







 本文深入解读《Neural Machine Translation by Jointly Learning To Align and Translate》论文,探讨机器翻译的历史,从基于规则到基于神经网络的转变。文章重点介绍基于注意力机制的神经机器翻译模型,解释其如何解决传统encoder-decoder模型在长句翻译中的问题,以及模型的训练和预测过程。
本文深入解读《Neural Machine Translation by Jointly Learning To Align and Translate》论文,探讨机器翻译的历史,从基于规则到基于神经网络的转变。文章重点介绍基于注意力机制的神经机器翻译模型,解释其如何解决传统encoder-decoder模型在长句翻译中的问题,以及模型的训练和预测过程。
《Neural Machine Translation by Jointly Learning To Align and Translate》阅读心得分享
论文原文链接
《Neural Machine Translation by Jointly Learning To Align and Translate》
论文导读
机器翻译本质上是源语言和目标语言的一种等价信息转换,也成为自动翻译,是将一种语言(源语言)转化为另一种语言的过程。从历史上来看,机器翻译的发展历史经过了三个阶段。在1980年代出现的基于规则的机器翻译、1990年代出现的基于统计的翻译和2013年左右出现的基于神经网络的翻译。基于统计的翻译和基于神经网络的翻译又被称作为基于数据驱动的机器翻译。
最古老的机器翻译方法就是基于规则的机器翻译,在翻译的时候,首先根据源语言的词的词性,然后将词语翻译成目标语言,接着,再使用语法规则,对翻译后的句子进行调整。根据翻译方式的不同,有基于词的方式、基于结构转换的翻译和基于中间语的翻译。举个例子来说,”We do achieve the target“就有可能被翻译为“我们 做 实现 目标”,而实际上“do”只是强调的作用。有限的语法无法覆盖各种各样的语言现象,并且这种实现方法非常依赖于专家的知识。
第二类方法就是基于统计的机器翻译。这种方法通过对语料进行统计分析,构建模型。它的本质是如何找到源语言被翻译成目标语言后,出现最大概率的那句话,也就是对概率进行建模。举个例子来说,“我 已经 看 了 这篇 博客”这句话,就会被翻译成“I have read this blog”。从直观上来说,在翻译的时候,我们可以枚举所有的英文句子来建立概率分布,但这种方法显然是不合适的,因为句子有“无限”多个。在这个时候,我们就引入了隐变量。主流的方法就是2002年提出的“隐变量对数线性模型”,它的方法是设计特征函数,也就是在隐式语言结构上设计特征。
第三类就是基于神经网络的机器翻译。它通过学习大量的成对的语料,让模型可以自己学习语言的特征,找到输入和输出之间的映射。它的核心理念就是建立一种端到端模型(end-to-end),让算法自动找到映射的关系,因此这类方法也被称为表示学习。主流的方法有2014年Kyunghyun等人提出的encoder-decoder模型和Sutskever等人提出的sequence-to-sequence模型。和第二类基于统计的机器翻译方法不一样的地方在于,它并没有引入隐变量,它利用马尔科夫性,将句子生成的概率分解成了各个条件概率的乘积。同时,不像基于统计的机器翻译方法那样是离散形式的建模,它可以对模型进行连续的建模。这也是深度学习带来的革命性的变化。
论文abstract和introduction
神经机器翻译是最近新兴的一种机器翻译的方法。大部分的神经机器翻译都是基于enoder-decoder框架的。并且它们都会将源语言的句子压缩成一个固定的向量,然后传递给decoder。这存在一些潜在的问题,比如,从我们直觉上来感受,如果句子长,那么强行的将句子中的有效信息全部压缩在一个固定的向量中的话,信息肯定会丢失。
于是,该篇论文的作者提出了一种新的方法,这个方法也是基于encoder-decoder的。与之前的encoder-decoder的模型不同之处在于,每次在翻译一个单词的时候,模型会自动的搜寻该单词与源语言哪些单词有关联,并将这种关联的强度进行数字化表示(在模型中就是权重)。并且,实验得出,这种方法可以解决长句子翻译不准的问题(相较于传统的encoder-decoder模型)。
背景-传统RNN Encoder-Decoder模型
传统的RNN Encoder-Decoder模型在训练阶段的时候,会使模型去最大化源语言翻译成目标语言的条件概率。当模型训练好后,当待翻译的源语言句子放入到模型中的时候,模型会自动的计算最大的目标语言句子的概率,并且将这个句子当做是翻译后的句子。下面具体讲一下传统的RNN Encoder-Decoder模型,直接上图,
如上图所示,假设我们有一句待翻译的话,“我/已经/阅读/了/这篇/博客",我们要将它翻译成英文。图中”C“的左侧是encoder,右侧是decoder,”C"是待翻译语句的语义信息。
首先,“我/已经/阅读/了/这篇/博客"这句话会经过encoder,encoder会将这句话进行编码,encoder用到的模型是RNN,RNN的原理可以见我的博客,RNN会通过一个时刻,一个时刻地对“我/已经/阅读/了/这篇/博客"这句话进行编码,当编码结束后,我们会将最后一个时刻的RNN的隐层的输出当做“我/已经/阅读/了/这篇/博客"这句话的语义压缩,在图中也就是C。
接着,解码器每次在产生一个翻译后的英文单词的时候,它都会利用这个编码器的语义压缩C。那具体是如何做到的呢?解码器的模型也是RNN,首先,在时刻为0的时候,RNN会利用语义压缩C,并且这个RNN同时还会接收输入为“”的token来作为这个时刻的输入,接着这个时刻的输出端就会产生第一个单词“I”(这里利用了softmax,输出层是一个词典大小维度的向量,哪个维度的值最大,就取那个维度所对应的单词作为所预测的单词),大家可以想的到,在训练阶段,解码器不可能可以立马产生“I”,而是产生其他的单词,如“tell”等等单词。因此,训练阶段的目的,就是让编码器和解码器的参数,随着训练次数的增加,往“正确”的方向改变,以至于让其产生单词“I”。换句话说,在时刻为0的时候,我们希望解码器产生单词“I”。接着,无论在时刻为0的时候产生什么单词,它都会被当做时刻为1(也就是s1)的输入。因此,如上图,在时刻为1的时候,共有3个输入,一个是C,一个是时刻为0时候产生的隐层结果,最后一个时刻为0的时候的输出。直到这句话产生结束(结束的标志是解码器产生了/s等特殊标志,这个可以在训练的时候指定)。至此,decoder的任务也就完成了。
本文提出的模型-加入了attenton机制的模型
本文提出的模型在文章中叫做RNNsearch模型,流程图如下图所示,
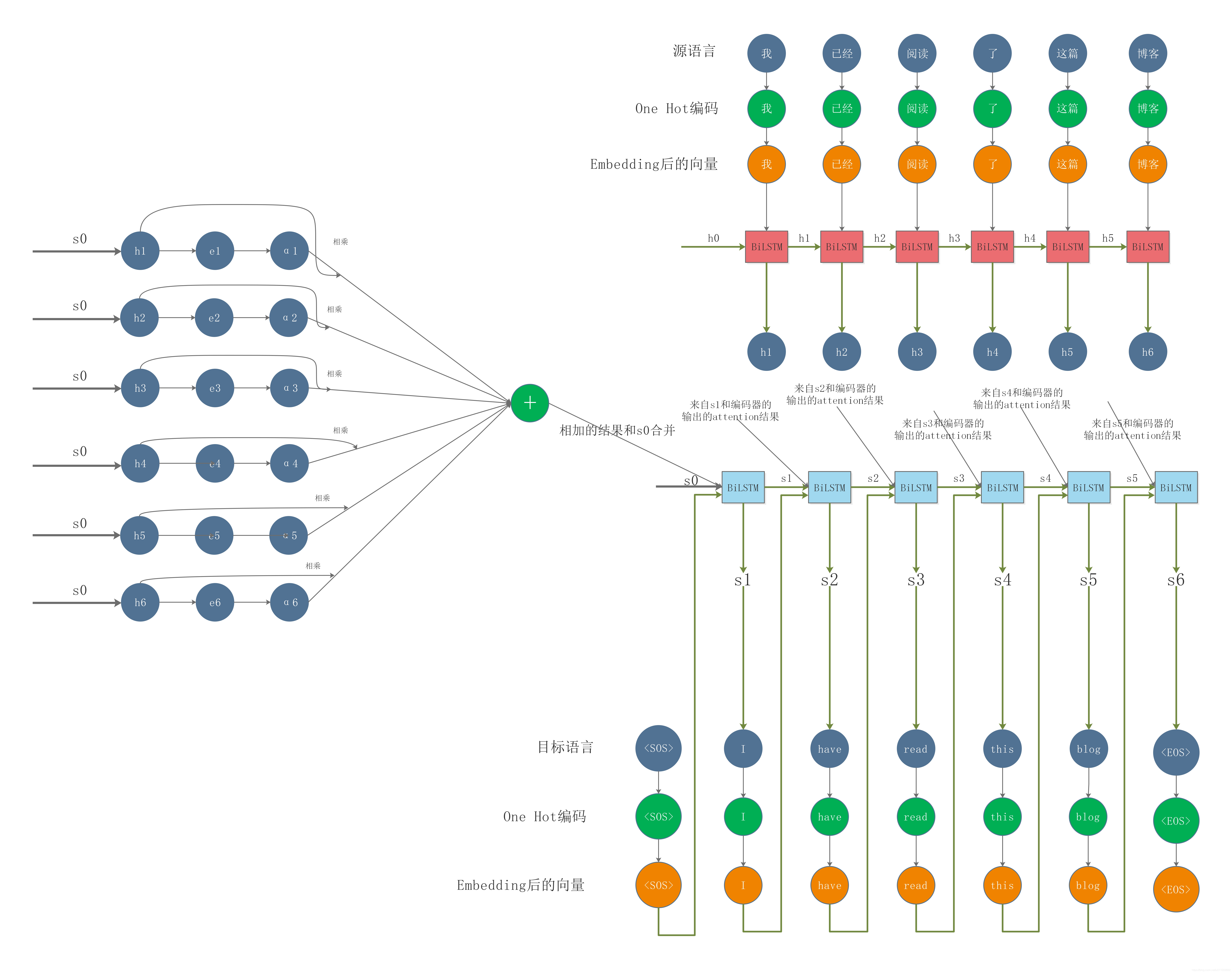
首先,右上角的图片是encoder,这个部分和RNNenc模型是一样的,接着,在decoder部分,就会有巨大的差别。我们以decoder时刻为0时举例子,在时刻为0时,decoder的BiLSTM会接受三个地方的输入,第1个输入的来源是时刻为0时的初始状态s0,这个状态是随机初始化的(无论在训练阶段还是在预测阶段,都是随机的,这个在代码里可以看到)。第2个输入是来源于""这个token的embedding后的向量。第3个输入就有些复杂了,并且,这个第3个输入也就是这篇论文提出的核心创新。第3个输入计算方法如下:
首先,将随机初始化的s0拿来,和encoder所输出的h1~h6,各自做一次余弦相似度的计算(这个计算方式可以自己定义),各自会得到一个e1 ~ e6的数值,然后将6个数值做一次softmax操作,会得到α1 ~ α6,那么我们可以知道,α1+α2+α3+α4+α5+α6=1,因此,我们可以将α1,α2,α3,α4,α5,α6中的每一个,都分别当作是s0和h1 ~ h6的相似度。接着,α1,α2,α3,α4,α5,α6和h1,h2,h3,h4,h5,h6这6个向量分别做一次元素乘积,所得的6个向量再做一次元素的相加,得到最终的向量。接着,就把这个向量当作时刻0时,BiLSTM的第3个输入。这里要注意,代码中的BahdanauAttention机制,实际上是做了一次卷积操作,这个操作等价于上述所讲的attention原理,具体大家可以去百度下BahdanauAttention的原理。
就这样,在时刻为0时,BiLSTM就产生了一个输出。那么此时,时刻就变为了1,接下去的过程就和时刻为0的过程是一样的。大家可以自己仔细理解理解。
代码复现、详细讲解及我的Github地址
完整代码地址:https://github.com/haitaifantuan/nlp_paper_understand
语料预处理
首先,我们要进行的是语料预处理部分。我们可以从我的github地址下载代码以及从腾讯云盘下载数据集,TODO,解压出来后,需要运行的是“data_preprocessing.py”这个模块,详细代码如下,代码主要包含tokenize语料部分、构建token dictionary部分以及将语料从token转换为id部分。tokenize语料部分就是代码中对应的tokenize_corpus(self)这个方法。构建token dictionary部分就是build_token_dictionary(self)这个方法。将语料从token转换为id部分就是convert_data_to_id_pad_eos(self)这个方法。
#coding=utf-8
'''
Author:Haitaifantuan
'''
import os
import nltk
import pickle
import train_args
import collections
class Data_preprocess(object):
def __init__(self):
pass
def tokenize_corpus(self):
'''
该函数的作用是:将英文语料和中文语料进行tokenize,然后保存到本地。
'''
# 将英文语料tokenize,保存下来。
if not os.path.exists(train_args.raw_train_english_after_tokenization_data_path.replace('train.raw.en.after_tokenization.txt', '')):
os.mkdir(train_args.raw_train_english_after_tokenization_data_path.replace('train.raw.en.after_tokenization.txt', ''))
fwrite = open(train_args.raw_train_english_after_tokenization_data_path, 'w', encoding='utf-8')
with open(train_args.raw_train_english_data_path, 'r', encoding='utf-8') as file:
for line in file:
line = line.strip()
line = nltk.word_tokenize(line)
# 将tokenization后的句子写入文件
fwrite.write(' '.join(line) + '\n')
fwrite.close()
# 将中文语料tokenize,保存下来。
if not os.path.exists(train_args.raw_train_chinese_after_tokenization_data_path.replace('train.raw.zh.after_tokenization.txt', '')):
os.mkdir(train_args.raw_train_chinese_after_tokenization_data_path.replace('train.raw.zh.after_tokenization.txt', ''))
fwrite = open(train_args.raw_train_chinese_after_tokenization_data_path, 'w', encoding='utf-8')
with open(train_args.raw_train_chinese_data_path, 'r', encoding='utf-8') as file:
for line in file:
line = line.strip()
line = list(line)
# 将tokenization后的句子写入文件
fwrite.write(' '.join(line) + '\n')
fwrite.close()
print('语料tokenization完成')
def build_token_dictionary(self):
'''
该函数的作用是:根据英文语料和中文语料,建立各自的,以字为单位的token dictionary。
'''
# 生成英文的token_dictionary
english_token_id_dictionary = {}
# 我们定义unk的id是0,unk的意思是,
# 当句子中碰到token dictionary里面没有的token的时候,就转换为这个
english_token_id_dictionary['<unk>'] = 0
english_token_id_dictionary['<sos>'] = 1 # 我们定义sos的id是1
english_token_id_dictionary['<eos>'] = 2 # 我们定义eos的id是1
en_counter = collections.Counter(
) # 创建一个英文token的计数器,专门拿来计算每个token出现了多少次
with open(train_args.raw_train_english_after_tokenization_data_path, 'r', encoding='utf-8') as file:
for line in file:
line = line.strip().split(' ')
for token in line:
en_counter[token] += 1
most_common_en_token_list = en_counter.most_common(train_args.Source_vocab_size - 3) # 找出最常见的Source_vocab_size-3的token
for token_tuple in most_common_en_token_list:
english_token_id_dictionary[token_tuple[0]] = len(english_token_id_dictionary)
# 保存english_token_id_dictionary
if not os.path.exists(train_args.english_token_id_dictionary_pickle_path.replace('english_token_id_dictionary.pickle', '')):
os.mkdir(train_args.english_token_id_dictionary_pickle_path.replace('english_token_id_dictionary.pickle', ''))
with open(train_args.english_token_id_dictionary_pickle_path, 'wb') as file:
pickle.dump(english_token_id_dictionary, file)
# 生成中文的token_dictionary 以及把 tokenization后的结果保存下来
chinese_token_id_dictionary = {}
# 我们定义unk的id是0,unk的意思是,
# 当句子中碰到token dictionary里面没有的token的时候,就转换为这个
chinese_token_id_dictionary['<unk>'] = 0
chinese_token_id_dictionary['<sos>'] = 1 # 我们定义sos的id是1
chinese_token_id_dictionary['<eos>'] = 2 # 我们定义eos的id是1
# 创建一个中文token的计数器,专门拿来计算每个token出现了多少次
zh_counter = collections.Counter()
with open(train_args.raw_train_chinese_after_tokenization_data_path, 'r', encoding='utf-8') as file:
for line in file:
line = line.strip().split(' ')
for token in line:
zh_counter[token] += 1
most_common_zh_token_list = zh_counter.most_common(train_args.Target_vocab_size - 3) # 找出最常见的Target_vocab_size-3的token
for token_tuple in most_common_zh_token_list:
chinese_token_id_dictionary[token_tuple[0]] = len(chinese_token_id_dictionary)
# 保存token_dictionary
if not os.path.exists(train_args.chinese_token_id_dictionary_pickle_path.replace('chinese_token_id_dictionary.pickle', '')):
os.mkdir(train_args.chinese_token_id_dictionary_pickle_path.replace('chinese_token_id_dictionary.pickle', ''))
with open(train_args.chinese_token_id_dictionary_pickle_path, 'wb') as file:
pickle.dump(chinese_token_id_dictionary, file)
print('英文token_dictionary和中文token_dictionary创建完毕')
def convert_data_to_id_pad_eos(self):
'''
该函数的作用是:
将英文语料转换成id形式,并在末尾添加[EOS]
将中文语料转换成id形式,并在句子开头添加[SOS]
'''
# 读取英文的token_dictionary
with open(train_args.english_token_id_dictionary_pickle_path, 'rb') as file:
english_token_id_dictionary = pickle.load(file)
if not os.path.exists(train_args.train_en_converted_to_id_path.replace('train.en.converted_to_id.txt', '')):
os.mkdir(train_args.train_en_converted_to_id_path.replace('train.en.converted_to_id.txt', ''))
fwrite = open(train_args.train_en_converted_to_id_path, 'w', encoding='utf-8')
# 读取tokenization后的英文语料,并将其转换为id形式。
with open(train_args.raw_train_english_after_tokenization_data_path, 'r', encoding='utf-8') as file:
for line in file:
line_converted_to_id = []
line = line.strip().split(' ')
for token in line:
# 将token转换成id
token_id = english_token_id_dictionary.get(
token, english_token_id_dictionary['<unk>'])
line_converted_to_id.append(str(token_id))
# 在英文语料最后加上EOS
line_converted_to_id.append(
str(english_token_id_dictionary['<eos>']))
# 写入本地文件
fwrite.write(' '.join(line_converted_to_id) + '\n')
fwrite.close()
# 读取中文的token_dictionary
with open(train_args.chinese_token_id_dictionary_pickle_path, 'rb') as file:
chinese_token_id_dictionary = pickle.load(file)
if not os.path.exists(train_args.train_zh_converted_to_id_path.replace('train.zh.converted_to_id.txt', '')):
os.mkdir(train_args.train_zh_converted_to_id_path.replace('train.zh.converted_to_id.txt', ''))
fwrite = open(train_args.train_zh_converted_to_id_path, 'w', encoding='utf-8')
# 读取tokenization后的中语料,并将其转换为id形式。
with open(train_args.raw_train_chinese_after_tokenization_data_path, 'r', encoding='utf-8') as file:
for line in file:
line_converted_to_id = []
line = line.strip().split(' ')
for token in line:
# 将token转换成id
token_id = chinese_token_id_dictionary.get(
token, english_token_id_dictionary['<unk>'])
line_converted_to_id.append(str(token_id))
# 因为这个中文语料是当做目标词的,因此也需要在中文语料最后面加上EOS
# decoder的输入的最开始的BOS,会在train.py里面添加。
line_converted_to_id.append(
str(chinese_token_id_dictionary['<eos>']))
# 写入本地文件
fwrite.write(' '.join(line_converted_to_id) + '\n')
fwrite.close()
print('英文语料转换为id并且添加[EOS]标致完毕')
print('中文语料转换为id并且添加[EOS]标致完毕')
# 创建预处理data对象
data_obj = Data_preprocess()
# 将英文语料和中文语料进行tokenization
data_obj.tokenize_corpus()
# 创建英文语料和中文语料的token_dictionary
data_obj.build_token_dictionary()
# 根据token_dictionary将英文语料和中文语料转换为id形式
# 并且在英文语料的最后添加[EOS]标致,在中文语料的最开始添加[SOS]标致
# 并将转化后的语料保存下来
data_obj.convert_data_to_id_pad_eos()
构建模型以及训练模型
语料预处理完成后,我们要做的是构建模型,然后训练模型。这一部分代码在train.py模块中,代码如下,可以看出,要想训练模型,分为3个步骤。
第1个步骤是再次处理下语料,并且搞一个迭代器,每次可以迭代出1个batch_size个样本以供模型训练,这一部分的代码就是class data_batch_generation(object)这个里面。
然后进行第2个步骤,当data_batch_generation()的迭代器构建好后,我们便可以构建模型了,这一部分代码就是class Model(object)这个类里面。
第3个步骤,就是开启一个sesstion,然后开始训练模型的部分。这一部分代码存在于创建session_config这个变量开始到最后。
#coding=utf-8
'''
Author:Haitaifantuan
'''
import tensorflow as tf
import train_args
import os
# 如果有GPU的同学,可以把这个打开,或者自己研究下怎么打开。
#os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 首先判断模型保存的路径存不存在,不存在就创建
if not os.path.exists('./saved_things/'):
os.mkdir('./saved_things/')
if not os.path.exists('./saved_things/doesnt_finish_training_model/'):
os.mkdir('./saved_things/doesnt_finish_training_model/')
if not os.path.exists('./saved_things/finish_training_model/'):
os.mkdir('./saved_things/finish_training_model/')
mt_graph = tf.Graph() # 创建machine translation 专用的graph
data_graph = tf.Graph() # 创建数据专用的graph
class data_batch_generation(object):
def __init__(self):
with data_graph.as_default(): # 定义在这个图下面创建模型
# 通过tf.data.TextLineDataset()来读取训练集数据
self.src_data = tf.data.TextLineDataset(train_args.train_en_converted_to_id_path)
self.trg_data = tf.data.TextLineDataset(train_args.train_zh_converted_to_id_path)
# 因为刚读进来是string格式,这里将string改为int,并形成tensor形式。
self.src_data = self.src_data.map(lambda line: tf.string_split([line], delimiter=' ').values)
self.src_data = self.src_data.map(lambda line: tf.string_to_number(line, tf.int32))
self.trg_data = self.trg_data.map(lambda line: tf.string_split([line], delimiter=' ').values)
self.trg_data = self.trg_data.map(lambda line: tf.string_to_number(line, tf.int32))
# 为self.src_data添加一下每个句子的长度
self.src_data = self.src_data.map(lambda x: (x, tf.size(x)))
# 为self.trg_data添加一下decoder的输入。形式为(dec_input, trg_label, trg_length)
# tf.size(x)后面计算loss的时候拿来mask用的以及
# 使用tf.nn.bidirectional_dynamic_rnn()这个函数的时候使用的。
self.trg_data = self.trg_data.map(lambda x: (tf.concat([[1], x[:-1]], axis=0), x, tf.size(x)))
# 将self.src_data和self.trg_data zip起来,方便后面过滤数据。
self.data = tf.data.Dataset.zip((self.src_data, self.trg_data))
# 将句子长度小于1和大于train_args.train_max_sent_len的都去掉。
def filter_according_to_length(src_data, trg_data):
((enc_input, enc_input_size), (dec_input, dec_target_label, dec_target_label_size)) = (src_data, trg_data)
enc_input_flag = tf.logical_and(tf.greater(enc_input_size, 1), tf.less_equal(enc_input_size, train_args.train_max_sent_len))
# decoder的input的长度和decoder的label是一样的,所以这里可以这样用。
dec_input_flag = tf.logical_and(tf.greater(dec_target_label_size, 1), tf.less_equal(dec_target_label_size, train_args.train_max_sent_len))
flag = tf.logical_and(enc_input_flag, dec_input_flag)
return flag
self.data = self.data.filter(filter_according_to_length)
# 由于句子长短不同,我们这里将句子的长度pad成固定的,pad成当前batch里面最长的那个。
# 我们使用0来pad,也就是['<unk>']标志
# 后续计算loss的时候,会根据trg_label的长度来mask掉pad的部分。
# 设置为None的时候,就代表把这个句子pad到当前batch的样本下最长的句子的长度。
# enc_input_size本来就是单个数字,因此不用pad。
self.padded_data = self.data.padded_batch(
batch_size=train_args.train_batch_size,
padded_shapes=((tf.TensorShape([None]), tf.TensorShape([])), (tf.TensorShape([None]), tf.TensorShape([None]), tf.TensorShape([]))))
self.padded_data = self.padded_data.shuffle(10000)
# 创建一个iterator
self.padded_data_iterator = self.padded_data.make_initializable_iterator(
)
self.line = self.padded_data_iterator.get_next()
def iterator_initialization(self, sess):
# 初始化iterator
sess.run(self.padded_data_iterator.initializer)
def next_batch(self, sess):
# 获取一个batch_size的数据
((enc_inp, enc_size), (dec_inp, dec_trg, dec_trg_size)) = sess.run(self.line)
return ((enc_inp, enc_size), (dec_inp, dec_trg, dec_trg_size))
class Model(object):
def __init__(self):
with mt_graph.as_default():
# 创建placeholder
with tf.variable_scope("ipt_placeholder"):
# None因为batch_size在变化,第2个None是因为句长不确定
self.enc_inp = tf.placeholder(tf.int32, shape=[train_args.train_batch_size, None])
# None是代表batch_size
self.enc_inp_size = tf.placeholder(tf.int32, shape=[train_args.train_batch_size])
# None是因为句长不确定
self.dec_inp = tf.placeholder(tf.int32, shape=[train_args.train_batch_size, None])
# None是因为句长不确定
self.dec_label = tf.placeholder(tf.int32, shape=[train_args.train_batch_size, None])
# None是代表batch_size
self.dec_label_size = tf.placeholder(tf.int32, shape=[train_args.train_batch_size])
# 创建源语言的token的embedding和目标语言的token的embedding
with tf.variable_scope("token_embedding"):
# 源语言的token的embedding
self.src_embedding = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.Source_vocab_size, train_args.RNN_hidden_size ], dtype=tf.float32), trainable=True)
# 目标语言的token的embedding
self.trg_embedding = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.Target_vocab_size, train_args.RNN_hidden_size], dtype=tf.float32), trainable=True)
# 全连接层的参数
if train_args.Share_softmax_embedding:
self.full_connect_weights = tf.transpose(self.trg_embedding)
else:
self.full_connect_weights = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.RNN_hidden_size, train_args.Target_vocab_size], dtype=tf.float32), trainable=True)
self.full_connect_biases = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.Target_vocab_size], dtype=tf.float32))
with tf.variable_scope("encoder"):
# 根据输入,得到输入的token的向量
self.src_emb_inp = tf.nn.embedding_lookup(self.src_embedding, self.enc_inp)
# 构建编码器中的双向LSTM
self.enc_forward_lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=train_args.RNN_hidden_size)
self.enc_backward_lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=train_args.RNN_hidden_size)
# 使用bidirectional_dynamic_rnn构造双向RNN网络。
# 把输入的token的向量放入到encoder里面去,得到输出。
# enc_top_outputs包含了前向LSTM和反向LSTM的输出。enc_top_states也一样。
# 我们把前向的LSTM顶层的outputs和反向的LSTM顶层的outputs concat一下,
# 作为attention的输入。
# enc_top_outputs这个tuple,每一个元素的shape都是[batch_size, time_step, hidden_size]
self.enc_top_outputs, self.enc_top_states = tf.nn.bidirectional_dynamic_rnn(
cell_fw=self.enc_forward_lstm_cell,
cell_bw=self.enc_backward_lstm_cell,
inputs=self.src_emb_inp,
sequence_length=self.enc_inp_size,
dtype=tf.float32)
self.enc_outpus = tf.concat([self.enc_top_outputs[0], self.enc_top_outputs[1]], -1)
with tf.variable_scope("decoder"):
# 创建多层decoder。
self.dec_lstm_cell = tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(num_units=train_args.RNN_hidden_size) for _ in range(train_args.num_decoder_layers)])
# 选择BahdanauAttention作为注意力机制。它是使用一层隐藏层的前馈神经网络。
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(
num_units=train_args.RNN_hidden_size,
memory=self.enc_outpus,
memory_sequence_length=self.enc_inp_size)
# 将elf.dec_lstm_cell和attention_mechanism封装成更高级的API
after_attention_cell = tf.contrib.seq2seq.AttentionWrapper(
self.dec_lstm_cell,
attention_mechanism,
attention_layer_size=train_args.RNN_hidden_size)
# 目标token的embedding
self.trg_emb_inp = tf.nn.embedding_lookup(self.trg_embedding, self.dec_inp)
self.dec_top_outpus, self.dec_states = tf.nn.dynamic_rnn(
after_attention_cell,
self.trg_emb_inp,
self.dec_label_size,
dtype=tf.float32)
# 将输出经过一个全连接层
# shape=[None, 1024]
self.outpus = tf.reshape(self.dec_top_outpus, [-1, train_args.RNN_hidden_size])
# shape=[None, 4003]
self.logits = tf.matmul(self.outpus, self.full_connect_weights) + self.full_connect_biases
# tf.nn.sparse_softmax_cross_entropy_with_logits可以不需要将label变成one-hot形式,
# 减少了步骤,大家后续可以自己尝试下。
self.dec_label_reshaped = tf.reshape(self.dec_label, [-1])
# 将self.dec_label_reshaped转换成one-hot的形式
self.dec_label_after_one_hot = tf.one_hot(self.dec_label_reshaped, train_args.Target_vocab_size)
# 计算交叉熵损失函数
self.loss = tf.nn.softmax_cross_entropy_with_logits_v2(labels=self.dec_label_after_one_hot, logits=self.logits)
# 由于我们在构造数据的时候,将没到长度的地方用[UNK]补全了,
# 因此这些地方的loss不能参与计算,我们要将它们mask掉。
# 这里我们设置dtype=tf.float32,意思是让没有mask掉的地方输出为1,
# 被mask掉的地方输出为0,方便我们后面做乘积。
# 如果不设置dtype=tf.float32的话,默认输出是True或者False
self.mask_result = tf.sequence_mask(lengths=self.dec_label_size,
maxlen=tf.shape(
self.dec_inp)[1],
dtype=tf.float32)
self.mask_result = tf.reshape(self.mask_result, [-1])
self.loss = self.loss * self.mask_result
self.loss = tf.reduce_sum(self.loss)
# 计算平均损失
self.per_token_loss = self.loss / tf.reduce_sum(self.mask_result)
# 定义train操作
self.trainable_variables = tf.trainable_variables()
self.optimizer = tf.train.GradientDescentOptimizer(
learning_rate=train_args.learning_rate) # 定义optimizer
# 计算梯度
self.grads = tf.gradients(self.loss / tf.to_float(train_args.train_batch_size), self.trainable_variables)
# 设定一个最大的梯度值,防止梯度爆炸。
self.grads, _ = tf.clip_by_global_norm(self.grads, 7)
# apply 梯度到每个Variable上去。
self.train_op = self.optimizer.apply_gradients(
zip(self.grads, self.trainable_variables))
# 构建global_step,后面保存模型的时候使用
self.global_step = tf.Variable(initial_value=0)
self.global_step_op = tf.add(self.global_step, 1)
self.global_step_assign = tf.assign(self.global_step, self.global_step_op)
self.global_step_per_epoch = tf.Variable(initial_value=1000000)
def train(self, sess, data):
# 训练的操作
((enc_inp, enc_size), (dec_inp, dec_trg, dec_trg_size)) = data
feed = {
self.enc_inp: enc_inp,
self.enc_inp_size: enc_size,
self.dec_inp: dec_inp,
self.dec_label: dec_trg,
self.dec_label_size: dec_trg_size
}
_, per_token_loss, current_global_step = sess.run(
[self.train_op, self.per_token_loss, self.global_step_assign],
feed_dict=feed)
return per_token_loss, current_global_step
data_batch_generation_obj = data_batch_generation()
sess_data = tf.Session(graph=data_graph) # 创建一个图专用的session
nm_model = Model()
session_config = tf.ConfigProto(allow_soft_placement=True) # sesstion的config
session_config.gpu_options.allow_growth = True
# 打开Sesstion,开始训练模型
with tf.Session(graph=mt_graph) as sess: # 创建一个模型的图的sesstion
saver = tf.train.Saver(max_to_keep=5) # 构建saver
data_batch_generation_obj.iterator_initialization(sess_data)
sess.run(tf.global_variables_initializer())
current_epoch = 0
# 从未训练完的模型加载,继续断点训练。
if os.path.exists(train_args.doesnt_finish_model_saved_path_cheackpoint):
restore_path = tf.train.latest_checkpoint(train_args.doesnt_finish_model_saved_path.replace('/model', ''))
saver.restore(sess, restore_path)
current_epoch = sess.run(nm_model.global_step) // sess.run(nm_model.global_step_per_epoch)
print('从未训练完的模型加载-----未训练完的模型已训练完第{}个epoch-----共需要训练{}个epoch'.format(
current_epoch, train_args.max_global_epochs))
global_step_per_epoch_count = 0
while sess.run(nm_model.global_step) < train_args.max_global_epochs * sess.run(nm_model.global_step_per_epoch):
try:
# 这里要传入data的sesstion
data = data_batch_generation_obj.next_batch(sess_data)
if data[0][0].shape[0] == train_args.train_batch_size:
per_token_loss, current_global_step = nm_model.train(sess, data)
print("当前为第{}个epoch-----第{}个global_step-----每个token的loss是-----{}".format(current_epoch, current_global_step, per_token_loss))
global_step_per_epoch_count += 1
except tf.errors.OutOfRangeError as e:
current_epoch += 1
with mt_graph.as_default():
_ = sess.run(tf.assign(nm_model.global_step_per_epoch, global_step_per_epoch_count))
global_step_per_epoch_count = 0
# 如果报tf.errors.OutOfRangeError这个错,说明数据已经被遍历完了,
# 也就是一个epoch结束了。我们重新initialize数据集一下,进行下一个epoch。
data_batch_generation_obj.iterator_initialization(sess_data) # 这里要传入data的sesstion
# 暂时保存下未训练完的模型
if current_epoch % train_args.num_epoch_per_save == 0:
saver.save(sess=sess,
save_path=train_args.doesnt_finish_model_saved_path,
global_step=sess.run(nm_model.global_step))
# 跳出while循环说明整个global_epoch训练完毕,那就保存最终训练好的模型。
saver.save(sess=sess,
save_path=train_args.finish_model_saved_path,
global_step=sess.run(nm_model.global_step))
模型的预测(也就是inference阶段)
模型的预测分为3个阶段。
第1个阶段是构建模型,这一部分代码在class Model(object)这个类里面,这里要注意,预测阶段的class Model(object)和训练阶段的class Model(object)是不一样的。大家注意观察。
第2个阶段就是从保存下来的模型参数中恢复模型参数,其实就是把保存下来的变量及变量的值,在模型中恢复。比如源语言的embedding table,目标语言的embedding table等等。
第3个阶段就是预测阶段。模型加载好后,就可以开始预测了。
代码如下,
#coding=utf-8
'''
Author:Haitaifantuan
'''
import tensorflow as tf
import train_args
import pickle
import nltk
mt_graph = tf.Graph()
class Model(object):
def __init__(self):
with mt_graph.as_default():
# 创建placeholder
with tf.variable_scope("ipt_placeholder"):
self.enc_inp = tf.placeholder(tf.int32, shape=[1, None]) # None是因为句长不确定
self.enc_inp_size = tf.placeholder(tf.int32, shape=[1]) # batch_size是1
# 创建源语言的token的embedding和目标语言的token的embedding
with tf.variable_scope("token_embedding"):
# 源语言的token的embedding。这一层里面的都是变量,resotre的时候会被恢复。
self.src_embedding = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.Source_vocab_size, train_args.RNN_hidden_size], dtype=tf.float32), trainable=True)
# 目标语言的token的embedding
self.trg_embedding = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.Target_vocab_size, train_args.RNN_hidden_size], dtype=tf.float32), trainable=True)
# 全连接层的参数
if train_args.Share_softmax_embedding:
self.full_connect_weights = tf.transpose(self.trg_embedding)
else:
self.full_connect_weights = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.RNN_hidden_size, train_args.Target_vocab_size], dtype=tf.float32), trainable=True)
self.full_connect_biases = tf.Variable(initial_value=tf.truncated_normal(shape=[train_args.Target_vocab_size], dtype=tf.float32))
with tf.variable_scope("encoder"):
# 根据输入,得到输入的token的向量
self.src_emb_inp = tf.nn.embedding_lookup(self.src_embedding, self.enc_inp) # 这是变量,resotre的时候会被恢复。
# 构建编码器中的双向LSTM
self.enc_forward_lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(
num_units=train_args.RNN_hidden_size) # 这是变量,resotre的时候会被恢复。
self.enc_backward_lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(
num_units=train_args.RNN_hidden_size) # 这是变量,resotre的时候会被恢复。
# 使用bidirectional_dynamic_rnn构造双向RNN网络。
# 把输入的token的向量放入到encoder里面去,得到输出。
# enc_top_outputs包含了前向LSTM和反向LSTM的输出。
# enc_top_states也一样。
# 我们把前向的LSTM顶层的outputs和反向的LSTM顶层的outputs concat一下,
# 作为attention的输入。
# enc_top_outputs这个tuple,每一个元素的shape都是[batch_size, time_step, hidden_size]
# 这一层以下两个操作,不是变量。resotre的时候对它们没有影响。
self.enc_top_outputs, self.enc_top_states = tf.nn.bidirectional_dynamic_rnn(
cell_fw=self.enc_forward_lstm_cell,
cell_bw=self.enc_backward_lstm_cell,
inputs=self.src_emb_inp,
sequence_length=self.enc_inp_size,
dtype=tf.float32)
self.enc_outpus = tf.concat(
[self.enc_top_outputs[0], self.enc_top_outputs[1]], -1)
with tf.variable_scope("decoder"):
# 创建多层decoder。这是变量,resotre的时候会被恢复。
self.dec_lstm_cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(num_units=train_args.RNN_hidden_size) for _ in range(train_args.num_decoder_layers)])
# 选择BahdanauAttention作为注意力机制。它是使用一层隐藏层的前馈神经网络。
# 这个操作不是变量。resotre的时候对它们没有影响。
self.attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(
num_units=train_args.RNN_hidden_size,
memory=self.enc_outpus,
memory_sequence_length=self.enc_inp_size)
# 将self.dec_lstm_cell和self.attention_mechanism封装成更高级的API。
# 这个操作不是变量。resotre的时候对它们没有影响。
self.after_attention_cell = tf.contrib.seq2seq.AttentionWrapper(
self.dec_lstm_cell,
self.attention_mechanism,
attention_layer_size=train_args.RNN_hidden_size)
# 这里的tf.variable_scope()一定是"decoder/rnn/attention_wrapper"。
# 否则decoder的参数加载不进来。
# 大家可以在train.py文件和这个文件里面写tf.trainable_variables(),
# 然后打断点查看下变量以及变量域
with tf.variable_scope("decoder/rnn/attention_wrapper"):
# 这里我们使用变长的tf.TensorArray()来放置decoder的输入和输出内容。
self.dec_inp = tf.TensorArray(size=0,
dtype=tf.int32,
dynamic_size=True,
clear_after_read=False)
# 我们先在self.dec_inp里放入[SOS]的id,代表开始标致。
self.dec_inp = self.dec_inp.write(0, 1) # 1代表[SOS]的id
# 我们接下去会使用tf.while_loop()来不断的让decoder输出,
# 因此我们需要提前定义好两个函数。
# 一个是循环条件,另一个是循环体,还有一个是初始变量。
# 我们先来定义初始变量,decoder有状态,输入两个变量,我们还要加一个step_count变量。
# 当step_count超出我们设定的范围的时候,就跳出循环。防止decoder无休止的产生outputs。
init_dec_state = self.after_attention_cell.zero_state(
batch_size=1, dtype=tf.float32)
input_index_ = 0
init_variables = (init_dec_state, self.dec_inp, input_index_)
def continue_loop_condition(state, dec_inp, input_index):
end_flag = tf.not_equal(dec_inp.read(input_index),
2) # 2代表[EOS]的标致
length_flag = tf.less_equal(
input_index,
train_args.test_max_output_sentence_length)
continue_flag = tf.logical_and(end_flag, length_flag)
continue_flag = tf.reduce_all(continue_flag)
return continue_flag
def loop_body_func(state, dec_inp, input_index):
# 读取decoder的输入
inp = [dec_inp.read(input_index)]
inp_embedding = tf.nn.embedding_lookup(
self.trg_embedding, inp)
# 调用call函数,向前走一步
new_output, new_state = self.after_attention_cell.call(
state=state, inputs=inp_embedding)
# 将new_output再做一次映射,映射到字典的维度
# 先将它reshape一下。
new_output = tf.reshape(new_output, [-1, train_args.RNN_hidden_size])
logits = (tf.matmul(new_output, self.full_connect_weights) + self.full_connect_biases)
# 做一次softmax操作
predict_idx = tf.argmax(logits, axis=1, output_type=tf.int32)
# 把infer出的下一个idx加入到dec_inp里面去。
dec_inp = dec_inp.write(input_index + 1, predict_idx[0])
return new_state, dec_inp, input_index + 1
# 执行tf.while_loop(),它就会返回最终的结果
self.final_state_op, self.final_dec_inp_op, self.final_input_index_op = tf.while_loop(
continue_loop_condition, loop_body_func, init_variables)
# 将最后的结果stack()一下
self.final_dec_inp_op = self.final_dec_inp_op.stack()
# 读取英文的token_dictionary
with open(train_args.english_token_id_dictionary_pickle_path, 'rb') as file:
english_token_id_dictionary = pickle.load(file)
# 读取中文的token_dictionary
with open(train_args.chinese_token_id_dictionary_pickle_path, 'rb') as file:
chinese_token_id_dictionary = pickle.load(file)
chinese_id_token_dictionary = {idx: token for token, idx in chinese_token_id_dictionary.items()}
nmt_model = Model() # 创建模型
# sesstion 的config
session_config = tf.ConfigProto(allow_soft_placement=True)
session_config.gpu_options.allow_growth = True
# 打开sesstion,开始进行翻译的预测。
with tf.Session(graph=mt_graph, config=session_config) as sess:
# 构建saver
saver = tf.train.Saver(max_to_keep=5)
sess.run(tf.global_variables_initializer())
restore_path = tf.train.latest_checkpoint(
train_args.finish_model_saved_path.replace('/model', ''))
saver.restore(sess, restore_path)
while True:
sentence = input("请输入英文句子:")
# 将英文句子根据token_dictionary转换成idx的形式
sentence = nltk.word_tokenize(sentence)
# 将输入的英文句子tokenize成token后转换成id形式。
for idx, word in enumerate(sentence):
sentence[idx] = english_token_id_dictionary.get(
word, english_token_id_dictionary['<unk>'])
# 在英文句子的最后添加一个'<eos>'
sentence.append(english_token_id_dictionary['<eos>'])
# 句子的长度
sentence_length = len(sentence)
translation_result = sess.run(nmt_model.final_dec_inp_op,
feed_dict={
nmt_model.enc_inp: [sentence],
nmt_model.enc_inp_size:
[sentence_length]
})
translation_result = list(translation_result)
for index, idx in enumerate(translation_result):
translation_result[index] = chinese_id_token_dictionary[idx]
# 因为返回的屎decoder的输入部分,因此第1位为<sos>,不需要展现出来。
print(''.join(
translation_result[1:]))
模型训练阶段的截图和预测阶段的截图

哈哈~语料还不够多,因此所能展现的效果也就这样了。各位同学可以增加语料试试。说不定翻译的效果会让你惊讶哦。

















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









