







损失函数(loss function) = 误差部分(loss term) + 正则化部分(regularization term)
1. 误差部分
1.1 gold term,0-1损失函数,记录分类错误的次数
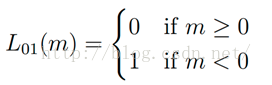
1.2 Hinge loss, 折叶损失,关于0的阀值
定义:E(z)=max(0,1-z)
应用: SVM中的最大化间隔分类,max-margin loss最大边界损失
举例: SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值delta.
比如第i个样本数据为xi和其正确类别标签yi, 通过公式f(xi,W)来计算属于不同类别的分数, 针对第j个类别的得分为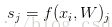
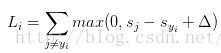
SVM的损失函数想要正确分类类别yi的分数比不正确类别分数高.且至少要高delta.若不满足这个要求,便计算损失值.
平方折叶损失SVM(L2-SVM),使用的误差部分为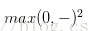
1.3 Log loss
定义:
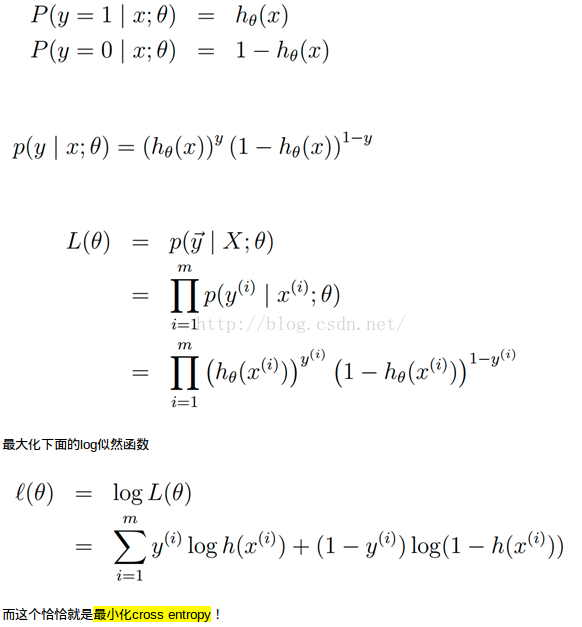
应用场景: logistic regression,cross entropy error
1.4 squared loss
定义:
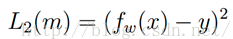
应用场景: linear regression
1.5 exponential loss
定义:
应用场景: boosting
2. 正则化部分
若损失函数只包含误差部分,可能存在多个W;有时希望向某些特定的权重W添加一些偏好,对其它权重则不添加,以此来消除模糊性; 为了解决上述问题, 在误差部分基础上添加正则化惩罚(regularization penalty)部分.
最常用的正则化惩罚是L2范式, L2范式通过对所有参数进行逐元素的平方惩罚来抑制大数值的权重,公式如下:
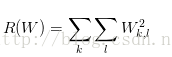
正则化部分仅仅基于权重,与数据无关.
正则化最好的性质是对大数值权重进行惩罚,提升模型泛化能力,因为这意味着没有哪个维度能够独自对于整体分值有过大的影响,避免产生过拟合.
**与权重不同,偏差没有这样的效果,因为它们并不控制输入维度上的影响强度,因此正则化部分只针对权重.
***由于正则化部分的存在,不可能所有的例子都能得到0的损失值,这是因为只有当W=0的特殊情况下,损失值才为0.
应用举例:多分类SVM
其完整损失公式:

SVM损失函数采用了一种特殊的方法使得能够衡量对于训练数据分类和实际分类标签的一致性.
设置delta: 超参数delta在绝大多数情况下设为0.1,超参数delta和lamda看起来是两个不同的超参数,但实际上它们一起控制同一个权衡: 损失函数中的数据损失和正则化损失之间的权衡; 当将W中值缩小,分类分值之间的差异也变小,反之亦然; 因此, 不同分类分值之间的边界的具体值delta=1或delta-100从某些角度是没有意义的,因为权重就可以控制差异变大和缩小.即真正的权衡是允许权重能够变大到何种程度,通过正则化强度lamda来控制.
多分类SVM和二元SVM的关系:
二元SVM对第i个数据的损失计算公式为:

此公式是多分类公式只有2个类别的特例, 这里的C和多类SVM公式中的lamda控制着同样的权衡,即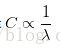
多类SVM有多种损失函数,这里只是其中一种;
One-VS-ALL(OVA)SVM: 针对每个类和其他类训练一个独立的二元分类器,常用.
All-vs-All(AVA) SVM: 很少用
structured SVM: 将正确分类的分类分值和非正确分类中的最高分值的边界最大化
SVM和Softmax分类器是最常用的两个分类器.
Softmax分类器可以理解为逻辑回归分类器面对多个分类的一般话归纳.
1.SVM将输出作为对每个分类的评分(没有规定的标准,难以直接解释);
2. softmax的输出(归一化的分类概率)更加直观,且可以从概率上解释.
在Softmax分类器中, 函数映射保持不变,但将这些评分值看做每个分类未归一化的对数概率,且将折叶损失替换为交叉熵损失(cross-entropy loss),公式如下:
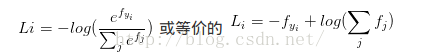
表示分类评分向量f中的第i个元素,和SVM一样,整个数据集的损失值是数据集中所有样本数据的损失值Li的均值和正则化损失之和.
概率论解释:
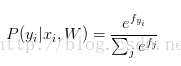
实际操作注意事项:数值稳定:编程实现softmax函数计算的时候,中间项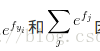
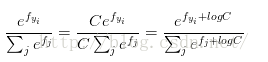
C的值可自由选择,不会影响计算结果,通过这个技巧可以提高计算中的数值稳定性.通常将C设为: 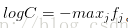
该技巧就是将向量f中的数值进行平移,使得最大值为0.
SVM/Softmax的比较
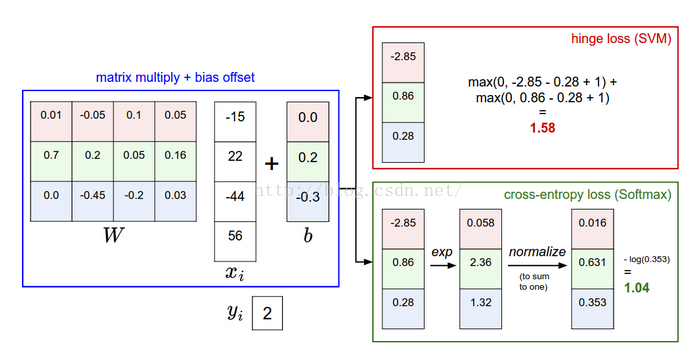
Softmax分类器为每个分类器提供了"可能性":SVM的计算是无标定的,且难以针对所有分类的评分值给出直观解释;softmax分类器不同,它允许计算出对于所有分类标签的可能性.

实际使用中, SVM和Softmax是很相似的,一般地,两者的表现差别很小;
但是想对于softmax,SVM更加局部目标化,这既是一个特点,也是一个劣势;考虑一个评分是[10,-2,3]的数据,其中第一个分类是正确的,那么SVM(delta=1)会看到正确分类相对于不正确分类的差值已经比边界值要高,因此损失值为0,SVM对于数字个体细节不care,[10,-100,-100]或[10,9,9],对SVM没有差,因为只要差值超过边界值,那么损失值为0.
对于softmax分类器,对于[10,9,9]而言,计算出的损失值远远高于[10,-100,-100].换言之,softmax分类器对于分数永远不会满意;正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小.
SVM只要边界值满足就满意了,不会超过限制去细微地操作具体分数.
参考:https://zhuanlan.zhihu.com/p/21102293?refer=intelligentunit














 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









