







随着媒体类应用的传播和推广,大量的数据开始堆叠,信息冗余成为当下的主要问题。尤其在互联网、政务、金融、教育、法律、医疗等众多行业中,大量文档信息需要进行数字化及结构化处理,人工处理方式费时费力,同时也容易产生错误。
数据从业者们开始探索利用人工智能技术对自然语言进行处理,来实现数据价值的快速转化。通过先验知识的总结,来指导自然语言的处理,抽取关键信息形成结构化关系,成为深入数据理解的必由之路。信息的抽取一般指从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术,其本质是通过对信息间的实体关系抽取。
本篇文章将聚焦于社会化信息中的信息抽取过程,实现对数据的实体关系挖掘,来提升数据使用方的数据转化能力。
一、实体关系抽取的过程
实体关系抽取是指从文本中识别出实体及其关系的过程。其原理基于自然语言处理和机器学习技术,通常包括以下步骤:
(1)实体识别:在文本中识别出具有特定含义的实体,例如人名、地名、组织机构等。通常采用命名实体识别技术来完成。
(2)关系抽取:根据实体之间的上下文信息和语法结构,推断出它们之间的关系,关系抽取可以采用基于规则的方法或基于机器学习的方法,其中机器学习方法通常采用监督学习或半监督学习。
(3)实体链接:将文本中的实体链接到已知的知识库或数据库中的实体。
(4)结果评估:评估实体识别和关系抽取的性能,包括准确率、召回率、F1值等指标。
举个例子,在政务领域,某市长信箱的负责人员需要每天处理各类意见、建议、投诉、举报等问题,仅靠肉眼很难从如此大量的内容中获取价值信息,这就需要信息抽取技术,来快速提取关键信息,如举报中的人名、时间、地点、问题等,帮助工作人员掌握举报要素,并快速处理。
这个例子的本质就是探索研究文本之间的关系,当前市场上的信息抽取工具主要分为两种,一种是学术研究的,大多基于理论在有限数据集完成验证,在大面积应用方面缺少实践。另一种是产业化应用的,比如百度的飞桨Paddle、NLPIR、pipeline等,在一定领域完成了知识的迁移、信息抽取模型等开发与验证,并对数据做领域性的标注。
二、实体关系抽取的实现
在实体关系抽取的工具中,PaddleUIE具有良好的实体抽取效果,UIE实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。该模型可以支持通用领域和抽取目标的关键信息抽取,实现零样本快速冷启动,也可以进行小样本微调,快速适配特定的抽取目标。
在这里,我们通过将PaddleUIE封装成一个算子,来支撑对数据抽取处理。以明星影视演员资料的信息为例,准备了如下的数据集:

在数据集中包括演员的基本信息,以及主演的影视作品信息。我们的目标就是尽可能得抽取同类关系数据。
首先在平台中将需要处理的文件(text、word、pdf、excel等)导入平台中。这里我们还是利用文件输入算子来进行数据集的导入,可以支持多文件并行处理。
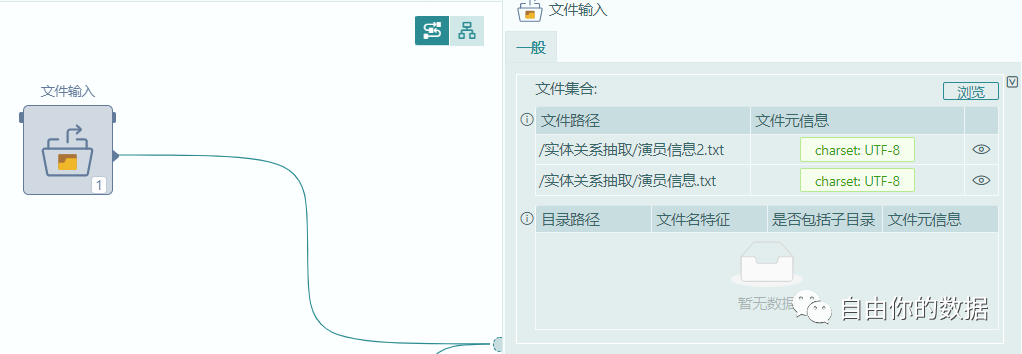
然后经过全文读取将文本加载到内存中,在这里定义了读的模式,平台会自动识别值格式,当该值为bin时,表示以二进制方式读取,将文件读为字节块;当该值为txt时,表示以文本方式读取文件,将文件读为文本块。
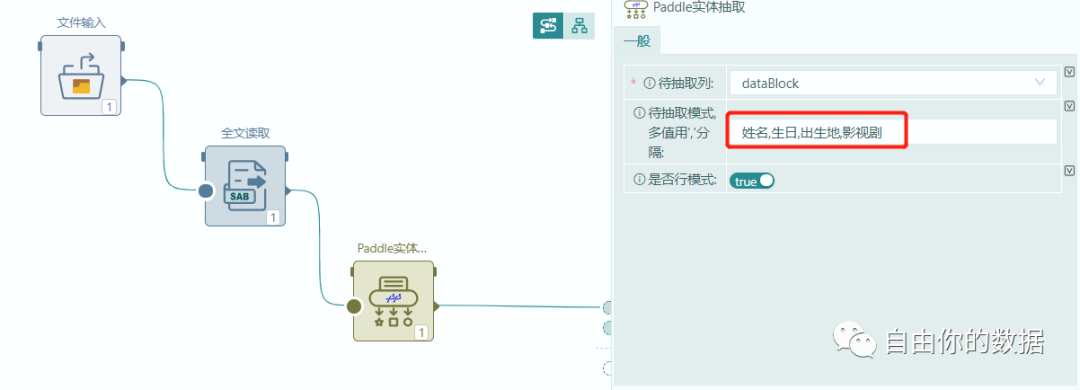
在数据加载到平台后,就可以利用已经封装的Paddle实体抽取算子,来实现内容抽取,基于paddle已经集成的属性关系,只需要定义抽取模式即可,这里定义了“姓名、生日、出生地、影视剧”几个模式值。
待抽取模式一般可以指定抽取多个实体,实体规则间用','号分隔。如在文本中抽取人名、组织,则模式为“人名,组织”。实体识别结果通过列名格式为:columnName+"_entities"列输出,输出结构如下:
{
int gid; // 实体识别的组ID
String schema; // 实体类型
String value; // schema对应的实体
double prob; // 实体的识别概率,该值越高表明可信度越高
int offset; // 实体在文本中的位置
}
数据类型: String
通过以上抽取框架,完成对数据的关系抽取,并通过下图(图1)的对象结构映射实现数据格式的转化,并进行结果的输出(图2)。
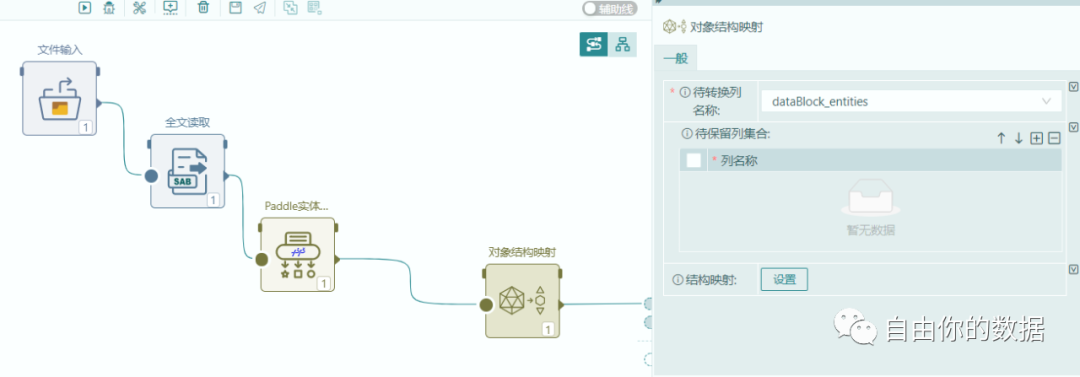
图1
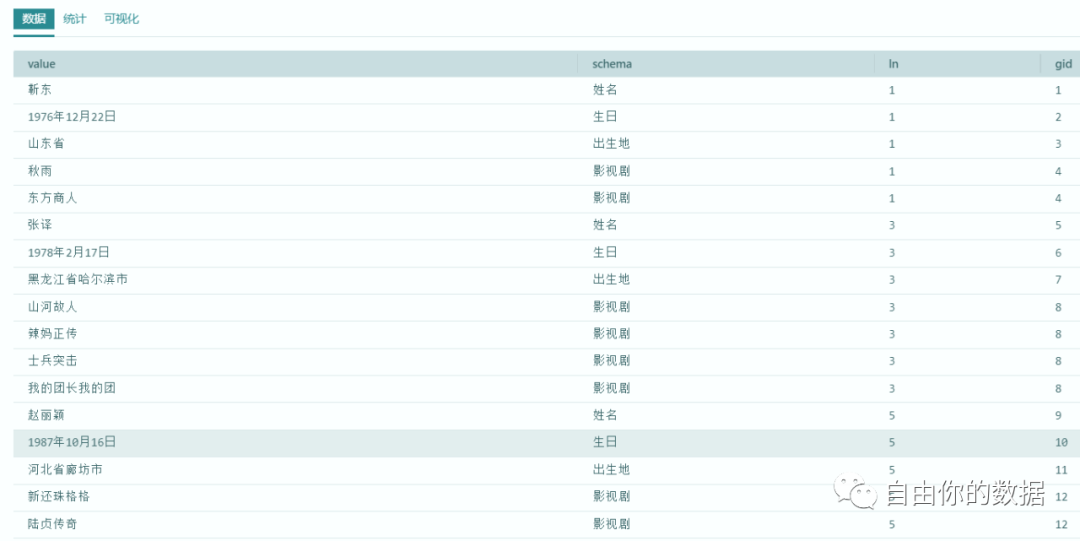
图2
三、综述
实体关系抽取已经成为知识图谱、知识工程、信息检索等领域的重要研究对象,旨在实现自动地从海量文本语料中抽取实体间的语义知识,获取结构化的实体关系知识的体系。通过本平台集成的实体抽取算子(不限于Paddle)来进行数据抽取,总体来看,使用操作上比较简单,不需要太多的知识积累,降低了对数据从业人员自身技能的标准,可以快速的应用在社会化数据的挖掘场景中来。
数由科技是一家数据科学平台提供商,致力于实现数据处理“平民化”的应用。面向大数据产业链,提供数据工厂化、数据管道化、数据运营化、数据治理化、数据可视化的数据价值挖掘解决方案,帮助政府、企业、个人在数据孪生时代激活数据价值。
如需了解更多内容,请加入讨论组
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









