






 文章介绍了字节公司开发的一种训练框架,通过自动故障识别、诊断测试和快速恢复机制,确保在大量GPU集群中训练任务的稳定性和效率,即使面对硬件和软件故障,也能在最少干预下实现容错并减少训练进度损失。
文章介绍了字节公司开发的一种训练框架,通过自动故障识别、诊断测试和快速恢复机制,确保在大量GPU集群中训练任务的稳定性和效率,即使面对硬件和软件故障,也能在最少干预下实现容错并减少训练进度损失。
随着训练集群扩展到超过数万个GPU,软件和硬件故障几乎不可避免。字节引入了一个健壮的训练框架,实现了自动故障识别和快速恢复,在最少的人为干预下实现了容错,并且对正在进行的训练任务的影响可以忽略不计。
1. 训练流程
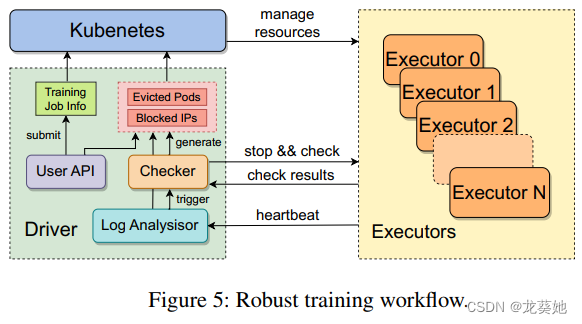
- 分配资源:在接收到提交的训练任务后,driver进程会与自定义的Kubernetes接口,为每个executor分配计算资源并启动相应的Pod。
- 创建训练:一个executor管理一个节点。一旦executor完成了一系列的初始化任务,它就会在每个GPU上创建训练进程,并创建一个训练守护进程,该守护进程定期向driver发送心跳。这些心跳封装了各种形式的信息,以实现实时异常检测并发出早期警告(第4.2节)。
- 定期检测异常:当driver在特定的训练过程中检测到异常状态,或者在预定的时间窗口内没有收到执行器的心跳时,触发故障恢复流程。
- 异常诊断:driver将暂停所有执行器上正在进行的训练任务,并命令它们运行一系列自检诊断(第4.3节)。这些诊断测试经过精心设计,既轻量级又全面,涵盖了大多数常见的硬件和软件故障。
- 替换节点:一旦确定了有问题的节点,驱动程序就会向Kubernetes提交要阻止的节点的IP地址,以及在其上运行的Pod的信息,Kubernetes会驱逐有问题的节点,并使用通过诊断测试的等量的健康节点来补充集群。
- 手动诊断:可以通过用户界面,手动驱逐节点,特别是对于那些通过手动分析识别的节点,如第5节。
- 恢复训练:driver从最新的检查点恢复训练。我们优化了检查点和恢复流程,以尽量减少训练进度的损失(第4.4节)
2. 数据采集和分析
心跳消息包括:
- executor的基本信息,如IP地址、Pod名称、硬件信息等
- 训练进程的当前状态,使驱动程序能够及时发现任何明显的异常。
- 训练过程的stdout/stderr日志。它们将被即时汇总、过滤和分析。如果检测到特定的警告或错误关键字,驱动程序将报告实时诊断信息。
- 包括RDMA流量指标,作为网络利用率和效率的指标。训练过程中的一些异常可能不会表现为显式错误,从而给出训练正在按预期进行的外观。在这种情况下,RDMA流量指标作为一个关键指标。鉴于训练任务的周期性,每个步骤的网络流量特征应该表现出相似的模式。因此,RDMA流量的任何显著下降或异常波动都是潜在异常的信号。一旦检测到此类违规行为,驾驶员将发出警报,进行人工调查。如果流量完全停止,驱动程序将自动启动故障恢复程序。
为了加强对训练稳定性和运动成绩的监控,我们研制了精度达到毫秒级的监控系统。采用不同级别的监控来跟踪各种指标。
秒级监控通常用于评估整体健康状态,并排除常见配置对训练的影响。例如,ECN/PFC/QoS配置、链路振荡或任何其他网卡问题。
毫秒级监控则是用来判断网络是否拥堵,数据并行和管道并行的数据传输速度是否达到物理极限。
3. 诊断测试
在自检诊断中,存在执行时间和精度之间的折衷。
延长的诊断持续时间会对有效的训练时间产生不利影响,而高误报率会导致不必要地排除实际上正常工作的机器。
通过迭代实验和优化,我们部署了一套轻量级诊断测试,有效地覆盖了实际训练过程中遇到的各种硬件和软件故障。
主机内网络测试。为了诊断主机内网络中的潜在瓶颈,我们使用内部开发的工具来测试两件事。
- 环回测试测量:从所有RDMA NIC(RNIC)到各种主机内端点(包括内存节点和GPU)的环回带宽。它在主机内进行全网状测试,覆盖所有可能的链路组合。这使我们能够根据端到端带宽结果推断出PCIe配置中特定于链路的带宽降级和不规则性。
- 第二个RNIC-to-RNIC测试检查同一主机上不同RNIC之间的连接和带宽性能。这些。测试可以深入了解RNIC是否符合硬件速度规格,以及底层路由配置正确。
NCCL测试。为了识别GPU通信中的潜在故障,我们在单个节点中的GPU之间运行了一个all2all的测试,以观察带宽是否与预期的基准对齐。一旦主机内通信测试通过,每个节点还将与同一ToR交换机下的相邻机器进行all-reduce测试,以评估节点间GPU通信。
4. 快速的checkpoint和恢复
在识别和驱逐故障机器之后,驱动程序需要通过从最近的检查点加载模型权重和优化器状态来恢复训练。关键是确保最新的检查点尽可能接近故障发生时的训练进度状态,以尽量减少计算和时间上的损失。这就要求我们在训练过程中增加检查点的频率。
但是,我们也希望减少检查点过程引入的延迟,特别是关键路径上的时间,因为它阻碍了训练的进度,从而阻碍了整体系统的吞吐量。为了实现快速检查点,我们引入了一种优化的两阶段方法。
- 在第一阶段,每个GPU worker将其片上状态写入主机内存,然后继续训练过程(片上->片外)。在优化了Pytorch的序列化机制并使用了pinned memory后,由于PCIe带宽高(多少?),这个过程可以缩短到几秒,从而最大限度地中断正在进行的训练过程。
- 在第二阶段,一个后台进程接管,将状态从主机内存异步传输到分布式文件系统(我们部署中的HDFS)进行集中维护(片外内存->远程mem)。这种将操作解耦为两个阶段的做法允许GPU工作进程在转储其状态后几乎立即恢复训练,而将更耗时的写入HDFS的过程卸载到一个单独的非阻塞进程。
固定内存pinned memory,或者不可分页内存,它的一个重要特点是操作系统,不会对这块内存分页、并交换到磁盘上,从而保证了内存始终驻留在物理内存中。
所以,操作系统能够安全地使某个应用程序访问该内存的物理地址,因为这块内存将不会被破坏或者重新定位。
从检查点恢复的上下文中,没有最后一个检查点就无法开始训练,因为它位于关键路径上。
这里的瓶颈是HDFS的带宽,特别是当每个GPU工作节点需要读取其对应的状态分区时。为了缓解这一瓶颈,我们提出了一种优化的数据检索策略。
多个GPU worker经常共享相同的状态分区,例如,相同数据并行组中的worker。相应地,我们指定组中的单个worker从HDFS读取共享状态分区。然后,该worker将状态分区广播给共享相同数据的所有其他GPU worker。这种方法有效地缓解了HDFS的带宽限制,从而大大减少了恢复时间。
5. 使用CUDA事件监视器进行性能诊断
在数万GPU的规模下,我们观察到,与较小规模的实验不同,不同的运行表现出不同的计算效率。
即使使用相同的配置,这种不一致性仍然存在,如图6所示。我们还观察到,在这种规模下,训练任务的性能并不一致。随着时间的推移,各种训练任务的MFU逐渐下降。虽然这导致我们怀疑单个机器之间的差异,但在单个GPU GEMM微基准下没有检测到明显的差异。为了诊断这些性能问题,我们开发了一个性能分析工具,它记录了运行期间每个机器上关键代码段的执行时间。与之前的工具(如火炬分析器或MegatronLM计时器)相比,我们的工具基于CUDA事件方法对事件进行计时。这种方法最大限度地减少了对CUDA同步的需求,从而防止了性能下降,允许我们在生产训练作业中始终如一地运行它。该工具提供了两种可视化模式,可以从不同的角度对收集到的数据进行分析。

















 1622
1622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









