






本文整理了1952年~2021年间,n=139个机器学习系统的开发日期和训练参数量的信息。据我们所知,这是同类中最大的公共数据集。您可以在此处访问我们的数据集,生成交互式可视化的代码在此处可用。
先前的工作表明, 参数量是衡量模型性能的重要变量,它可以代表模型复杂性,并且它通常是随时可用或很容易从模型架构描述中得到的信息。
- 在2011-2012年,任何领域的模型大小增长趋势都没有中断。这表明深度学习的发展不是由于算法的改进,而是相比于其他方法,机器学习方法的更好的利用了性能。
- 在2016-2018之间的某个时间,语言模型的模型复杂性出现了中断。增加规模的回报变大了,成长轨迹从约1.5年的倍增时间,改为4至8个月的倍增时间。
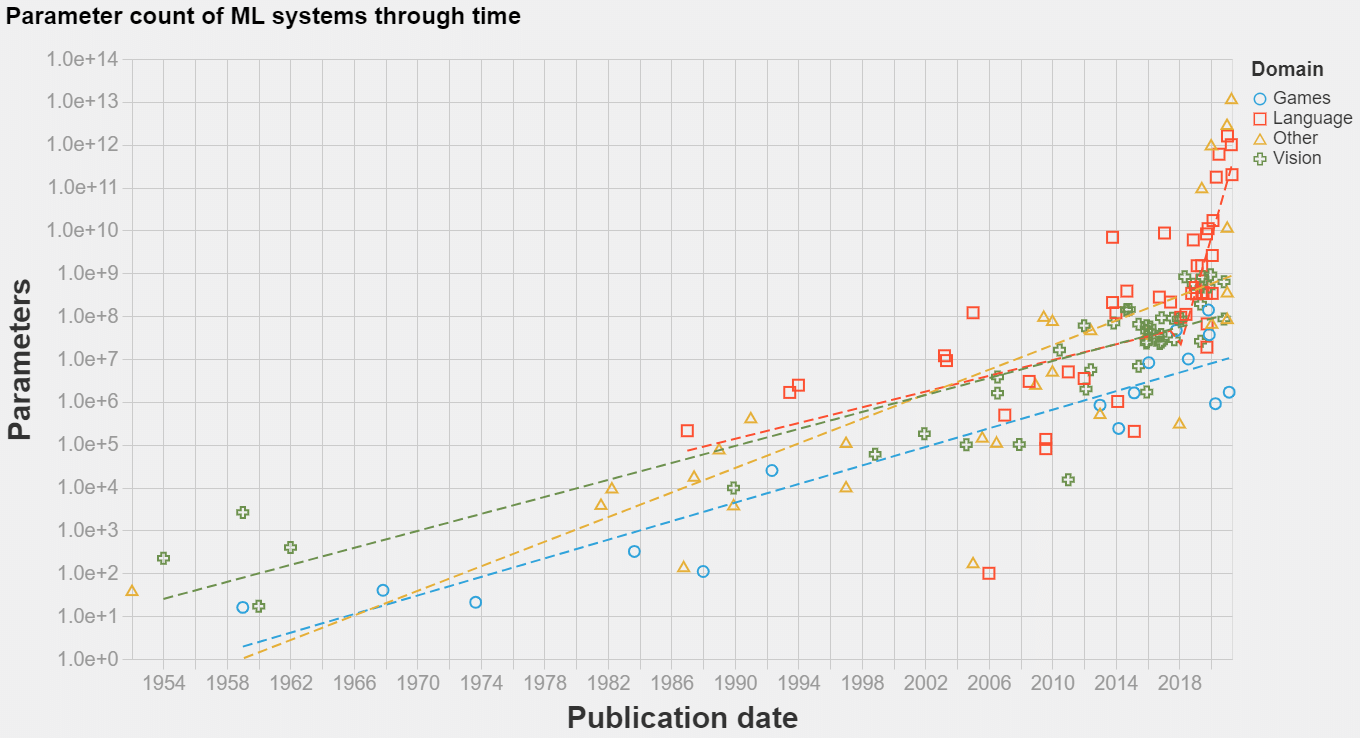
1954年至2021年间流行的机器学习系统的模型大小。包括n=139个数据点。

2000年至2021年流行的机器学习系统的模型大小。包括n=114个数据点。
不出所料,模型大小呈上升趋势。这种趋势似乎是指数级的,而且最近语言模型的速度似乎加快了。从2000年到2016-2018年,所有领域模型的翻倍率在18至24个月之间,在2016-2018年以后,语言模型领域的翻倍率在3至5个月之间。
在可训练参数方面,可以在语言和推荐系统领域找到最大的模型。我们找到的最大模型是来自Facebook的12万亿参数深度学习推荐系统。
语言模型在历史上一直比其他领域更大。这是因为统计模型的参数和词汇量成比例。
可以说,深度学习在到达语言处理之前(大约2011-2013年)就开始在计算机视觉中激增,然而,第二个的参数数量远远超过了今天第一个的参数数量。特别是,在2016-2018年间,语言模型规模的增长趋势明显大大加快了其速度,达到了4到8个月的翻番时间。
游戏领域的架构在可训练参数方面很小,低于视觉架构,但显然以类似的节奏增长。
决定模型大小的是规模的回报;在更复杂的领域中,我们应该期望更低的有效模型大小,因为模型在其他方面受到更多的约束。
在2011-2012年过渡到深度学习时代的过程中,模型规模的增长趋势一直相对稳定(尽管考虑到数据量,很难确定)。这表明,深度学习革命与其说是范式的改变,不如说是现有的自然延续。
原文地址:Parameter counts in Machine Learning — AI Alignment Forum














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









