







 本文详细介绍了累积匹配曲线(CMC)的概念及其在生物特征识别系统中的应用,并通过实例展示了如何使用Matlab编程实现CMC曲线。
本文详细介绍了累积匹配曲线(CMC)的概念及其在生物特征识别系统中的应用,并通过实例展示了如何使用Matlab编程实现CMC曲线。
CMC曲线全称是Cumulative Match Characteristic (CMC) curve,也就是累积匹配曲线,同ROC曲线Receiver Operating Characteristic (ROC) curve一样,是模式识别系统,如人脸,指纹,虹膜等的重要评价指标,尤其是在生物特征识别系统中,一般同ROC曲线一起给出,能够综合评价出算法的好坏。如下图所示:
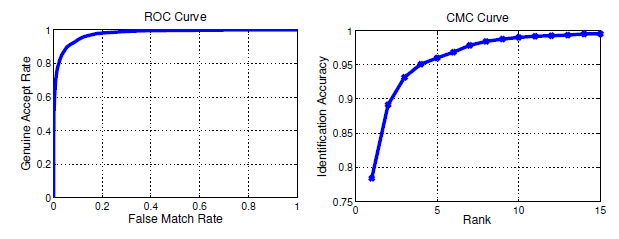
那么,CMC曲线的原理是什么?怎样编程实现?下面将进行详解。
CMC曲线原理
CMC曲线综合反映了分类器的性能,它的评价指标与现在deep learning中常用的top1 err或top5 err评价指标一样的意思,不同的是这里Rank1 recognition rate表示的是正确率而不是错误率,两者的关系是
Rank1识别率=1-top1 err
Rank5识别率=1-top5 err
它们表示的是什么意思呢?就比如给你一个选择题,有10个选项,但是只有一个选项是正确的,现在让你从中选出正确答案。如果让你猜一次,正确的概率为1/10,你感觉自己状态不好,想从猜一次,现在给你机会,让你再猜一次,现在你总共猜两次,选两个答案,正确率一下子提高到1/5,你又说了,猜两次反映不出你的水平,你要猜五次,也就是从10个选项中选5个选项,这5个选项中包括正确选项的概率大大增加,变为1/2,如果让你猜10次,那蒙对的概率肯定为1了,也有人蒙的能力比较强,可能猜3次就能猜到正确答案,也就是提前收敛到1。CMC曲线Rank1识别率就是表示按照某种相似度匹配规则匹配后,第一次就能判断出正确的标签的数目与总的测试样本数目之比,Rank5识别率就是指前五项(按照匹配程度从大到小排列后)有正确匹配。如果一个样本按照匹配程度从大到小排列后,到最后一项,才匹配到正确标签,这就说明分类器不太好,把最应匹配的判别成最不应匹配的。语言表述有点苍白,还是看具体实现吧。
Matlab编程实现
现设match_dist=NxM的矩阵,其中N为测试样本(test set)数,M为训练样本(training set)数,根据某种相似度匹配规则,如距离或概率或score等,得到的一个匹配矩阵match_dist。示例如下:

具体代码如下:
%处理测试样本与注册的训练样本匹配的相似度矩阵
match_scores = zeros(length(num_test),length(num_class));
true_labels = zeros(length(num_test),length(num_class));
for i=1:length(num_test)
for j=1:length(num_class)
[x,y]=find(num_class(j)==num_train);
%选取匹配程度的中值
label_distances(i,j) = median(match_dist(i,y));
if num_test(i)==num_class(j)
true_labels(i,j)=1;
end
end
end
%生成CMC
max_rank = length(num_class);
%Rank取值范围
ranks = 1:max_rank;
%排序
label_distances_sort = zeros(length(num_test),length(num_class));
true_labels_sort = zeros(length(num_test),length(num_class));
for i=1:length(num_test)
[label_distances_sort(i,:), ind] = sort(label_distances(i,:));
true_labels_sort(i,:) = true_labels(i,ind);
end
%迭代
rec_rates = zeros(1,max_rank);
tmp = 0;
for i=1:max_rank
tmp = tmp + sum(true_labels_sort(:,i));
rec_rates(1,i)=tmp/length(num_test);
end num_test

num_class

num_train

然后,根据已得数据可以直接plot即可得CMC曲线:
plot(1:max_rank,rec_rates)

看上去不太美观,可以根据set调整一下如下:
hold on
set(gca,'XLim',[1 40]);%X轴的数据显示范围
set(gca,'YLim',[0.6 1]);%X轴的数据显示范围
%set(gca,'XTickLabel',[1:5:40]);%给坐标加标签
title('CMC曲线')
xlabel('Rank')
ylabel('Recognition Rate')

参考:

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









