






2024-10-28,为科学文档中的实体和关系抽取领域带来了突破,提供了一个包含106篇完整科学出版物、超过24,000个实体和12,000个关系的大规模数据集,这对于构建科学知识图谱和促进科学信息抽取技术的发展具有重要意义。
数据集地址:SciER|科学信息提取数据集|人工智能数据集
一、研究背景:
在科学文档中,实体(如数据集、方法、任务)和它们之间的关系对于理解科学发现和推动研究进展至关重要。然而,现有的科学信息抽取(SciIE)数据集往往规模较小,且缺乏细粒度的关系标注,这限制了SciIE技术的发展和应用。
目前遇到困难和挑战:
1、现有的科学文档信息抽取数据集规模有限,难以支持深度学习模型的训练和评估。
2、缺乏细粒度的关系类型定义,使得模型难以捕捉实体间的复杂交互。
3、科学文档的实体和关系抽取任务需要处理大量的领域特定知识和术语,对模型的领域适应性提出了挑战。
数据集地址:SciER|科学信息提取数据集|人工智能数据集
二、让我们一起看一下SciER数据集:
SciER是一个大规模的科学文档数据集,专注于从科学出版物中提取数据集、方法和任务实体及其相互关系。
包含了106篇完整的科学出版物,涵盖了超过24,000个实体和12,000个关系。数据集通过细粒度的关系类型,描述了数据集、方法和任务实体之间的交互关系。
数据集构建 :
SciER数据集的构建过程中,研究者们采用了SciDMT注释方案,定义了三种类型的实体:数据集(DATASET)、方法(METHOD)和任务(TASK)。关系标注则定义了九种细粒度的标签集,以建立实体间的交互关系。
数据集特点:
SciER数据集的特点在于其大规模和细粒度的关系类型定义,这为科学文档的实体和关系抽取任务提供了丰富的标注信息,有助于提高模型的精确性和可解释性。
SciER数据集可以用于训练和评估SciIE模型,特别是端到端的关系抽取模型。数据集随机划分为训练集、开发集和测试集,适用于监督学习方法和基于大型语言模型(LLM)的方法。
基准测试 :
研究者们在SciER数据集上进行了综合评估实验,包括最新的监督基线模型和基于LLM的基线模型,以展示该任务的挑战性。
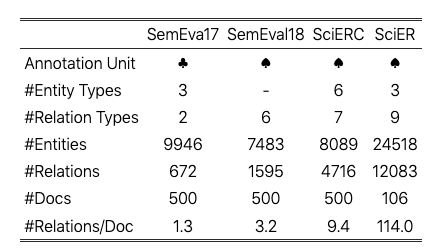
SciER 与科学文本中支持 NER 和 RE 的 3 个数据集的比较。注释单位: ♣ =段落, ♠ =摘要, ♠ =全文。
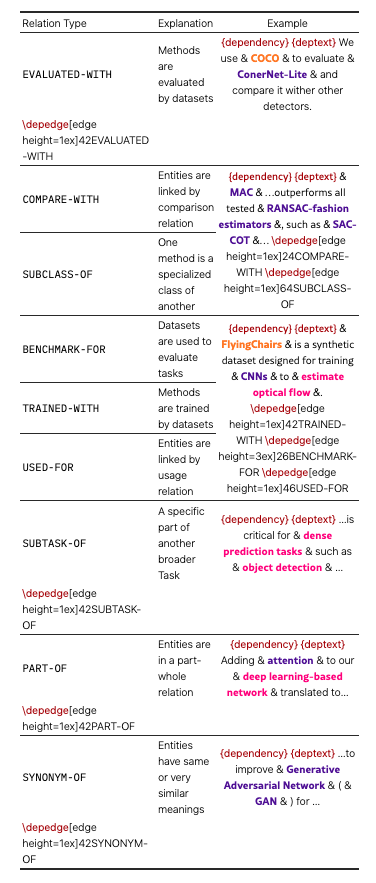
DATASET、METHOD 和 TASK 实体的语义关系类型。

NER、RE 和联合实体和关系提取 (ERE) 的 LLM 上下文学习(小样本)基线的总体架构(第一)。NER(第二个)、RE(第三个)和联合 ER(第四个)的少数镜头提示模板。
三、让我们一起展望SciER数据集应用
以前我写无人机的科学论文,特别是涉及到图像识别领域的,那真是个苦差事。每次我都需要手动搜索一大堆文献,就为了找到那些被广泛使用的数据集和效果最好的方法。比如说,我得去各种数据库里搜“无人机图像识别”、“数据集”、“深度学习”这些关键词,然后一篇篇地翻论文,看看大家都用了哪些数据集,哪些方法效果不错。
我为了验证我的无人机目标检测算法,需要找到一些具有挑战性的环境数据集。我不得不手动浏览数十篇论文,就为了找出那些在复杂地形中测试过的无人机数据集。我得逐篇检查论文中的实验部分,看看他们使用了哪些数据集,然后自己评估这些数据集是否适合我的研究。这个过程既繁琐又容易出错。
有了SciER数据集训练的系统之后
当我需要找到无人机领域的相关信息时,我只需向系统提出我的需求,它就能迅速为我提供一份详细的清单。
比如,我输入“我想要找在复杂地形中测试过的无人机图像识别数据集和方法”,系统就能立刻给我反馈。它不仅列出了相关数据集的名称,还提供了哪些论文引用过这些数据集,以及不同方法的性能对比。这就像是有了一个专门为我定制的文献综述助手,大大节省了我搜索和阅读的时间。
最棒的是,系统还能帮我识别出这些数据集和方法之间的具体关系。比如,它会告诉我某个数据集是被用来评估哪种方法的,或者某个方法在哪些特定环境下效果最好。这样,我不仅能快速找到所需的信息,还能深入理解这些数据集和方法之间的联系。
有了SciER数据集训练的系统,我写论文的效率大大提高,也能更专注于我的研究创新,而不是花费大量时间在文献搜索上。
来吧,让我们走进:SciER|科学信息提取数据集|人工智能数据集
免费数据集网站:遇见数据集
遇见数据集是一个平台,致力于让每个数据集都被发现,让每一次遇见都有价值,
1、数据获取的便利性:
遇见数据集通过集中整合全球数据资源,提供了一个一站式平台,使得用户能够轻松搜索和访问各种数据集,无需在多个来源之间进行切换,从而提高了数据获取的效率。
2、数据的可发现性:
通过详细的数据标签和分类系统,遇见数据集增强了数据集的可发现性,帮助用户快速找到特定领域的数据集,尤其是对于特定研究领域或应用场景的数据,极大地方便了数据的检索和使用。
3、数据更新的及时性:
遇见数据集频繁更新数据集内容,确保用户能够获取最新的数据资源,这对于需要最新数据进行分析和研究的用户来说尤为重要,保证了数据的时效性和相关性。


















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









