









目录
1. 研究背景
2. 一些开源的数据集
3.构建实用的退化模型
4.源码分析
5.资料
一.研究背景
在图像处理领域,超分增强(Super-Resolution,SR)技术一直是一个热门的研究方向, 目标是提升图像的分辨率增加图像的细节和质量,进行SR模型训练需要依赖大量的高分辨率(High-Resolution,HR)图像和与之成对的低分辨率(Low-Resolution,LR)图像, 构建的数据集既要保证分辨率和画质的变化,还要保证图像的保真度,有一些开源的成对数据集例如:DIV2K,Flickr2K等可以作为训练数据集,现实中我们更多的是只有HR图片没有对应的LR图像,如何使用我们自己的HR数据构建对应的LR图像?
传统的退化模型,通过 下采样,加噪以及模糊进行得到对应的LR图片.如下面公式所示,x为HR图片,K为高斯卷积,s为下采样的倍速,n为添加的噪声
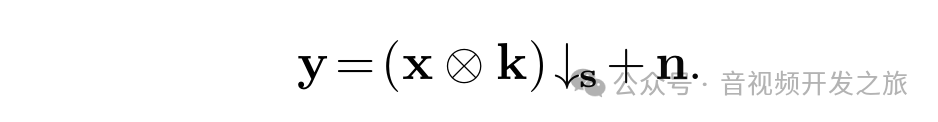
但是现实世界中LR的成因更加多样性和发展,仅仅通过这个模型无法模拟LR图片的成因,导致使用这样的数据集进行训练后的超分增强模型通用性差泛化能力弱
为此BSRGAN(https://github.com/cszn/BSRGAN)研究者设计了一种包含模糊(各向同性和各向异性高斯核)、下采样(最近邻、双线性、双三次插值等) 和噪声退化(高斯噪声、JPEG压缩噪声和相机传感器噪声)且被随机打乱的复杂而实用的退化模型, 后续很多超分增强算法都是基于基于该退化模型进行构建数据集,大大的提升了算法的效果.
二. 一些开源的数据集
DIV2K
数据集地址:https://data.vision.ee.ethz.ch/cvl/DIV2K/
云盘下载地址:https://pan.baidu.com/s/1CFIML6KfQVYGZSNFrhMXmA#list/path=%2F
DIV2K包含1000张2K分辨率图像,其中800训练集,100张验证集,100张测试集。DIV2K除了采用双三次插值(bicubic interplation)方式进行退化外,还提供了unknown退化方式的数据。

Flickr2K
Flickr2K共用包含人物、动物、风景等场景的2650张图像
对应的低分辨率图像也是通过双三性插值bicubic实现
云盘下载地址:https://pan.baidu.com/s/1CFIML6KfQVYGZSNFrhMXmA#list/path=%2F
OST (Outdoor Scenes)
提供了包含7类(天空、水、草、山、建筑、植物、动物)具有丰富纹理信息的10324张HR训练数据和300张测试数据,但没有匹配的LR数据集,https://github.com/cszn/KAIR/blob/master/utils/utils_blindsr.py#bicubic_degradation自行生成对应的双三次插值下采样LQ图片
网盘下载地址:https://pan.baidu.com/s/1neUq5tZ4yTnOEAntZpK_rQ#list/path=%2Fpublic%2FSFTGAN&parentPath=%2Fpublic
三.构建实用的退化模型
BSRGAN研究者设计了一种包含模糊(各向同性和各向异性高斯核)、下采样(最近邻、双线性、双三次插值等) 和噪声退化(高斯噪声、JPEG压缩噪声和相机传感器噪声)且被随机打乱的复杂而实用的退化模型.
如下图所示, 输入HR图像,随机打乱退化序列,最终生成LR图像. 形成盲超分HR-LR数据集对
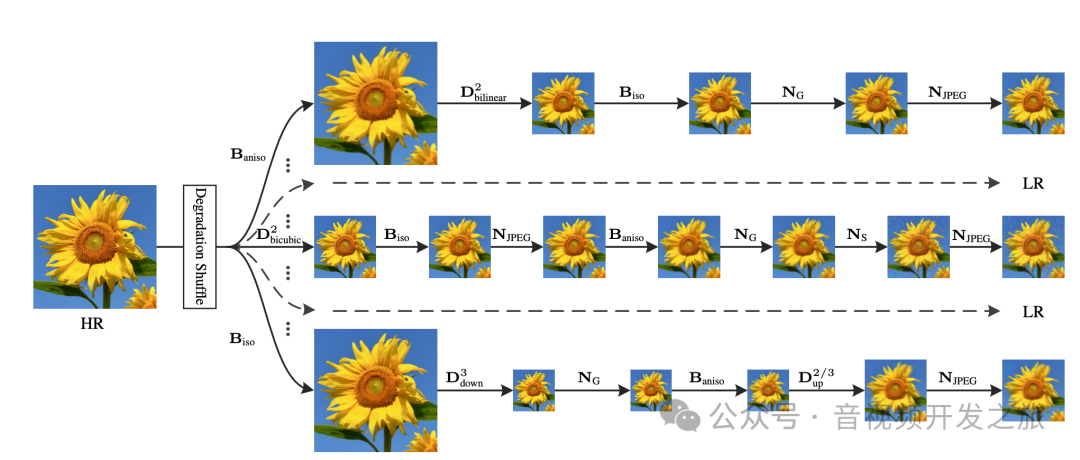
其中涉及很多名词概念,下面我们重点进行解释说明:
各向同性高斯核(Isotropic Gaussian Kernel,B_iso)是指在所有方向上标准差相同的高斯核,这意味着在垂直和水平方向上都有这相同的模糊效果,可用于模拟均匀模糊
各向异性高斯核(Anisotropic Gaussian Kernel,B_aniso)是指在不同方向上标准差不同的高斯核,可以在一个方向上比另一个方向更加模糊,可用于模拟特定方向的运动模糊.
最近邻插值(Nearest Neighbor Interpolation,D_nearest)是最简单的下采样方法,每个像素被其最近的像素值替代,计算简单速度快,但可能会导致图像出现锯齿或者块效应
双线性插值(Bilinear Interpolation,D_bilinear)是一种更平滑的下采样方法,它考虑了原始图像中四个最近像素的影响,根据这四个最近像素的值和目标像素的位置距离,通过线性插值计算出新的像素值,减少了锯齿效应,但仍然在高频细节区域可能产生一些模糊
双三次插值(Bicubic Interpolation,D_bicubi)是一种更高级的下采样,它考虑了原始图像中16个最近像素的影响,通过三次多项式插值计算出新像素的值,相比双线程插值边缘会更加平滑,细节也保留更好,但计算量大.
D_down-up 首先以比例因子 s对图像进行下采样,然后以比例因子 a 进行上采样
JPEG 压缩噪声(N_JPEG),JPEG压缩是图像压缩中一种广泛使用的标准,压缩程度由质量因子(取值范围0-100)决定,质量因子越低压缩率越高,在BSRGAN退化模型中,在[30,95]中进行随机选择.
高斯噪声(N_G),通过添加由均值为零不同标准差的符合高斯分布的噪声来模拟图像在采集、传输或者存储过程中可能遭受的噪声污染,使得生成的LR图像更加接近真实世界的图像.
相机传感器噪声(N_S)通过反向-正向相机图像信号处理实现,用于模拟从RAW传感器数据到最终JPEG或RGB图像的转换过程,这过程包括,颜色插值,白平衡和色彩校正,色彩映射,色彩空间转换和压缩等流程
随机打乱(Degradation shuffle)是该退化模型提出的一种策略,将包含 B_iso(各向同性高斯模糊),B_aniso(各向异性高斯模糊),D_s(比例因子为s的下采样操作),N_G(高斯噪声),N_JPEG(JPEG压缩)和N_S(相机传感器噪声)的退化序列随机打乱.这个随机打乱策略,大幅的扩展了退化空间.
四. 源码分析
具体实现在KAIR/utils/utils_blindsr.py
随机添加7种类型的退化处理
def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=None):"""BSRGAN 退化模型的实现输入:img:输入的高分辨率图像,大小为 H×W×Csf: 缩放因子,默认为 4,用于模拟图像的下采样。lq_patchsize:生成低质量图像块的大小,默认为 72isp_model: 相机图像信号处理(ISP)模型,用于模拟相机传感器噪声输出:img: LQ图像patchhq: 对应的HQ图像的patch,"""isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25sf_ori = sfh1, w1 = img.shape[:2]#进行取模运输,保证图像为sf的倍数img = img.copy()[:h1 - h1 % sf, :w1 - w1 % sf, ...] # mod croph, w = img.shape[:2]hq = img.copy()if sf == 4 and random.random() < scale2_prob: # downsample1if np.random.rand() < 0.5:img = cv2.resize(img, (int(1/2*img.shape[1]), int(1/2*img.shape[0])), interpolation=random.choice([1,2,3]))else:img = util.imresize_np(img, 1/2, True)img = np.clip(img, 0.0, 1.0)sf = 2#随机打乱的退化序列shuffle_order = random.sample(range(7), 7)idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)if idx1 > idx2: # keep downsample3 lastshuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]for i in shuffle_order:if i == 0:#添加B_iso或者B_aniso 进行均匀模糊或者运动模糊处理img = add_blur(img, sf=sf)elif i == 1:img = add_blur(img, sf=sf)elif i == 2:a, b = img.shape[1], img.shape[0]# 对图像进行下采样或者模糊处理,增加退化模型的多样性if random.random() < 0.75:sf1 = random.uniform(1,2*sf)img = cv2.resize(img, (int(1/sf1*img.shape[1]), int(1/sf1*img.shape[0])), interpolation=random.choice([1,2,3]))else:k = fspecial('gaussian', 25, random.uniform(0.1, 0.6*sf))k_shifted = shift_pixel(k, sf)k_shifted = k_shifted/k_shifted.sum() # blur with shifted kernelimg = ndimage.filters.convolve(img, np.expand_dims(k_shifted, axis=2), mode='mirror')img = img[0::sf, 0::sf, ...] # nearest downsamplingimg = np.clip(img, 0.0, 1.0)elif i == 3:#将图像img按照缩放因子sf缩小,同时随机选择插值方法(1:最近邻插值nearest;2:双线性插值bilinear;3:双三次插值bicubic)进行缩放img = cv2.resize(img, (int(1/sf*a), int(1/sf*b)), interpolation=random.choice([1,2,3]))img = np.clip(img, 0.0, 1.0)elif i == 4:# 添加高斯噪声img = add_Gaussian_noise(img, noise_level1=2, noise_level2=25)elif i == 5:# 添加JPEG压缩噪声if random.random() < jpeg_prob:img = add_JPEG_noise(img)elif i == 6:# 添加模拟相机传感器噪声if random.random() < isp_prob and isp_model is not None:with torch.no_grad():img, hq = isp_model.forward(img.copy(), hq)# 最终再添加一层JPEG压缩噪声img = add_JPEG_noise(img)# 随机裁剪pathsize大小的lq-hq图像对img, hq = random_crop(img, hq, sf_ori, lq_patchsize)return img, hq
总结
BSRGAN退化模型,通过随机打乱退化方式(模糊、下采样和噪声等)有效的模拟真实世界中各种复杂且未知的图像退化过程,合成退化的LR图像,形成LR-HR图像对,然后进行盲超分增强模型的训练,从而推动了超分技术在实际应用中的发展,使超分模型更具鲁棒性和泛化能力。
五. 资料
1.退化模型论文:https://arxiv.org/pdf/2103.14006
2. 代码实现:https://github.com/cszn/BSRGAN
3. 超分增强训练代码:https://github.com/cszn/KAIR
4. 最全超分辨率(SR)数据集介绍以及多方法下载链接:https://blog.csdn.net/qq_41554005/article/details/116466156
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流

















 5544
5544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









