










BatchNormalization是神经网络中常用的参数初始化的方法。其算法流程图如下:

我们可以把这个流程图以门电路的形式展开,方便进行前向传播和后向传播:
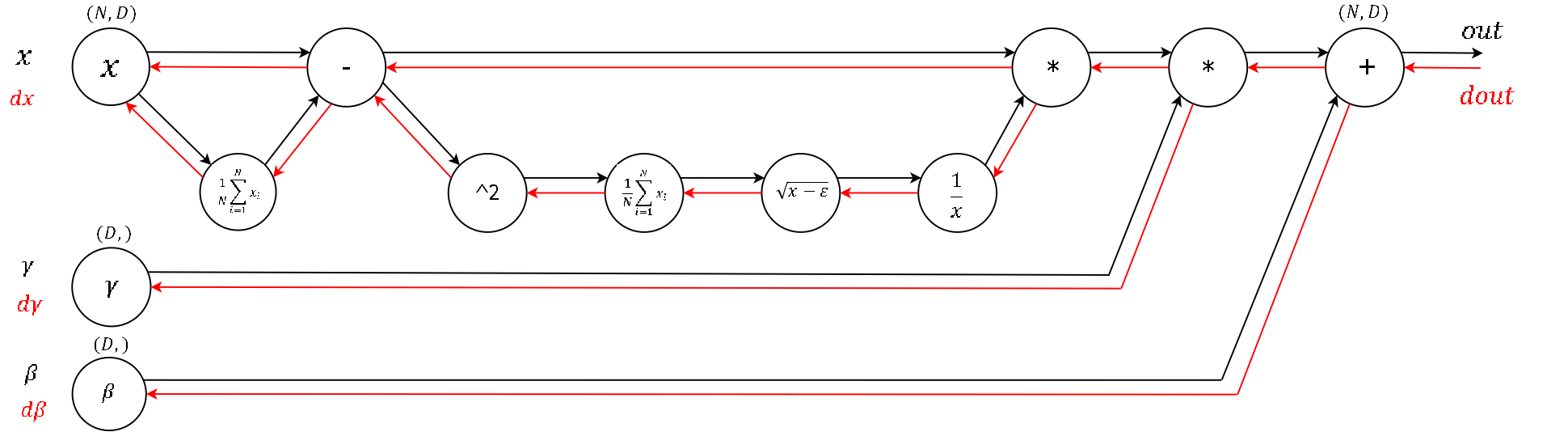
那么前向传播非常简单,直接给出代码:
def batchnorm_forward(x, gamma, beta, eps):
N, D = x.shape
#为了后向传播求导方便,这里都是分步进行的
#step1: 计算均值
mu = 1./N * np.sum(x, axis = 0)
#step2: 减均值
xmu = x - mu
#step3: 计算方差
sq = xmu ** 2
var = 1./N * np.sum(sq, axis = 0)
#step4: 计算x^的分母项
sqrtvar = np.sqrt(var + eps)
ivar = 1./sqrtvar
#step5: normalization->x^
xhat = xmu * ivar
#step6: scale and shift
gammax = gamma * xhat
out = gammax + beta
#存储中间变量
cache = (xhat,gamma,xmu,ivar,sqrtvar,var,eps)
return out, cache
def batchnorm_backward(dout, cache):
#解压中间变量
xhat,gamma,xmu,ivar,sqrtvar,var,eps = cache
N,D = dout.shape
#step6
dbeta = np.sum(dout, axis=0)
dgammax = dout
dgamma = np.sum(dgammax*xhat, axis=0)
dxhat = dgammax * gamma
#step5
divar = np.sum(dxhat*xmu, axis=0)
dxmu1 = dxhat * ivar #注意这是xmu的一个支路
#step4
dsqrtvar = -1. /(sqrtvar**2) * divar
dvar = 0.5 * 1. /np.sqrt(var+eps) * dsqrtvar
#step3
dsq = 1. /N * np.ones((N,D)) * dvar
dxmu2 = 2 * xmu * dsq #注意这是xmu的第二个支路
#step2
dx1 = (dxmu1 + dxmu2) 注意这是x的一个支路
#step1
dmu = -1 * np.sum(dxmu1+dxmu2, axis=0)
dx2 = 1. /N * np.ones((N,D)) * dmu 注意这是x的第二个支路
#step0 done!
dx = dx1 + dx2
return dx, dgamma, dbeta要注意的就是求导时遇到多个支路的情况要进行累加。表达式复杂的话还是分步进行比较不容易出错。















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









