bias_variable([512])
output_conv4_3 = tf.nn.relu(conv2d(output_conv4_2, kernel) + biases, name=scope)
pool4 = pool_max(output_conv4_3)
# conv5
with tf.name_scope('conv5_1') as scope:
kernel = weight_variable([3, 3, 512, 512])
biases = bias_variable([512])
output_conv5_1 = tf.nn.relu(conv2d(pool4, kernel) + biases, name=scope)
with tf.name_scope('conv5_2') as scope:
kernel = weight_variable([3, 3, 512, 512])
biases = bias_variable([512])
output_conv5_2 = tf.nn.relu(conv2d(output_conv5_1, kernel) + biases, name=scope)
with tf.name_scope('conv5_3') as scope:
kernel = weight_variable([3, 3, 512, 512])
biases = bias_variable([512])
output_conv5_3 = tf.nn.relu(conv2d(output_conv5_2, kernel) + biases, name=scope)
pool5 = pool_max(output_conv5_3)
'''
#fc6
with tf.name_scope('fc6') as scope:
shape = int(np.prod(pool3.get_shape()[1:]))
kernel = weight_variable([shape, 100])
#kernel = weight_variable([shape, 4096])
#biases = bias_variable([4096])
biases = bias_variable([100])
pool5_flat = tf.reshape(pool3, [-1, shape])
output_fc6 = tf.nn.relu(fc(pool5_flat, kernel, biases), name=scope)
#fc7
with tf.name_scope('fc7') as scope:
#kernel = weight_variable([4096, 4096])
#biases = bias_variable([4096])
kernel = weight_variable([100, 100])
biases = bias_variable([100])
output_fc7 = tf.nn.relu(fc(output_fc6, kernel, biases), name=scope)
#fc8
with tf.name_scope('fc8') as scope:
#kernel = weight_variable([4096, n_classes])
kernel = weight_variable([100, n_classes])
biases = bias_variable([n_classes])
output_fc8 = tf.nn.relu(fc(output_fc7, kernel, biases), name=scope)
finaloutput = tf.nn.softmax(output_fc8, name="softmax")
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=finaloutput, labels=y))*100
optimize = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost)
prediction_labels = tf.argmax(finaloutput, axis=1, name="output")
read_labels = y
correct_prediction = tf.equal(prediction_labels, read_labels)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
correct_times_in_batch = tf.reduce_sum(tf.cast(correct_prediction, tf.int32))
return dict(
x=x,
y=y,
optimize=optimize,
correct_prediction=correct_prediction,
correct_times_in_batch=correct_times_in_batch,
cost=cost,
accuracy=accuracy,
)
这里修改了VGG-16,因为可以自己定制。。。想要几层就几层,值得注意的是,必须注明x = tf.placeholder(tf.float32, shape=[None, height, width, channel], name=’input’)的name,因为是给Android调用时提供的接口。同理,finaloutput = tf.nn.softmax(output_fc8, name=”softmax”)为输出概率,prediction_labels = tf.argmax(finaloutput, axis=1, name=”output”)为预测的值。
接着是训练过程:
def train_network(graph, batch_size, num_epochs, pb_file_path):
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
epoch_delta = 10
for epoch_index in range(num_epochs):
for i in range(400):
sess.run([graph['optimize']], feed_dict={
graph['x']: np.reshape(x_train[i], (1, h, w, c)),
graph['y']: ([[1, 0]] if y_train[i] == 0 else [[0, 1]])
})
if epoch_index % epoch_delta == 0:
total_batches_in_train_set = 0
total_correct_times_in_train_set = 0
total_cost_in_train_set = 0.
for i in range(12):
return_correct_times_in_batch = sess.run(graph['correct_times_in_batch'], feed_dict={
graph['x']: np.reshape(x_train[i], (1, h, w, c)),
graph['y']: ([[1, 0]] if y_train[i] == 0 else [[0, 1]])
})
mean_cost_in_batch = sess.run(graph['cost'], feed_dict={
graph['x']: np.reshape(x_train[i], (1, h, w, c)),
graph['y']: ([[1, 0]] if y_train[i] == 0 else [[0, 1]])
})
total_batches_in_train_set += 1
total_correct_times_in_train_set += return_correct_times_in_batch
total_cost_in_train_set += (mean_cost_in_batch * batch_size)
total_batches_in_test_set = 0
total_correct_times_in_test_set = 0
total_cost_in_test_set = 0.
for i in range(3):
return_correct_times_in_batch = sess.run(graph['correct_times_in_batch'], feed_dict={
graph['x']: np.reshape(x_val[i], (1, h, w, c)),
graph['y']: ([[1, 0]] if y_val[i] == 0 else [[0, 1]])
})
mean_cost_in_batch = sess.run(graph['cost'], feed_dict={
graph['x']: np.reshape(x_val[i], (1, h, w, c)),
graph['y']: ([[1, 0]] if y_val[i] == 0 else [[0, 1]])
})
total_batches_in_test_set += 1
total_correct_times_in_test_set += return_correct_times_in_batch
total_cost_in_test_set += (mean_cost_in_batch * batch_size)
acy_on_test = total_correct_times_in_test_set / float(total_batches_in_test_set * batch_size)
acy_on_train = total_correct_times_in_train_set / float(total_batches_in_train_set * batch_size)
print('Epoch - {:2d}, acy_on_test:{:6.2f}%({}/{}),loss_on_test:{:6.2f}, acy_on_train:{:6.2f}%({}/{}),loss_on_train:{:6.2f}'.format(
epoch_index, acy_on_test*100.0,total_correct_times_in_test_set,
total_batches_in_test_set * batch_size,
total_cost_in_test_set,
acy_on_train * 100.0,
total_correct_times_in_train_set,
total_batches_in_train_set * batch_size,
total_cost_in_train_set))
if epoch_index % 50 == 0:
constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def, ["output"])
with tf.gfile.FastGFile(pb_file_path, mode='wb') as f:
f.write(constant_graph.SerializeToString())最后两句是把训练好的模型保存为pb文件。运行完之后就会发现应该的pb_file_path下文件夹多出了一个pb文件。
测试
'''
Created on 2017年9月9日
@author: admin
'''
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import PIL.Image as Image
from skimage import transform
W = 200
H = 150
def recognize(jpg_path, pb_file_path):
with tf.Graph().as_default():
output_graph_def = tf.GraphDef()
with open(pb_file_path, "rb") as f:
output_graph_def.ParseFromString(f.read()) #rb
_ = tf.import_graph_def(output_graph_def, name="")
with tf.Session() as sess:
tf.global_variables_initializer().run()
input_x = sess.graph.get_tensor_by_name("input:0")
print (input_x)
out_softmax = sess.graph.get_tensor_by_name("softmax:0")
print (out_softmax)
out_label = sess.graph.get_tensor_by_name("output:0")
print (out_label)
img = np.array(Image.open(jpg_path).convert('L'))
img = transform.resize(img, (H, W, 3))
plt.imshow(img)
plt.show()
img = img * (1.0 /255)
img_out_softmax = sess.run(out_softmax, feed_dict={input_x:np.reshape(img, [-1, H, W, 3])})
print ("img_out_softmax:",img_out_softmax)
prediction_labels = np.argmax(img_out_softmax, axis=1)
print ("prediction_labels:",prediction_labels)
recognize("D:/AutoSparePart/ToFinall_Data/0/crop_or_pad020.jpg", "./output/autosparepart.pb")这里并没有写出网络结构,因为pb文件里有。
总结不足
1、每次训练都要重新读取图片,耗时较长,建议制作为tfrecord格式,或者修改为如下文件读取改进方法的格式,在制作成batch时才读取图片数据;
2、每次训练时不是形成一个batch形式,而是sess.run([graph['optimize']], feed_dict={ graph['x']: np.reshape(x_train[i], (1, 224, 224, 3)),训练不充分;
3、一次性将图片数据读入,可能导致内存不足 img = transform.resize(img, (w, h, c)) imgs.append(img)
文件读取改进方法:
def get_files(file_dir):
cats = []
label_cats = []
dogs = []
label_dogs = []
for file in os.listdir(file_dir):
name = file.split(sep='.')
if name[0] == 'cat':
cats.append(file_dir+file)#读取猫所在位置名称
label_cats.append(0)#labels标签为0
else:
dogs.append(file_dir+file)#读取猫所在位置名称
label_dogs.append(1)#labels标签为0
print("There are %d cats \n There are %d dogs"%(len(cats),len(dogs)))
image_list = np.hstack((cats,dogs))
label_list = np.hstack((label_cats,label_dogs))
temp = np.array([image_list,label_list])
temp = temp.transpose()#原来transpose的操作依赖于shape参数,对于一维的shape,转置是不起作用的.
np.random.shuffle(temp)#随机排列 注意调试时不用
image_list = list(temp[:,0])
label_list = list(temp[:,1])
label_list = [int(i) for i in label_list]
return image_list,label_list形成batch:
def get_batch(image,label,image_W,image_H,batch_size,capacity):
'''
image:image_list
label:label_list
image_W:width
image_H:height
batch_size:batch size
capacity:the maximum in queue
Return :
image batch 4D tensor:[batch_size,width,height,3] rgb dtype=tf.float32 ----------------- image_batch
label batch 1D tensor:[batch_size] type=tf.int32---------------------------------------label_batch
'''
image = tf.cast(image,tf.string)#numpy格式转换为tf格式
label = tf.cast(label,tf.int32)
#make an input queue
input_queue = tf.train.slice_input_producer([image,label])#整合队列 tf.train.slice_input_producer(tensor_list, num_epochs默认inf循环, shuffle, seed, capacity, shared_name, name)
label = input_queue[1]
image_contents = tf.read_file(input_queue[0])#读取image
image = tf.image.decode_jpeg(image_contents,channels=3)#解码jpg
#data argumentation should go to here#
# tf.image.random_flip_left_right #
# tf.random_crop #
# tf.image.random_brightness #
# tf.image.random_contrast #
# tf.image.per_image_whitening #
################################
# image = tf.random_crop(image, [24, 24, 3])# randomly crop the image size to 24 x 24
# image = tf.image.random_flip_left_right(image)
# image = tf.image.random_brightness(image, max_delta=63)
# image = tf.image.random_contrast(image,lower=0.2,upper=1.8)
image = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H)#reshape image W H
image = tf.image.per_image_standardization(image)#standardization 注意调试时不用
image_batch,label_batch = tf.train.batch([image,label],batch_size=batch_size,num_threads=64,capacity=capacity)#num_threads线程
# image_batch,label_batch = tf.train.shuffle_batch([image,label],batch_size=batch_size,num_threads=64,capacity=capacity, min_after_dequeue=capacity-1)#打乱数据
label_batch = tf.reshape(label_batch, [batch_size])
return image_batch,label_batch注意事项:
这里提供了粗糙的模板,需要根据实际修改,由于时间有限,没有给出以上相符的代码。注意这里的代码针对的图片是将猫狗的图片放在了同一个文件夹里,以“cat.0111”、“dog.0111”区分。而第一个读取是将不同分类的图片放在两个文件夹里:

举一反三
同理,我们可以训练手写字符集MNIST的模型,这里提供了MNIST的训练代码:
#!/usr/bin/env python
#coding: utf-8
import tensorflow as tf
import input_data
from tensorflow.python.framework import graph_util
def build_network(height,width):
"""
Function:构建网络模型。
Parameters
----------
height: Mnist图像的宽。
width: Mnist图像的宽。
"""
x = tf.placeholder(tf.float32, [None, height, width], name='input')
y_placeholder = tf.placeholder(tf.float32, shape=[None, 10],name='labels_placeholder')
keep_prob_placeholder = tf.placeholder(tf.float32, name='keep_prob_placeholder')
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
x_image = tf.reshape(x, [-1,height, width,1])
# First Convolutional Layer
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# Second Convolutional Layer
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# Third Convolutional Layer
W_conv3 = weight_variable([5, 5, 64, 128])
b_conv3 = bias_variable([128])
h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)
h_pool3 = max_pool_2x2(h_conv3)
# Densely Connected Layer
shape = h_pool3.get_shape().as_list()
print("shape[1]*shape[2]*shape[3]=", (shape[1], shape[2], shape[3]))
W_fc1 = weight_variable([shape[1] * shape[2] * shape[3], 1024])
b_fc1 = bias_variable([1024])
print("W_fc1.get_shape().as_list()",W_fc1.get_shape().as_list())
h_pool3_flat = tf.reshape(h_pool3, [-1,W_fc1.get_shape().as_list()[0]])
# h_pool2_flat = tf.reshape(h_pool3, [-1, 4*4*128])
h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, W_fc1) + b_fc1)
# Dropout
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob_placeholder)
# Readout Layer
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
logits = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
sofmax_out = tf.nn.softmax(logits,name="out_softmax")
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=y_placeholder))
optimize = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cost)
prediction_labels = tf.argmax(sofmax_out, axis=1,name="output")
real_labels= tf.argmax(y_placeholder, axis=1)
correct_prediction = tf.equal(prediction_labels, real_labels)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#一个Batch中预测正确的次数
correct_times_in_batch = tf.reduce_sum(tf.cast(correct_prediction, tf.int32))
return dict(
keep_prob_placeholder = keep_prob_placeholder,
x_placeholder= x,
y_placeholder = y_placeholder,
optimize = optimize,
logits = logits,
prediction_labels = prediction_labels,
real_labels = real_labels,
correct_prediction = correct_prediction,
correct_times_in_batch = correct_times_in_batch,
cost = cost,
accuracy = accuracy,
)
def train_network(graph,
dataset,
batch_size,
num_epochs,
pb_file_path,):
"""
Function:训练网络。
Parameters
----------
graph: 一个dict,build_network函数的返回值。
dataset: 数据集
batch_size:
num_epochs: 训练轮数。
pb_file_path:要生成的pb文件的存放路径。
"""
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print ("batch size:",batch_size)
#用于控制每epoch_delta轮在train set和test set上计算一下accuracy和cost
epoch_delta = 10
for epoch_index in range(num_epochs):
#################################
# 获取TRAIN set,开始训练网络
#################################
for (batch_xs,batch_ys) in dataset.train.mini_batches(batch_size):
sess.run([graph['optimize']], feed_dict={
graph['x_placeholder']: batch_xs,
graph['y_placeholder']: batch_ys,
graph['keep_prob_placeholder']:0.5,
})
#每epoch_delta轮在train set和test set上计算一下accuracy和cost
if epoch_index % epoch_delta == 0:
#################################
# 开始在 train set上计算一下accuracy和cost
#################################
#记录训练集中有多少个batch
total_batches_in_train_set = 0
#记录在训练集中预测正确的次数
total_correct_times_in_train_set = 0
#记录在训练集中的总cost
total_cost_in_train_set = 0.
for (train_batch_xs,train_batch_ys) in dataset.train.mini_batches(batch_size):
return_correct_times_in_batch = sess.run(graph['correct_times_in_batch'], feed_dict={
graph['x_placeholder']: train_batch_xs,
graph['y_placeholder']: train_batch_ys,
graph['keep_prob_placeholder']:1.0,
})
mean_cost_in_batch = sess.run(graph['cost'], feed_dict={
graph['x_placeholder']: train_batch_xs,
graph['y_placeholder']: train_batch_ys,
graph['keep_prob_placeholder']:1.0,
})
total_batches_in_train_set += 1
total_correct_times_in_train_set += return_correct_times_in_batch
total_cost_in_train_set += (mean_cost_in_batch*batch_size)
#################################
# 开始在 test set上计算一下accuracy和cost
#################################
#记录测试集中有多少个batch
total_batches_in_test_set = 0
#记录在测试集中预测正确的次数
total_correct_times_in_test_set = 0
#记录在测试集中的总cost
total_cost_in_test_set = 0.
for (test_batch_xs,test_batch_ys) in dataset.test.mini_batches(batch_size):
return_correct_times_in_batch = sess.run(graph['correct_times_in_batch'], feed_dict={
graph['x_placeholder']: test_batch_xs,
graph['y_placeholder']: test_batch_ys,
graph['keep_prob_placeholder']:1.0,
})
mean_cost_in_batch = sess.run(graph['cost'], feed_dict={
graph['x_placeholder']: test_batch_xs,
graph['y_placeholder']: test_batch_ys,
graph['keep_prob_placeholder']:1.0,
})
total_batches_in_test_set += 1
total_correct_times_in_test_set += return_correct_times_in_batch
total_cost_in_test_set += (mean_cost_in_batch*batch_size)
### summary and print
acy_on_test = total_correct_times_in_test_set / float(total_batches_in_test_set * batch_size)
acy_on_train = total_correct_times_in_train_set / float(total_batches_in_train_set * batch_size)
print('Epoch - {:2d} , acy_on_test:{:6.2f}%({}/{}),loss_on_test:{:6.2f}, acy_on_train:{:6.2f}%({}/{}),loss_on_train:{:6.2f}'.
format(epoch_index, acy_on_test*100.0,total_correct_times_in_test_set,
total_batches_in_test_set * batch_size,total_cost_in_test_set, acy_on_train*100.0,
total_correct_times_in_train_set,total_batches_in_train_set * batch_size,total_cost_in_train_set))
# 每轮训练完后就保存为pb文件
if epoch_index % 50 == 0:
constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph_def, ["output"]) #out_softmax
with tf.gfile.FastGFile(pb_file_path,mode='wb') as f:
f.write(constant_graph.SerializeToString())
def main():
batch_size = 30
num_epochs = 101
#pb文件保存路径
pb_file_path = "output/mnist-tf1.0.1.pb"
g = build_network(height=28, width=28)
dataset = input_data.read_data_sets()
train_network(g, dataset, batch_size, num_epochs, pb_file_path)
main()结构是很相似的!!!
input_data.py:
#!/usr/bin/env python
#coding: utf-8
import numpy as np
import mnist_loader
import collections
Datasets = collections.namedtuple('Datasets', ['train', 'test'])
class DataSet(object):
def __init__(self,
images,
labels):
self._num_examples = images.shape[0]
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def mini_batches(self,mini_batch_size):
"""
return: list of tuple(x,y)
"""
# Shuffle the data
perm = np.arange(self._num_examples)
np.random.shuffle(perm)
self._images = self._images[perm]
self._labels = self._labels[perm]
n = self.images.shape[0]
mini_batches = [(self._images[k:k+mini_batch_size],self._labels[k:k+mini_batch_size])
for k in range(0, n, mini_batch_size)]
if len(mini_batches[-1]) != mini_batch_size:
return mini_batches[:-1]
else:
return mini_batches
def _next_batch(self, batch_size, fake_data=False):
"""Return the next `batch_size` examples from this data set."""
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Shuffle the data
perm = np.arange(self._num_examples)
np.random.shuffle(perm)
self._images = self._images[perm]
self._labels = self._labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def read_data_sets():
"""
Function:读取训练集(TrainSet)和测试集(TestSet)。
Notes
----------
TrainSet: include imgs_train and labels_train.
TestSet: include imgs_test and labels_test.
the shape of imgs_train and imgs_test are:(batch_size,height,width). namely (n, 28L, 28L)
the shape of labels_train and labels_test are:(batch_size,num_classes). namely (n, 10L)
"""
imgs_train, imgs_test, labels_train, labels_test = mnist_loader.read_data_sets()
train = DataSet(imgs_train, labels_train)
test = DataSet(imgs_test, labels_test)
return Datasets(train=train, test=test)
def _test():
dataset = read_data_sets()
print ("dataset.train.images.shape:",dataset.train.images.shape)
print ("dataset.train.labels.shape:",dataset.train.labels.shape)
print ("dataset.test.images.shape:",dataset.test.images.shape)
print ("dataset.test.labels.shape:",dataset.test.labels.shape)
print (dataset.test.images[0])
print (dataset.test.labels[0])
# _test()minist_loader.py:
#!/usr/bin/env python
#coding: utf-8
import gzip
import numpy
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)[0]
def _extract_images(f):
"""Extract the images into a 4D uint8 numpy array [index, y, x, depth].
Args:
f: A file object that can be passed into a gzip reader.
Returns:
data: A 4D unit8 numpy array [index, y, x].
Raises:
ValueError: If the bytestream does not start with 2051.
"""
print('Extracting', f.name)
with gzip.GzipFile(fileobj=f) as bytestream:
magic = _read32(bytestream)
if magic != 2051:
raise ValueError('Invalid magic number %d in MNIST image file: %s' %
(magic, f.name))
num_images = _read32(bytestream)
rows = _read32(bytestream)
cols = _read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8)
data = data.reshape(num_images, rows, cols)
data = numpy.multiply(data, 1.0 / 255.0)
return data
def _dense_to_one_hot(labels_dense, num_classes):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
def _extract_labels(f, one_hot=False, num_classes=10):
"""Extract the labels into a 1D uint8 numpy array [index].
Args:
f: A file object that can be passed into a gzip reader.
one_hot: Does one hot encoding for the result.
num_classes: Number of classes for the one hot encoding.
Returns:
labels: a 1D unit8 numpy array.
Raises:
ValueError: If the bystream doesn't start with 2049.
"""
print('Extracting', f.name)
with gzip.GzipFile(fileobj=f) as bytestream:
magic = _read32(bytestream)
if magic != 2049:
raise ValueError('Invalid magic number %d in MNIST label file: %s' %
(magic, f.name))
num_items = _read32(bytestream)
buf = bytestream.read(num_items)
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
labels = _dense_to_one_hot(labels, num_classes)
return labels
def read_data_sets():
TRAIN_IMAGES = './data/train-images-idx3-ubyte.gz'
TRAIN_LABELS = './data/train-labels-idx1-ubyte.gz'
TEST_IMAGES = './data/t10k-images-idx3-ubyte.gz'
TEST_LABELS = './data/t10k-labels-idx1-ubyte.gz'
local_file = TRAIN_IMAGES
with open(local_file, 'rb') as f:
train_images = _extract_images(f)
local_file = TRAIN_LABELS
with open(local_file, 'rb') as f:
train_labels = _extract_labels(f, one_hot=True)
local_file = TEST_IMAGES
with open(local_file, 'rb') as f:
test_images = _extract_images(f)
local_file = TEST_LABELS
with open(local_file, 'rb') as f:
test_labels = _extract_labels(f, one_hot=True)
return train_images, test_images, train_labels, test_labels
# read_data_sets()
参考
【1】如何用Tensorflow训练模型成pb文件和和如何加载已经训练好的模型文件 - Jason Zhou - CSDN博客
http://blog.csdn.net/u014432647/article/details/75276718
【2】TensorFlow的训练模型在Android和Java的应用及调用 - 依然范特西 - CSDN博客
http://blog.csdn.net/jay100500/article/details/72802910?locationNum=14&fps=1
【3】将 TensorFlow 移植到 Android手机,实现物体识别、行人检测和图像风格迁移详细教程 - 玛莎鱼的博客 - CSDN博客
http://blog.csdn.net/masa_fish/article/details/54097796
【4】基于TensorFlow的MNIST手写数字识别与Android移植–tensorflow,android,Android,pb,节点
http://dev.dafan.info/detail/380102?p=17
















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











